 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Investigation of Robustness in Large Language Models under Tabular Distortions
Jan 08, 2026We investigate how large language models (LLMs) fail when tabular data in an otherwise canonical representation is subjected to semantic and structural distortions. Our findings reveal that LLMs lack an inherent ability to detect and correct subtle distortions in table representations. Only when provided with an explicit prior, via a system prompt, do models partially adjust their reasoning strategies and correct some distortions, though not consistently or completely. To study this phenomenon, we introduce a small, expert-curated dataset that explicitly evaluates LLMs on table question answering (TQA) tasks requiring an additional error-correction step prior to analysis. Our results reveal systematic differences in how LLMs ingest and interpret tabular information under distortion, with even SoTA models such as GPT-5.2 model exhibiting a drop of minimum 22% accuracy under distortion. These findings raise important questions for future research, particularly regarding when and how models should autonomously decide to realign tabular inputs, analogous to human behavior, without relying on explicit prompts or tabular data pre-processing.
Collaboration and Conflict between Humans and Language Models through the Lens of Game Theory
Sep 05, 2025Language models are increasingly deployed in interactive online environments, from personal chat assistants to domain-specific agents, raising questions about their cooperative and competitive behavior in multi-party settings. While prior work has examined language model decision-making in isolated or short-term game-theoretic contexts, these studies often neglect long-horizon interactions, human-model collaboration, and the evolution of behavioral patterns over time. In this paper, we investigate the dynamics of language model behavior in the iterated prisoner's dilemma (IPD), a classical framework for studying cooperation and conflict. We pit model-based agents against a suite of 240 well-established classical strategies in an Axelrod-style tournament and find that language models achieve performance on par with, and in some cases exceeding, the best-known classical strategies. Behavioral analysis reveals that language models exhibit key properties associated with strong cooperative strategies - niceness, provocability, and generosity while also demonstrating rapid adaptability to changes in opponent strategy mid-game. In controlled "strategy switch" experiments, language models detect and respond to shifts within only a few rounds, rivaling or surpassing human adaptability. These results provide the first systematic characterization of long-term cooperative behaviors in language model agents, offering a foundation for future research into their role in more complex, mixed human-AI social environments.
STACKFEED: Structured Textual Actor-Critic Knowledge Base Editing with FeedBack
Oct 14, 2024Large Language Models (LLMs) often generate incorrect or outdated information, especially in low-resource settings or when dealing with private data. To address this, Retrieval-Augmented Generation (RAG) uses external knowledge bases (KBs), but these can also suffer from inaccuracies. We introduce STACKFEED, a novel Structured Textual Actor-Critic Knowledge base editing with FEEDback approach that iteratively refines the KB based on expert feedback using a multi-actor, centralized critic reinforcement learning framework. Each document is assigned to an actor, modeled as a ReACT agent, which performs structured edits based on document-specific targeted instructions from a centralized critic. Experimental results show that STACKFEED significantly improves KB quality and RAG system performance, enhancing accuracy by up to 8% over baselines.
Exploring Interaction Patterns for Debugging: Enhancing Conversational Capabilities of AI-assistants
Feb 09, 2024



The widespread availability of Large Language Models (LLMs) within Integrated Development Environments (IDEs) has led to their speedy adoption. Conversational interactions with LLMs enable programmers to obtain natural language explanations for various software development tasks. However, LLMs often leap to action without sufficient context, giving rise to implicit assumptions and inaccurate responses. Conversations between developers and LLMs are primarily structured as question-answer pairs, where the developer is responsible for asking the the right questions and sustaining conversations across multiple turns. In this paper, we draw inspiration from interaction patterns and conversation analysis -- to design Robin, an enhanced conversational AI-assistant for debugging. Through a within-subjects user study with 12 industry professionals, we find that equipping the LLM to -- (1) leverage the insert expansion interaction pattern, (2) facilitate turn-taking, and (3) utilize debugging workflows -- leads to lowered conversation barriers, effective fault localization, and 5x improvement in bug resolution rates.
GrACE: Generation using Associated Code Edits
May 24, 2023



Developers expend a significant amount of time in editing code for a variety of reasons such as bug fixing or adding new features. Designing effective methods to predict code edits has been an active yet challenging area of research due to the diversity of code edits and the difficulty of capturing the developer intent. In this work, we address these challenges by endowing pre-trained large language models (LLMs) of code with the knowledge of prior, relevant edits. The generative capability of the LLMs helps address the diversity in code changes and conditioning code generation on prior edits helps capture the latent developer intent. We evaluate two well-known LLMs, Codex and CodeT5, in zero-shot and fine-tuning settings respectively. In our experiments with two datasets, the knowledge of prior edits boosts the performance of the LLMs significantly and enables them to generate 29% and 54% more correctly edited code in top-1 suggestions relative to the current state-of-the-art symbolic and neural approaches, respectively.
