 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding AI Agents for Autonomous Clouds: Challenges and Design Principles
Jul 16, 2024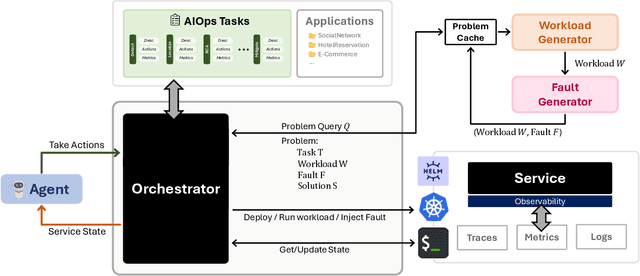


The rapid growth in the use of Large Language Models (LLMs) and AI Agents as part of software development and deployment is revolutionizing the information technology landscape. While code generation receives significant attention, a higher-impact application lies in using AI agents for operational resilience of cloud services, which currently require significant human effort and domain knowledge. There is a growing interest in AI for IT Operations (AIOps) which aims to automate complex operational tasks, like fault localization and root cause analysis, thereby reducing human intervention and customer impact. However, achieving the vision of autonomous and self-healing clouds though AIOps is hampered by the lack of standardized frameworks for building, evaluating, and improving AIOps agents. This vision paper lays the groundwork for such a framework by first framing the requirements and then discussing design decisions that satisfy them. We also propose AIOpsLab, a prototype implementation leveraging agent-cloud-interface that orchestrates an application, injects real-time faults using chaos engineering, and interfaces with an agent to localize and resolve the faults. We report promising results and lay the groundwork to build a modular and robust framework for building, evaluating, and improving agents for autonomous clouds.
Exploring LLM-based Agents for Root Cause Analysis
Mar 07, 2024



The growing complexity of cloud based software systems has resulted in incident management becoming an integral part of the software development lifecycle. Root cause analysis (RCA), a critical part of the incident management process, is a demanding task for on-call engineers, requiring deep domain knowledge and extensive experience with a team's specific services. Automation of RCA can result in significant savings of time, and ease the burden of incident management on on-call engineers. Recently, researchers have utilized Large Language Models (LLMs) to perform RCA, and have demonstrated promising results. However, these approaches are not able to dynamically collect additional diagnostic information such as incident related logs, metrics or databases, severely restricting their ability to diagnose root causes. In this work, we explore the use of LLM based agents for RCA to address this limitation. We present a thorough empirical evaluation of a ReAct agent equipped with retrieval tools, on an out-of-distribution dataset of production incidents collected at Microsoft. Results show that ReAct performs competitively with strong retrieval and reasoning baselines, but with highly increased factual accuracy. We then extend this evaluation by incorporating discussions associated with incident reports as additional inputs for the models, which surprisingly does not yield significant performance improvements. Lastly, we conduct a case study with a team at Microsoft to equip the ReAct agent with tools that give it access to external diagnostic services that are used by the team for manual RCA. Our results show how agents can overcome the limitations of prior work, and practical considerations for implementing such a system in practice.
PACE-LM: Prompting and Augmentation for Calibrated Confidence Estimation with GPT-4 in Cloud Incident Root Cause Analysis
Sep 29, 2023


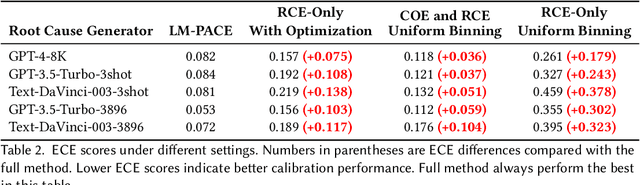
Major cloud providers have employed advanced AI-based solutions like large language models to aid humans in identifying the root causes of cloud incidents. Despite the growing prevalence of AI-driven assistants in the root cause analysis process, their effectiveness in assisting on-call engineers is constrained by low accuracy due to the intrinsic difficulty of the task, a propensity for LLM-based approaches to hallucinate, and difficulties in distinguishing these well-disguised hallucinations. To address this challenge, we propose to perform confidence estimation for the predictions to help on-call engineers make decisions on whether to adopt the model prediction. Considering the black-box nature of many LLM-based root cause predictors, fine-tuning or temperature-scaling-based approaches are inapplicable. We therefore design an innovative confidence estimation framework based on prompting retrieval-augmented large language models (LLMs) that demand a minimal amount of information from the root cause predictor. This approach consists of two scoring phases: the LLM-based confidence estimator first evaluates its confidence in making judgments in the face of the current incident that reflects its ``grounded-ness" level in reference data, then rates the root cause prediction based on historical references. An optimization step combines these two scores for a final confidence assignment. We show that our method is able to produce calibrated confidence estimates for predicted root causes, validate the usefulness of retrieved historical data and the prompting strategy as well as the generalizability across different root cause prediction models. Our study takes an important move towards reliably and effectively embedding LLMs into cloud incident management systems.