 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
GSO: Challenging Software Optimization Tasks for Evaluating SWE-Agents
May 29, 2025Developing high-performance software is a complex task that requires specialized expertise. We introduce GSO, a benchmark for evaluating language models' capabilities in developing high-performance software. We develop an automated pipeline that generates and executes performance tests to analyze repository commit histories to identify 102 challenging optimization tasks across 10 codebases, spanning diverse domains and programming languages. An agent is provided with a codebase and performance test as a precise specification, and tasked to improve the runtime efficiency, which is measured against the expert developer optimization. Our quantitative evaluation reveals that leading SWE-Agents struggle significantly, achieving less than 5% success rate, with limited improvements even with inference-time scaling. Our qualitative analysis identifies key failure modes, including difficulties with low-level languages, practicing lazy optimization strategies, and challenges in accurately localizing bottlenecks. We release the code and artifacts of our benchmark along with agent trajectories to enable future research.
R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents
Apr 09, 2025Improving open-source models on real-world SWE tasks (solving GITHUB issues) faces two key challenges: 1) scalable curation of execution environments to train these models, and, 2) optimal scaling of test-time compute. We introduce AgentGym, the largest procedurally-curated executable gym environment for training real-world SWE-agents, consisting of more than 8.7K tasks. AgentGym is powered by two main contributions: 1) SYNGEN: a synthetic data curation recipe that enables scalable curation of executable environments using test-generation and back-translation directly from commits, thereby reducing reliance on human-written issues or unit tests. We show that this enables more scalable training leading to pass@1 performance of 34.4% on SWE-Bench Verified benchmark with our 32B model. 2) Hybrid Test-time Scaling: we provide an in-depth analysis of two test-time scaling axes; execution-based and execution-free verifiers, demonstrating that they exhibit complementary strengths and limitations. Test-based verifiers suffer from low distinguishability, while execution-free verifiers are biased and often rely on stylistic features. Surprisingly, we find that while each approach individually saturates around 42-43%, significantly higher gains can be obtained by leveraging their complementary strengths. Overall, our approach achieves 51% on the SWE-Bench Verified benchmark, reflecting a new state-of-the-art for open-weight SWE-agents and for the first time showing competitive performance with proprietary models such as o1, o1-preview and sonnet-3.5-v2 (with tools). We will open-source our environments, models, and agent trajectories.
Challenges and Paths Towards AI for Software Engineering
Mar 28, 2025AI for software engineering has made remarkable progress recently, becoming a notable success within generative AI. Despite this, there are still many challenges that need to be addressed before automated software engineering reaches its full potential. It should be possible to reach high levels of automation where humans can focus on the critical decisions of what to build and how to balance difficult tradeoffs while most routine development effort is automated away. Reaching this level of automation will require substantial research and engineering efforts across academia and industry. In this paper, we aim to discuss progress towards this in a threefold manner. First, we provide a structured taxonomy of concrete tasks in AI for software engineering, emphasizing the many other tasks in software engineering beyond code generation and completion. Second, we outline several key bottlenecks that limit current approaches. Finally, we provide an opinionated list of promising research directions toward making progress on these bottlenecks, hoping to inspire future research in this rapidly maturing field.
AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Clouds
Jan 12, 2025



AI for IT Operations (AIOps) aims to automate complex operational tasks, such as fault localization and root cause analysis, to reduce human workload and minimize customer impact. While traditional DevOps tools and AIOps algorithms often focus on addressing isolated operational tasks, recent advances in Large Language Models (LLMs) and AI agents are revolutionizing AIOps by enabling end-to-end and multitask automation. This paper envisions a future where AI agents autonomously manage operational tasks throughout the entire incident lifecycle, leading to self-healing cloud systems, a paradigm we term AgentOps. Realizing this vision requires a comprehensive framework to guide the design, development, and evaluation of these agents. To this end, we present AIOPSLAB, a framework that not only deploys microservice cloud environments, injects faults, generates workloads, and exports telemetry data but also orchestrates these components and provides interfaces for interacting with and evaluating agents. We discuss the key requirements for such a holistic framework and demonstrate how AIOPSLAB can facilitate the evaluation of next-generation AIOps agents. Through evaluations of state-of-the-art LLM agents within the benchmark created by AIOPSLAB, we provide insights into their capabilities and limitations in handling complex operational tasks in cloud environments.
Syzygy: Dual Code-Test C to (safe) Rust Translation using LLMs and Dynamic Analysis
Dec 18, 2024Despite extensive usage in high-performance, low-level systems programming applications, C is susceptible to vulnerabilities due to manual memory management and unsafe pointer operations. Rust, a modern systems programming language, offers a compelling alternative. Its unique ownership model and type system ensure memory safety without sacrificing performance. In this paper, we present Syzygy, an automated approach to translate C to safe Rust. Our technique uses a synergistic combination of LLM-driven code and test translation guided by dynamic-analysis-generated execution information. This paired translation runs incrementally in a loop over the program in dependency order of the code elements while maintaining per-step correctness. Our approach exposes novel insights on combining the strengths of LLMs and dynamic analysis in the context of scaling and combining code generation with testing. We apply our approach to successfully translate Zopfli, a high-performance compression library with ~3000 lines of code and 98 functions. We validate the translation by testing equivalence with the source C program on a set of inputs. To our knowledge, this is the largest automated and test-validated C to safe Rust code translation achieved so far.
Building AI Agents for Autonomous Clouds: Challenges and Design Principles
Jul 16, 2024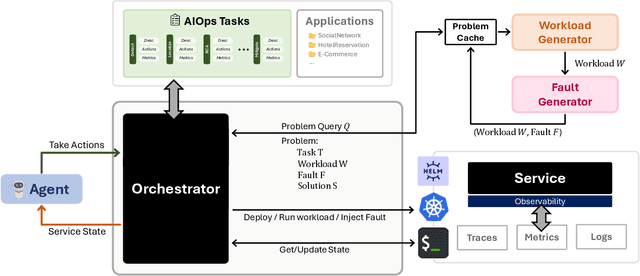


