 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Interaction Patterns for Debugging: Enhancing Conversational Capabilities of AI-assistants
Feb 09, 2024



The widespread availability of Large Language Models (LLMs) within Integrated Development Environments (IDEs) has led to their speedy adoption. Conversational interactions with LLMs enable programmers to obtain natural language explanations for various software development tasks. However, LLMs often leap to action without sufficient context, giving rise to implicit assumptions and inaccurate responses. Conversations between developers and LLMs are primarily structured as question-answer pairs, where the developer is responsible for asking the the right questions and sustaining conversations across multiple turns. In this paper, we draw inspiration from interaction patterns and conversation analysis -- to design Robin, an enhanced conversational AI-assistant for debugging. Through a within-subjects user study with 12 industry professionals, we find that equipping the LLM to -- (1) leverage the insert expansion interaction pattern, (2) facilitate turn-taking, and (3) utilize debugging workflows -- leads to lowered conversation barriers, effective fault localization, and 5x improvement in bug resolution rates.
Augmented Embeddings for Custom Retrievals
Oct 09, 2023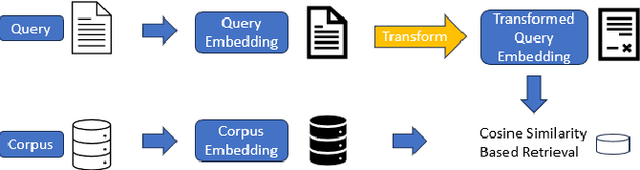



Information retrieval involves selecting artifacts from a corpus that are most relevant to a given search query. The flavor of retrieval typically used in classical applications can be termed as homogeneous and relaxed, where queries and corpus elements are both natural language (NL) utterances (homogeneous) and the goal is to pick most relevant elements from the corpus in the Top-K, where K is large, such as 10, 25, 50 or even 100 (relaxed). Recently, retrieval is being used extensively in preparing prompts for large language models (LLMs) to enable LLMs to perform targeted tasks. These new applications of retrieval are often heterogeneous and strict -- the queries and the corpus contain different kinds of entities, such as NL and code, and there is a need for improving retrieval at Top-K for small values of K, such as K=1 or 3 or 5. Current dense retrieval techniques based on pretrained embeddings provide a general-purpose and powerful approach for retrieval, but they are oblivious to task-specific notions of similarity of heterogeneous artifacts. We introduce Adapted Dense Retrieval, a mechanism to transform embeddings to enable improved task-specific, heterogeneous and strict retrieval. Adapted Dense Retrieval works by learning a low-rank residual adaptation of the pretrained black-box embedding. We empirically validate our approach by showing improvements over the state-of-the-art general-purpose embeddings-based baseline.
GrACE: Generation using Associated Code Edits
May 24, 2023



Developers expend a significant amount of time in editing code for a variety of reasons such as bug fixing or adding new features. Designing effective methods to predict code edits has been an active yet challenging area of research due to the diversity of code edits and the difficulty of capturing the developer intent. In this work, we address these challenges by endowing pre-trained large language models (LLMs) of code with the knowledge of prior, relevant edits. The generative capability of the LLMs helps address the diversity in code changes and conditioning code generation on prior edits helps capture the latent developer intent. We evaluate two well-known LLMs, Codex and CodeT5, in zero-shot and fine-tuning settings respectively. In our experiments with two datasets, the knowledge of prior edits boosts the performance of the LLMs significantly and enables them to generate 29% and 54% more correctly edited code in top-1 suggestions relative to the current state-of-the-art symbolic and neural approaches, respectively.
Overwatch: Learning Patterns in Code Edit Sequences
Jul 25, 2022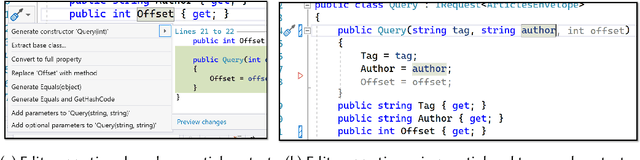
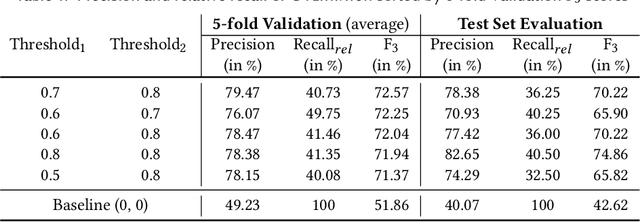


Integrated Development Environments (IDEs) provide tool support to automate many source code editing tasks. Traditionally, IDEs use only the spatial context, i.e., the location where the developer is editing, to generate candidate edit recommendations. However, spatial context alone is often not sufficient to confidently predict the developer's next edit, and thus IDEs generate many suggestions at a location. Therefore, IDEs generally do not actively offer suggestions and instead, the developer is usually required to click on a specific icon or menu and then select from a large list of potential suggestions. As a consequence, developers often miss the opportunity to use the tool support because they are not aware it exists or forget to use it. To better understand common patterns in developer behavior and produce better edit recommendations, we can additionally use the temporal context, i.e., the edits that a developer was recently performing. To enable edit recommendations based on temporal context, we present Overwatch, a novel technique for learning edit sequence patterns from traces of developers' edits performed in an IDE. Our experiments show that Overwatch has 78% precision and that Overwatch not only completed edits when developers missed the opportunity to use the IDE tool support but also predicted new edits that have no tool support in the IDE.