Overwatch: Learning Patterns in Code Edit Sequences
Jul 25, 2022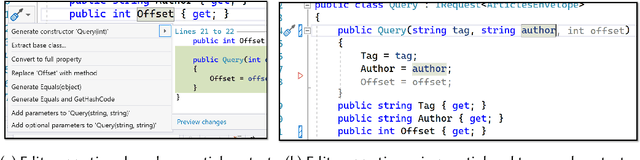


Integrated Development Environments (IDEs) provide tool support to automate many source code editing tasks. Traditionally, IDEs use only the spatial context, i.e., the location where the developer is editing, to generate candidate edit recommendations. However, spatial context alone is often not sufficient to confidently predict the developer's next edit, and thus IDEs generate many suggestions at a location. Therefore, IDEs generally do not actively offer suggestions and instead, the developer is usually required to click on a specific icon or menu and then select from a large list of potential suggestions. As a consequence, developers often miss the opportunity to use the tool support because they are not aware it exists or forget to use it. To better understand common patterns in developer behavior and produce better edit recommendations, we can additionally use the temporal context, i.e., the edits that a developer was recently performing. To enable edit recommendations based on temporal context, we present Overwatch, a novel technique for learning edit sequence patterns from traces of developers' edits performed in an IDE. Our experiments show that Overwatch has 78% precision and that Overwatch not only completed edits when developers missed the opportunity to use the IDE tool support but also predicted new edits that have no tool support in the IDE.
AutoTSG: Learning and Synthesis for Incident Troubleshooting
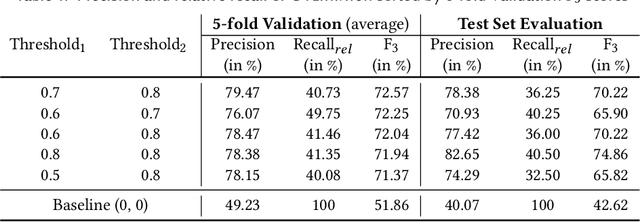
May 26, 2022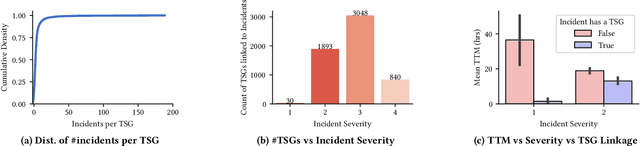


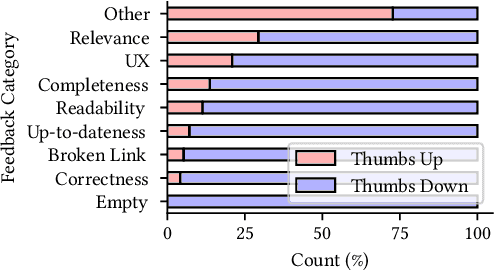
Incident management is a key aspect of operating large-scale cloud services. To aid with faster and efficient resolution of incidents, engineering teams document frequent troubleshooting steps in the form of Troubleshooting Guides (TSGs), to be used by on-call engineers (OCEs). However, TSGs are siloed, unstructured, and often incomplete, requiring developers to manually understand and execute necessary steps. This results in a plethora of issues such as on-call fatigue, reduced productivity, and human errors. In this work, we conduct a large-scale empirical study of over 4K+ TSGs mapped to 1000s of incidents and find that TSGs are widely used and help significantly reduce mitigation efforts. We then analyze feedback on TSGs provided by 400+ OCEs and propose a taxonomy of issues that highlights significant gaps in TSG quality. To alleviate these gaps, we investigate the automation of TSGs and propose AutoTSG -- a novel framework for automation of TSGs to executable workflows by combining machine learning and program synthesis. Our evaluation of AutoTSG on 50 TSGs shows the effectiveness in both identifying TSG statements (accuracy 0.89) and parsing them for execution (precision 0.94 and recall 0.91). Lastly, we survey ten Microsoft engineers and show the importance of TSG automation and the usefulness of AutoTSG.
