 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebXSkill: Skill Learning for Autonomous Web Agents
Apr 14, 2026Autonomous web agents powered by large language models (LLMs) have shown promise in completing complex browser tasks, yet they still struggle with long-horizon workflows. A key bottleneck is the grounding gap in existing skill formulations: textual workflow skills provide natural language guidance but cannot be directly executed, while code-based skills are executable but opaque to the agent, offering no step-level understanding for error recovery or adaptation. We introduce WebXSkill, a framework that bridges this gap with executable skills, each pairing a parameterized action program with step-level natural language guidance, enabling both direct execution and agent-driven adaptation. WebXSkill operates in three stages: skill extraction mines reusable action subsequences from readily available synthetic agent trajectories and abstracts them into parameterized skills, skill organization indexes skills into a URL-based graph for context-aware retrieval, and skill deployment exposes two complementary modes, grounded mode for fully automated multi-step execution and guided mode where skills serve as step-by-step instructions that the agent follows with its native planning. On WebArena and WebVoyager, WebXSkill improves task success rate by up to 9.8 and 12.9 points over the baseline, respectively, demonstrating the effectiveness of executable skills for web agents. The code is publicly available at https://github.com/aiming-lab/WebXSkill.
ActionNex: A Virtual Outage Manager for Cloud
Apr 03, 2026Outage management in large-scale cloud operations remains heavily manual, requiring rapid triage, cross-team coordination, and experience-driven decisions under partial observability. We present \textbf{ActionNex}, a production-grade agentic system that supports end-to-end outage assistance, including real-time updates, knowledge distillation, and role- and stage-conditioned next-best action recommendations. ActionNex ingests multimodal operational signals (e.g., outage content, telemetry, and human communications) and compresses them into critical events that represent meaningful state transitions. It couples this perception layer with a hierarchical memory subsystem: long-term Key-Condition-Action (KCA) knowledge distilled from playbooks and historical executions, episodic memory of prior outages, and working memory of the live context. A reasoning agent aligns current critical events to preconditions, retrieves relevant memories, and generates actionable recommendations; executed human actions serve as an implicit feedback signal to enable continual self-evolution in a human-agent hybrid system. We evaluate ActionNex on eight real Azure outages (8M tokens, 4,000 critical events) using two complementary ground-truth action sets, achieving 71.4\% precision and 52.8-54.8\% recall. The system has been piloted in production and has received positive early feedback.
AutoAdapt: An Automated Domain Adaptation Framework for LLMs
Mar 09, 2026Large language models (LLMs) excel in open domains but struggle in specialized settings with limited data and evolving knowledge. Existing domain adaptation practices rely heavily on manual trial-and-error processes, incur significant hyperparameter complexity, and are highly sensitive to data and user preferences, all under the high cost of LLM training. Moreover, the interactions and transferability of hyperparameter choices across models/domains remain poorly understood, making adaptation gains uncertain even with substantial effort. To solve these challenges, we present AutoAdapt, a novel end-to-end automated framework for efficient and reliable LLM domain adaptation. AutoAdapt leverages curated knowledge bases from literature and open-source resources to reduce expert intervention. To narrow the search space, we design a novel multi-agent debating system in which proposal and critic agents iteratively interact to align user intent and incorporate data signals and best practices into the planning process. To optimize hyperparameters under tight budgets, we propose AutoRefine, a novel LLM-based surrogate that replaces costly black-box search. Across 10 tasks, AutoAdapt achieves a 25% average relative accuracy improvement over state-of-the-art Automated Machine Learning baselines with minimal overhead.
Provable and Practical In-Context Policy Optimization for Self-Improvement
Mar 02, 2026We study test-time scaling, where a model improves its answer through multi-round self-reflection at inference. We introduce In-Context Policy Optimization (ICPO), in which an agent optimizes its response in context using self-assessed or externally observed rewards without modifying its parameters. To explain this ICPO process, we theoretically show that with sufficient pretraining under a novel Fisher-weighted logit-matching objective, a single-layer linear self-attention model can provably imitate policy-optimization algorithm for linear bandits. Building on this theory, we propose Minimum-Entropy ICPO (ME-ICPO), a practical algorithm that iteratively uses its response and self-assessed reward to refine its response in-context at inference time. By selecting the responses and their rewards with minimum entropy, ME-ICPO ensures the robustness of the self-assessed rewards via majority voting. Across standard mathematical reasoning tasks, ME-ICPO attains competitive, top-tier performance while keeping inference costs affordable compared with other inference-time algorithms. Overall, ICPO provides a principled understanding of self-reflection in LLMs and yields practical benefits for test-time scaling for mathematical reasoning.
