 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAME: A Trustworthy Test-Time Evolution of Agent Memory with Systematic Benchmarking
Feb 03, 2026Test-time evolution of agent memory serves as a pivotal paradigm for achieving AGI by bolstering complex reasoning through experience accumulation. However, even during benign task evolution, agent safety alignment remains vulnerable-a phenomenon known as Agent Memory Misevolution. To evaluate this phenomenon, we construct the Trust-Memevo benchmark to assess multi-dimensional trustworthiness during benign task evolution, revealing an overall decline in trustworthiness across various task domains and evaluation settings. To address this issue, we propose TAME, a dual-memory evolutionary framework that separately evolves executor memory to improve task performance by distilling generalizable methodologies, and evaluator memory to refine assessments of both safety and task utility based on historical feedback. Through a closed loop of memory filtering, draft generation, trustworthy refinement, execution, and dual-track memory updating, TAME preserves trustworthiness without sacrificing utility. Experiments demonstrate that TAME mitigates misevolution, achieving a joint improvement in both trustworthiness and task performance.
Training LLMs with LogicReward for Faithful and Rigorous Reasoning
Dec 20, 2025
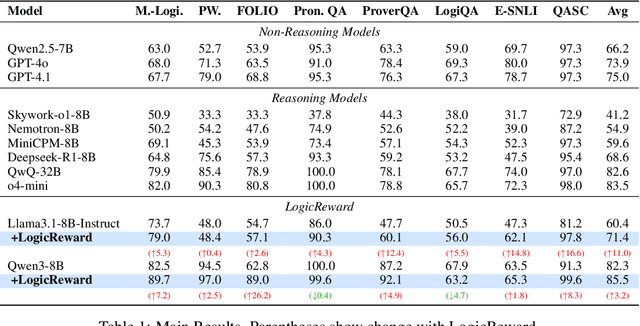
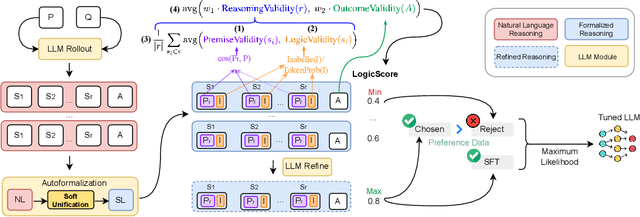

Although LLMs exhibit strong reasoning capabilities, existing training methods largely depend on outcome-based feedback, which can produce correct answers with flawed reasoning. Prior work introduces supervision on intermediate steps but still lacks guarantees of logical soundness, which is crucial in high-stakes scenarios where logical consistency is paramount. To address this, we propose LogicReward, a novel reward system that guides model training by enforcing step-level logical correctness with a theorem prover. We further introduce Autoformalization with Soft Unification, which reduces natural language ambiguity and improves formalization quality, enabling more effective use of the theorem prover. An 8B model trained on data constructed with LogicReward surpasses GPT-4o and o4-mini by 11.6\% and 2\% on natural language inference and logical reasoning tasks with simple training procedures. Further analysis shows that LogicReward enhances reasoning faithfulness, improves generalizability to unseen tasks such as math and commonsense reasoning, and provides a reliable reward signal even without ground-truth labels. We will release all data and code at https://llm-symbol.github.io/LogicReward.
