 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevati: Transparent GPU-Free Time-Warp Emulation for LLM Serving
Jan 01, 2026Deploying LLMs efficiently requires testing hundreds of serving configurations, but evaluating each one on a GPU cluster takes hours and costs thousands of dollars. Discrete-event simulators are faster and cheaper, but they require re-implementing the serving system's control logic -- a burden that compounds as frameworks evolve. We present Revati, a time-warp emulator that enables performance modeling by directly executing real serving system code at simulation-like speed. The system intercepts CUDA API calls to virtualize device management, allowing serving frameworks to run without physical GPUs. Instead of executing GPU kernels, it performs time jumps -- fast-forwarding virtual time by predicted kernel durations. We propose a coordination protocol that synchronizes these jumps across distributed processes while preserving causality. On vLLM and SGLang, Revati achieves less than 5% prediction error across multiple models and parallelism configurations, while running 5-17x faster than real GPU execution.
Time Warp: The Gap Between Developers' Ideal vs Actual Workweeks in an AI-Driven Era
Feb 21, 2025

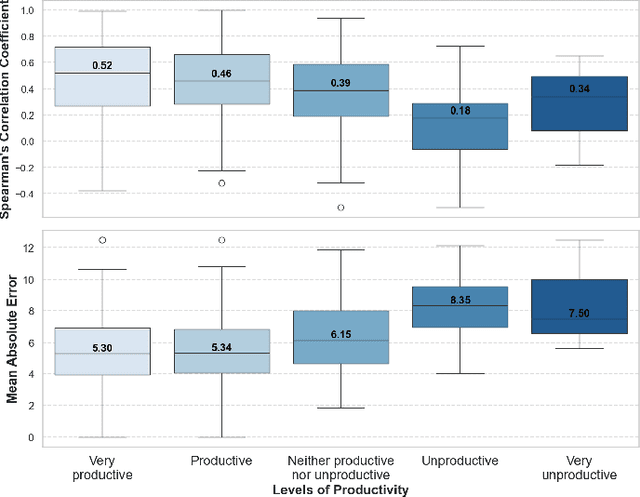

Software developers balance a variety of different tasks in a workweek, yet the allocation of time often differs from what they consider ideal. Identifying and addressing these deviations is crucial for organizations aiming to enhance the productivity and well-being of the developers. In this paper, we present the findings from a survey of 484 software developers at Microsoft, which aims to identify the key differences between how developers would like to allocate their time during an ideal workweek versus their actual workweek. Our analysis reveals significant deviations between a developer's ideal workweek and their actual workweek, with a clear correlation: as the gap between these two workweeks widens, we observe a decline in both productivity and satisfaction. By examining these deviations in specific activities, we assess their direct impact on the developers' satisfaction and productivity. Additionally, given the growing adoption of AI tools in software engineering, both in the industry and academia, we identify specific tasks and areas that could be strong candidates for automation. In this paper, we make three key contributions: 1) We quantify the impact of workweek deviations on developer productivity and satisfaction 2) We identify individual tasks that disproportionately affect satisfaction and productivity 3) We provide actual data-driven insights to guide future AI automation efforts in software engineering, aligning them with the developers' requirements and ideal workflows for maximizing their productivity and satisfaction.
Prompt-Propose-Verify: A Reliable Hand-Object-Interaction Data Generation Framework using Foundational Models
Dec 23, 2023Diffusion models when conditioned on text prompts, generate realistic-looking images with intricate details. But most of these pre-trained models fail to generate accurate images when it comes to human features like hands, teeth, etc. We hypothesize that this inability of diffusion models can be overcome through well-annotated good-quality data. In this paper, we look specifically into improving the hand-object-interaction image generation using diffusion models. We collect a well annotated hand-object interaction synthetic dataset curated using Prompt-Propose-Verify framework and finetune a stable diffusion model on it. We evaluate the image-text dataset on qualitative and quantitative metrics like CLIPScore, ImageReward, Fedility, and alignment and show considerably better performance over the current state-of-the-art benchmarks.