Landmarks and Regions: A Robust Approach to Data Extraction
Apr 11, 2022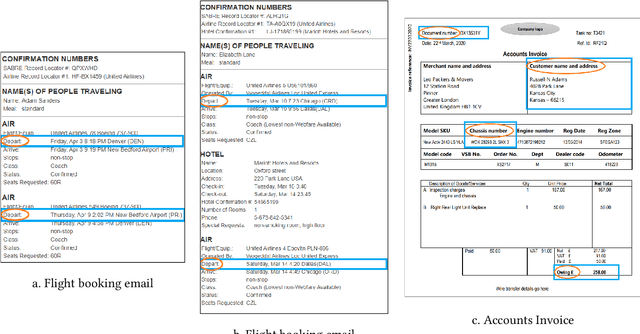
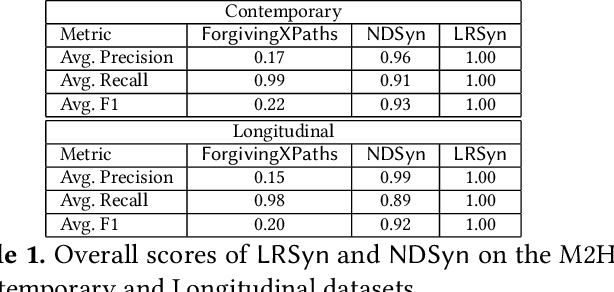
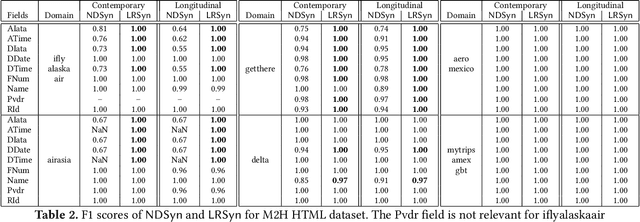
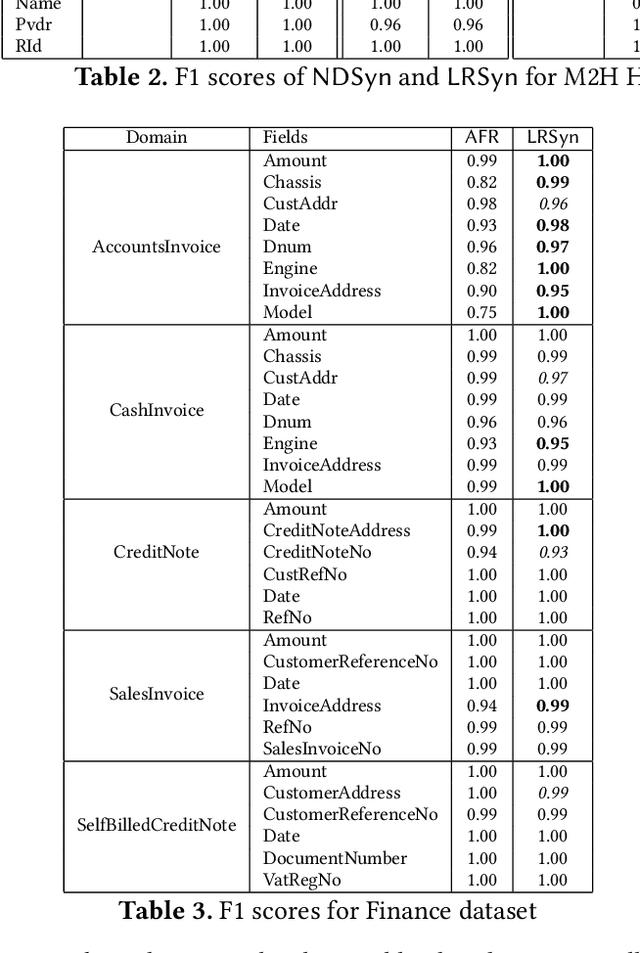
We propose a new approach to extracting data items or field values from semi-structured documents. Examples of such problems include extracting passenger name, departure time and departure airport from a travel itinerary, or extracting price of an item from a purchase receipt. Traditional approaches to data extraction use machine learning or program synthesis to process the whole document to extract the desired fields. Such approaches are not robust to format changes in the document, and the extraction process typically fails even if changes are made to parts of the document that are unrelated to the desired fields of interest. We propose a new approach to data extraction based on the concepts of landmarks and regions. Humans routinely use landmarks in manual processing of documents to zoom in and focus their attention on small regions of interest in the document. Inspired by this human intuition, we use the notion of landmarks in program synthesis to automatically synthesize extraction programs that first extract a small region of interest, and then automatically extract the desired value from the region in a subsequent step. We have implemented our landmark-based extraction approach in a tool LRSyn, and show extensive evaluation on documents in HTML as well as scanned images of invoices and receipts. Our results show that our approach is robust to various types of format changes that routinely happen in real-world settings.