UniVA: Universal Video Agent towards Open-Source Next-Generation Video Generalist
Nov 11, 2025While specialized AI models excel at isolated video tasks like generation or understanding, real-world applications demand complex, iterative workflows that combine these capabilities. To bridge this gap, we introduce UniVA, an open-source, omni-capable multi-agent framework for next-generation video generalists that unifies video understanding, segmentation, editing, and generation into cohesive workflows. UniVA employs a Plan-and-Act dual-agent architecture that drives a highly automated and proactive workflow: a planner agent interprets user intentions and decomposes them into structured video-processing steps, while executor agents execute these through modular, MCP-based tool servers (for analysis, generation, editing, tracking, etc.). Through a hierarchical multi-level memory (global knowledge, task context, and user-specific preferences), UniVA sustains long-horizon reasoning, contextual continuity, and inter-agent communication, enabling interactive and self-reflective video creation with full traceability. This design enables iterative and any-conditioned video workflows (e.g., text/image/video-conditioned generation $\rightarrow$ multi-round editing $\rightarrow$ object segmentation $\rightarrow$ compositional synthesis) that were previously cumbersome to achieve with single-purpose models or monolithic video-language models. We also introduce UniVA-Bench, a benchmark suite of multi-step video tasks spanning understanding, editing, segmentation, and generation, to rigorously evaluate such agentic video systems. Both UniVA and UniVA-Bench are fully open-sourced, aiming to catalyze research on interactive, agentic, and general-purpose video intelligence for the next generation of multimodal AI systems. (https://univa.online/)
Poster: Enhancing GNN Robustness for Network Intrusion Detection via Agent-based Analysis
Jun 25, 2025Graph Neural Networks (GNNs) show great promise for Network Intrusion Detection Systems (NIDS), particularly in IoT environments, but suffer performance degradation due to distribution drift and lack robustness against realistic adversarial attacks. Current robustness evaluations often rely on unrealistic synthetic perturbations and lack demonstrations on systematic analysis of different kinds of adversarial attack, which encompass both black-box and white-box scenarios. This work proposes a novel approach to enhance GNN robustness and generalization by employing Large Language Models (LLMs) in an agentic pipeline as simulated cybersecurity expert agents. These agents scrutinize graph structures derived from network flow data, identifying and potentially mitigating suspicious or adversarially perturbed elements before GNN processing. Our experiments, using a framework designed for realistic evaluation and testing with a variety of adversarial attacks including a dataset collected from physical testbed experiments, demonstrate that integrating LLM analysis can significantly improve the resilience of GNN-based NIDS against challenges, showcasing the potential of LLM agent as a complementary layer in intrusion detection architectures.
Dynamic Dual Buffer with Divide-and-Conquer Strategy for Online Continual Learning
May 23, 2025Online Continual Learning (OCL) presents a complex learning environment in which new data arrives in a batch-to-batch online format, and the risk of catastrophic forgetting can significantly impair model efficacy. In this study, we address OCL by introducing an innovative memory framework that incorporates a short-term memory system to retain dynamic information and a long-term memory system to archive enduring knowledge. Specifically, the long-term memory system comprises a collection of sub-memory buffers, each linked to a cluster prototype and designed to retain data samples from distinct categories. We propose a novel $K$-means-based sample selection method to identify cluster prototypes for each encountered category. To safeguard essential and critical samples, we introduce a novel memory optimisation strategy that selectively retains samples in the appropriate sub-memory buffer by evaluating each cluster prototype against incoming samples through an optimal transportation mechanism. This approach specifically promotes each sub-memory buffer to retain data samples that exhibit significant discrepancies from the corresponding cluster prototype, thereby ensuring the preservation of semantically rich information. In addition, we propose a novel Divide-and-Conquer (DAC) approach that formulates the memory updating as an optimisation problem and divides it into several subproblems. As a result, the proposed DAC approach can solve these subproblems separately and thus can significantly reduce computations of the proposed memory updating process. We conduct a series of experiments across standard and imbalanced learning settings, and the empirical findings indicate that the proposed memory framework achieves state-of-the-art performance in both learning contexts.