Memora: A Harmonic Memory Representation Balancing Abstraction and Specificity
Feb 03, 2026Agent memory systems must accommodate continuously growing information while supporting efficient, context-aware retrieval for downstream tasks. Abstraction is essential for scaling agent memory, yet it often comes at the cost of specificity, obscuring the fine-grained details required for effective reasoning. We introduce Memora, a harmonic memory representation that structurally balances abstraction and specificity. Memora organizes information via its primary abstractions that index concrete memory values and consolidate related updates into unified memory entries, while cue anchors expand retrieval access across diverse aspects of the memory and connect related memories. Building on this structure, we employ a retrieval policy that actively exploits these memory connections to retrieve relevant information beyond direct semantic similarity. Theoretically, we show that standard Retrieval-Augmented Generation (RAG) and Knowledge Graph (KG)-based memory systems emerge as special cases of our framework. Empirically, Memora establishes a new state-of-the-art on the LoCoMo and LongMemEval benchmarks, demonstrating better retrieval relevance and reasoning effectiveness as memory scales.
AgentRx: Diagnosing AI Agent Failures from Execution Trajectories
Feb 02, 2026AI agents often fail in ways that are difficult to localize because executions are probabilistic, long-horizon, multi-agent, and mediated by noisy tool outputs. We address this gap by manually annotating failed agent runs and release a novel benchmark of 115 failed trajectories spanning structured API workflows, incident management, and open-ended web/file tasks. Each trajectory is annotated with a critical failure step and a category from a grounded-theory derived, cross-domain failure taxonomy. To mitigate the human cost of failure attribution, we present AGENTRX, an automated domain-agnostic diagnostic framework that pinpoints the critical failure step in a failed agent trajectory. It synthesizes constraints, evaluates them step-by-step, and produces an auditable validation log of constraint violations with associated evidence; an LLM-based judge uses this log to localize the critical step and category. Our framework improves step localization and failure attribution over existing baselines across three domains.
Your Self-Play Algorithm is Secretly an Adversarial Imitator: Understanding LLM Self-Play through the Lens of Imitation Learning
Feb 01, 2026Self-play post-training methods has emerged as an effective approach for finetuning large language models and turn the weak language model into strong language model without preference data. However, the theoretical foundations for self-play finetuning remain underexplored. In this work, we tackle this by connecting self-play finetuning with adversarial imitation learning by formulating finetuning procedure as a min-max game between the model and a regularized implicit reward player parameterized by the model itself. This perspective unifies self-play imitation and general preference alignment within a common framework. Under this formulation, we present a game-theoretic analysis showing that the self-play finetuning will converge to it's equilibrium. Guided by this theoretical formulation, we propose a new self-play imitation finetuning algorithm based on the $χ^2$-divergence variational objective with bounded rewards and improved stability. Experiments on various of language model finetuning tasks demonstrate consistent improvements over existing self-play methods and validate our theoretical insights.
Adapting Web Agents with Synthetic Supervision
Nov 08, 2025Web agents struggle to adapt to new websites due to the scarcity of environment specific tasks and demonstrations. Recent works have explored synthetic data generation to address this challenge, however, they suffer from data quality issues where synthesized tasks contain hallucinations that cannot be executed, and collected trajectories are noisy with redundant or misaligned actions. In this paper, we propose SynthAgent, a fully synthetic supervision framework that aims at improving synthetic data quality via dual refinement of both tasks and trajectories. Our approach begins by synthesizing diverse tasks through categorized exploration of web elements, ensuring efficient coverage of the target environment. During trajectory collection, we refine tasks when conflicts with actual observations are detected, mitigating hallucinations while maintaining task consistency. After collection, we conduct trajectory refinement with a global context to mitigate potential noise or misalignments. Finally, we fine-tune open-source web agents on the refined synthetic data to adapt them to the target environment. Experimental results demonstrate that SynthAgent outperforms existing synthetic data methods, validating the importance of high-quality synthetic supervision. The code will be publicly available at https://github.com/aiming-lab/SynthAgent.