The rapid growth in the use of Large Language Models (LLMs) and AI Agents as part of software development and deployment is revolutionizing the information technology landscape. While code generation receives significant attention, a higher-impact application lies in using AI agents for operational resilience of cloud services, which currently require significant human effort and domain knowledge. There is a growing interest in AI for IT Operations (AIOps) which aims to automate complex operational tasks, like fault localization and root cause analysis, thereby reducing human intervention and customer impact. However, achieving the vision of autonomous and self-healing clouds though AIOps is hampered by the lack of standardized frameworks for building, evaluating, and improving AIOps agents. This vision paper lays the groundwork for such a framework by first framing the requirements and then discussing design decisions that satisfy them. We also propose AIOpsLab, a prototype implementation leveraging agent-cloud-interface that orchestrates an application, injects real-time faults using chaos engineering, and interfaces with an agent to localize and resolve the faults. We report promising results and lay the groundwork to build a modular and robust framework for building, evaluating, and improving agents for autonomous clouds.
CodeScholar: Growing Idiomatic Code Examples
Dec 23, 2023Programmers often search for usage examples for API methods. A tool that could generate realistic, idiomatic, and contextual usage examples for one or more APIs would be immensely beneficial to developers. Such a tool would relieve the need for a deep understanding of the API landscape, augment existing documentation, and help discover interactions among APIs. We present CodeScholar, a tool that generates idiomatic code examples demonstrating the common usage of API methods. It includes a novel neural-guided search technique over graphs that grows the query APIs into idiomatic code examples. Our user study demonstrates that in 70% of cases, developers prefer CodeScholar generated examples over state-of-the-art large language models (LLM) like GPT3.5. We quantitatively evaluate 60 single and 25 multi-API queries from 6 popular Python libraries and show that across-the-board CodeScholar generates more realistic, diverse, and concise examples. In addition, we show that CodeScholar not only helps developers but also LLM-powered programming assistants generate correct code in a program synthesis setting.
DSPy Assertions: Computational Constraints for Self-Refining Language Model Pipelines
Dec 20, 2023Chaining language model (LM) calls as composable modules is fueling a new powerful way of programming. However, ensuring that LMs adhere to important constraints remains a key challenge, one often addressed with heuristic "prompt engineering". We introduce LM Assertions, a new programming construct for expressing computational constraints that LMs should satisfy. We integrate our constructs into the recent DSPy programming model for LMs, and present new strategies that allow DSPy to compile programs with arbitrary LM Assertions into systems that are more reliable and more accurate. In DSPy, LM Assertions can be integrated at compile time, via automatic prompt optimization, and/or at inference time, via automatic selfrefinement and backtracking. We report on two early case studies for complex question answering (QA), in which the LM program must iteratively retrieve information in multiple hops and synthesize a long-form answer with citations. We find that LM Assertions improve not only compliance with imposed rules and guidelines but also enhance downstream task performance, delivering intrinsic and extrinsic gains up to 35.7% and 13.3%, respectively. Our reference implementation of LM Assertions is integrated into DSPy at https://github.com/stanfordnlp/dspy
AutoTSG: Learning and Synthesis for Incident Troubleshooting
May 26, 2022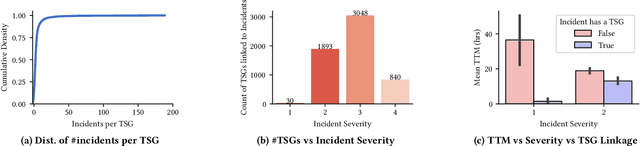


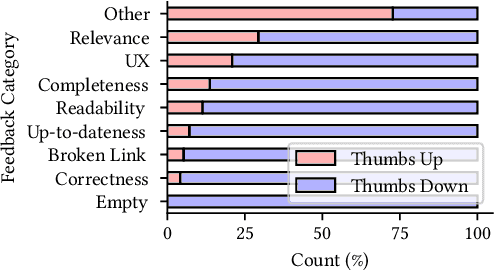
Incident management is a key aspect of operating large-scale cloud services. To aid with faster and efficient resolution of incidents, engineering teams document frequent troubleshooting steps in the form of Troubleshooting Guides (TSGs), to be used by on-call engineers (OCEs). However, TSGs are siloed, unstructured, and often incomplete, requiring developers to manually understand and execute necessary steps. This results in a plethora of issues such as on-call fatigue, reduced productivity, and human errors. In this work, we conduct a large-scale empirical study of over 4K+ TSGs mapped to 1000s of incidents and find that TSGs are widely used and help significantly reduce mitigation efforts. We then analyze feedback on TSGs provided by 400+ OCEs and propose a taxonomy of issues that highlights significant gaps in TSG quality. To alleviate these gaps, we investigate the automation of TSGs and propose AutoTSG -- a novel framework for automation of TSGs to executable workflows by combining machine learning and program synthesis. Our evaluation of AutoTSG on 50 TSGs shows the effectiveness in both identifying TSG statements (accuracy 0.89) and parsing them for execution (precision 0.94 and recall 0.91). Lastly, we survey ten Microsoft engineers and show the importance of TSG automation and the usefulness of AutoTSG.