EfficientLLM: Efficiency in Large Language Models
May 20, 2025Large Language Models (LLMs) have driven significant progress, yet their growing parameter counts and context windows incur prohibitive compute, energy, and monetary costs. We introduce EfficientLLM, a novel benchmark and the first comprehensive empirical study evaluating efficiency techniques for LLMs at scale. Conducted on a production-class cluster (48xGH200, 8xH200 GPUs), our study systematically explores three key axes: (1) architecture pretraining (efficient attention variants: MQA, GQA, MLA, NSA; sparse Mixture-of-Experts (MoE)), (2) fine-tuning (parameter-efficient methods: LoRA, RSLoRA, DoRA), and (3) inference (quantization methods: int4, float16). We define six fine-grained metrics (Memory Utilization, Compute Utilization, Latency, Throughput, Energy Consumption, Compression Rate) to capture hardware saturation, latency-throughput balance, and carbon cost. Evaluating over 100 model-technique pairs (0.5B-72B parameters), we derive three core insights: (i) Efficiency involves quantifiable trade-offs: no single method is universally optimal; e.g., MoE reduces FLOPs and improves accuracy but increases VRAM by 40%, while int4 quantization cuts memory/energy by up to 3.9x at a 3-5% accuracy drop. (ii) Optima are task- and scale-dependent: MQA offers optimal memory-latency trade-offs for constrained devices, MLA achieves lowest perplexity for quality-critical tasks, and RSLoRA surpasses LoRA efficiency only beyond 14B parameters. (iii) Techniques generalize across modalities: we extend evaluations to Large Vision Models (Stable Diffusion 3.5, Wan 2.1) and Vision-Language Models (Qwen2.5-VL), confirming effective transferability. By open-sourcing datasets, evaluation pipelines, and leaderboards, EfficientLLM provides essential guidance for researchers and engineers navigating the efficiency-performance landscape of next-generation foundation models.
Moral Reasoning Across Languages: The Critical Role of Low-Resource Languages in LLMs
Apr 28, 2025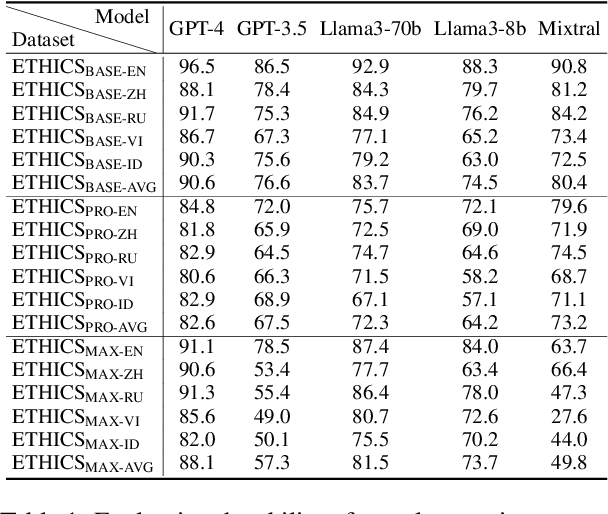
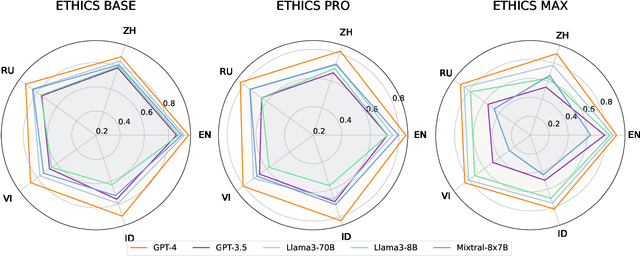
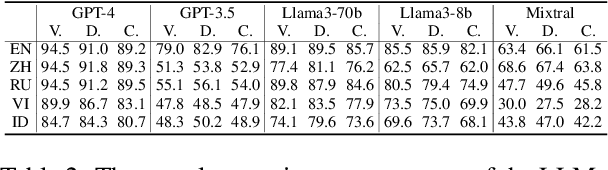
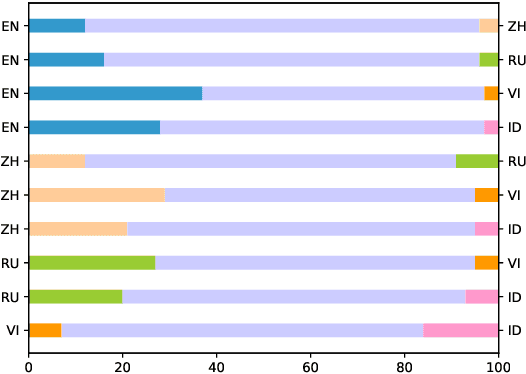
In this paper, we introduce the Multilingual Moral Reasoning Benchmark (MMRB) to evaluate the moral reasoning abilities of large language models (LLMs) across five typologically diverse languages and three levels of contextual complexity: sentence, paragraph, and document. Our results show moral reasoning performance degrades with increasing context complexity, particularly for low-resource languages such as Vietnamese. We further fine-tune the open-source LLaMA-3-8B model using curated monolingual data for alignment and poisoning. Surprisingly, low-resource languages have a stronger impact on multilingual reasoning than high-resource ones, highlighting their critical role in multilingual NLP.