Multi-modal Program Inference: a Marriage of Pre-trainedLanguage Models and Component-based Synthesis
Sep 03, 2021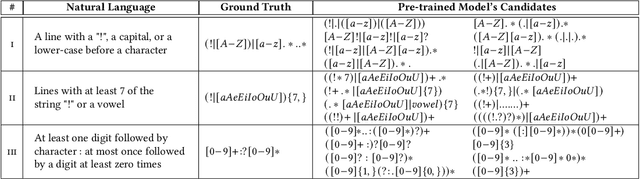


Multi-modal program synthesis refers to the task of synthesizing programs (code) from their specification given in different forms, such as a combination of natural language and examples. Examples provide a precise but incomplete specification, and natural language provides an ambiguous but more "complete" task description. Machine-learned pre-trained models (PTMs) are adept at handling ambiguous natural language, but struggle with generating syntactically and semantically precise code. Program synthesis techniques can generate correct code, often even from incomplete but precise specifications, such as examples, but they are unable to work with the ambiguity of natural languages. We present an approach that combines PTMs with component-based synthesis (CBS): PTMs are used to generate candidates programs from the natural language description of the task, which are then used to guide the CBS procedure to find the program that matches the precise examples-based specification. We use our combination approach to instantiate multi-modal synthesis systems for two programming domains: the domain of regular expressions and the domain of CSS selectors. Our evaluation demonstrates the effectiveness of our domain-agnostic approach in comparison to a state-of-the-art specialized system, and the generality of our approach in providing multi-modal program synthesis from natural language and examples in different programming domains.
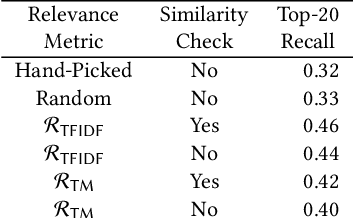
Information-theoretic User Interaction: Significant Inputs for Program Synthesis
Jun 22, 2020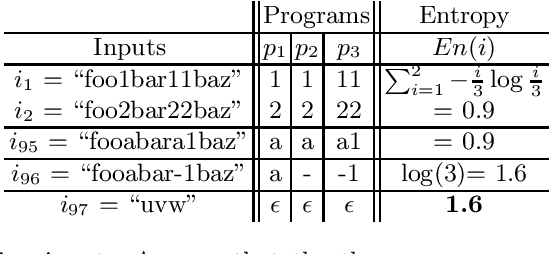
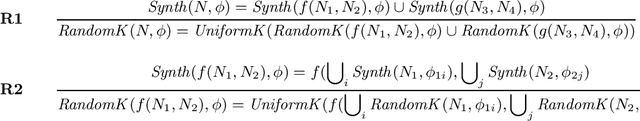
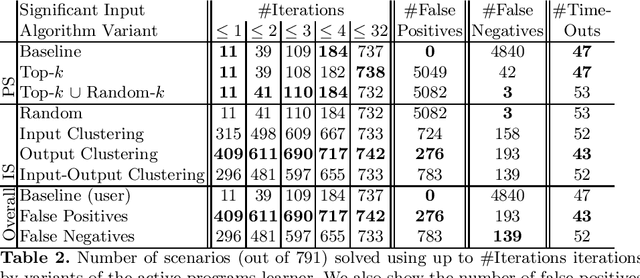
Programming-by-example technologies are being deployed in industrial products for real-time synthesis of various kinds of data transformations. These technologies rely on the user to provide few representative examples of the transformation task. Motivated by the need to find the most pertinent question to ask the user, in this paper, we introduce the {\em significant questions problem}, and show that it is hard in general. We then develop an information-theoretic greedy approach for solving the problem. We justify the greedy algorithm using the conditional entropy result, which informally says that the question that achieves the maximum information gain is the one that we know least about. In the context of interactive program synthesis, we use the above result to develop an {\em{active program learner}} that generates the significant inputs to pose as queries to the user in each iteration. The procedure requires extending a {\em{passive program learner}} to a {\em{sampling program learner}} that is able to sample candidate programs from the set of all consistent programs to enable estimation of information gain. It also uses clustering of inputs based on features in the inputs and the corresponding outputs to sample a small set of candidate significant inputs. Our active learner is able to tradeoff false negatives for false positives and converge in a small number of iterations on a real-world dataset of %around 800 string transformation tasks.