Attention Enhanced Entity Recommendation for Intelligent Monitoring in Cloud Systems
Oct 23, 2025In this paper, we present DiRecGNN, an attention-enhanced entity recommendation framework for monitoring cloud services at Microsoft. We provide insights on the usefulness of this feature as perceived by the cloud service owners and lessons learned from deployment. Specifically, we introduce the problem of recommending the optimal subset of attributes (dimensions) that should be tracked by an automated watchdog (monitor) for cloud services. To begin, we construct the monitor heterogeneous graph at production-scale. The interaction dynamics of these entities are often characterized by limited structural and engagement information, resulting in inferior performance of state-of-the-art approaches. Moreover, traditional methods fail to capture the dependencies between entities spanning a long range due to their homophilic nature. Therefore, we propose an attention-enhanced entity ranking model inspired by transformer architectures. Our model utilizes a multi-head attention mechanism to focus on heterogeneous neighbors and their attributes, and further attends to paths sampled using random walks to capture long-range dependencies. We also employ multi-faceted loss functions to optimize for relevant recommendations while respecting the inherent sparsity of the data. Empirical evaluations demonstrate significant improvements over existing methods, with our model achieving a 43.1% increase in MRR. Furthermore, product teams who consumed these features perceive the feature as useful and rated it 4.5 out of 5.
Anyprefer: An Agentic Framework for Preference Data Synthesis
Apr 27, 2025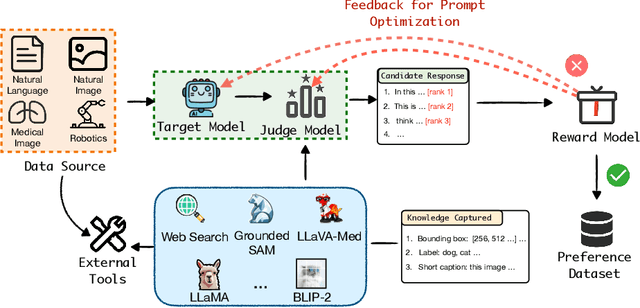
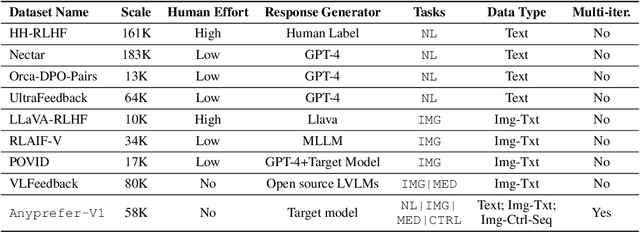
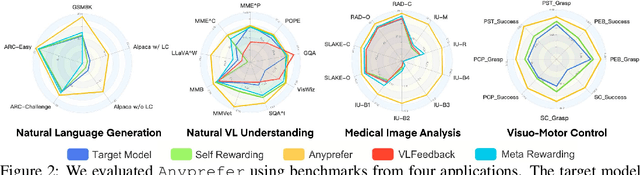
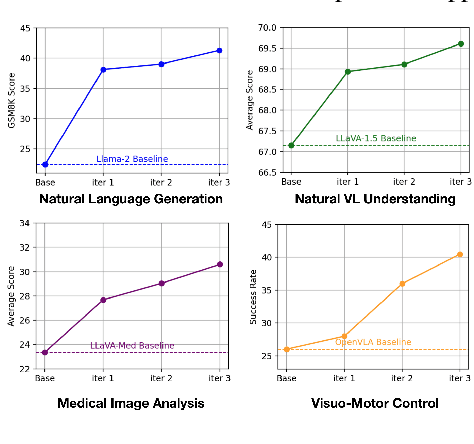
High-quality preference data is essential for aligning foundation models with human values through preference learning. However, manual annotation of such data is often time-consuming and costly. Recent methods often adopt a self-rewarding approach, where the target model generates and annotates its own preference data, but this can lead to inaccuracies since the reward model shares weights with the target model, thereby amplifying inherent biases. To address these issues, we propose Anyprefer, a framework designed to synthesize high-quality preference data for aligning the target model. Anyprefer frames the data synthesis process as a cooperative two-player Markov Game, where the target model and the judge model collaborate together. Here, a series of external tools are introduced to assist the judge model in accurately rewarding the target model's responses, mitigating biases in the rewarding process. In addition, a feedback mechanism is introduced to optimize prompts for both models, enhancing collaboration and improving data quality. The synthesized data is compiled into a new preference dataset, Anyprefer-V1, consisting of 58K high-quality preference pairs. Extensive experiments show that Anyprefer significantly improves model alignment performance across four main applications, covering 21 datasets, achieving average improvements of 18.55% in five natural language generation datasets, 3.66% in nine vision-language understanding datasets, 30.05% in three medical image analysis datasets, and 16.00% in four visuo-motor control tasks.