Evaluate-and-Purify: Fortifying Code Language Models Against Adversarial Attacks Using LLM-as-a-Judge
Apr 28, 2025



The widespread adoption of code language models in software engineering tasks has exposed vulnerabilities to adversarial attacks, especially the identifier substitution attacks. Although existing identifier substitution attackers demonstrate high success rates, they often produce adversarial examples with unnatural code patterns. In this paper, we systematically assess the quality of adversarial examples using LLM-as-a-Judge. Our analysis reveals that over 80% of adversarial examples generated by state-of-the-art identifier substitution attackers (e.g., ALERT) are actually detectable. Based on this insight, we propose EP-Shield, a unified framework for evaluating and purifying identifier substitution attacks via naturalness-aware reasoning. Specifically, we first evaluate the naturalness of code and identify the perturbed adversarial code, then purify it so that the victim model can restore correct prediction. Extensive experiments demonstrate the superiority of EP-Shield over adversarial fine-tuning (up to 83.36% improvement) and its lightweight design 7B parameters) with GPT-4-level performance.
Reason Like a Radiologist: Chain-of-Thought and Reinforcement Learning for Verifiable Report Generation
Apr 25, 2025Radiology report generation is critical for efficiency but current models lack the structured reasoning of experts, hindering clinical trust and explainability by failing to link visual findings to precise anatomical locations. This paper introduces BoxMed-RL, a groundbreaking unified training framework for generating spatially verifiable and explainable radiology reports. Built on a large vision-language model, BoxMed-RL revolutionizes report generation through two integrated phases: (1) In the Pretraining Phase, we refine the model via medical concept learning, using Chain-of-Thought supervision to internalize the radiologist-like workflow, followed by spatially verifiable reinforcement, which applies reinforcement learning to align medical findings with bounding boxes. (2) In the Downstream Adapter Phase, we freeze the pretrained weights and train a downstream adapter to ensure fluent and clinically credible reports. This framework precisely mimics radiologists' workflow, compelling the model to connect high-level medical concepts with definitive anatomical evidence. Extensive experiments on public datasets demonstrate that BoxMed-RL achieves an average 7% improvement in both METEOR and ROUGE-L metrics compared to state-of-the-art methods. An average 5% improvement in large language model-based metrics further underscores BoxMed-RL's robustness in generating high-quality radiology reports.
Revisiting Medical Image Retrieval via Knowledge Consolidation
Mar 12, 2025As artificial intelligence and digital medicine increasingly permeate healthcare systems, robust governance frameworks are essential to ensure ethical, secure, and effective implementation. In this context, medical image retrieval becomes a critical component of clinical data management, playing a vital role in decision-making and safeguarding patient information. Existing methods usually learn hash functions using bottleneck features, which fail to produce representative hash codes from blended embeddings. Although contrastive hashing has shown superior performance, current approaches often treat image retrieval as a classification task, using category labels to create positive/negative pairs. Moreover, many methods fail to address the out-of-distribution (OOD) issue when models encounter external OOD queries or adversarial attacks. In this work, we propose a novel method to consolidate knowledge of hierarchical features and optimisation functions. We formulate the knowledge consolidation by introducing Depth-aware Representation Fusion (DaRF) and Structure-aware Contrastive Hashing (SCH). DaRF adaptively integrates shallow and deep representations into blended features, and SCH incorporates image fingerprints to enhance the adaptability of positive/negative pairings. These blended features further facilitate OOD detection and content-based recommendation, contributing to a secure AI-driven healthcare environment. Moreover, we present a content-guided ranking to improve the robustness and reproducibility of retrieval results. Our comprehensive assessments demonstrate that the proposed method could effectively recognise OOD samples and significantly outperform existing approaches in medical image retrieval (p<0.05). In particular, our method achieves a 5.6-38.9% improvement in mean Average Precision on the anatomical radiology dataset.