 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Model-Assisted Approach for Path Loss Prediction in Suburban Scenarios
Mar 10, 2026Accurate path loss prediction is crucial for wireless network planning and optimization in suburban environments with complex terrain variation and diverse land cover. This paper proposes a model assisted hybrid path loss prediction method that introduces an environment adaptive compensation on top of the classic close-in free-space reference distance (CI) path loss model. By jointly predicting the path loss exponent and a compensation term, the proposed approach dynamically adjusts the empirical trend. To improve the effectiveness of environmental representation, three environmental image organization schemes are constructed and evaluated. Experiments on measurement data collected in Pingtan Island show that the proposed method outperforms the CI model and a conventional model assisted baseline, achieving a test root mean square error of 4.04 dB.
Quantifying the Gap between Understanding and Generation within Unified Multimodal Models
Feb 02, 2026Recent advances in unified multimodal models (UMM) have demonstrated remarkable progress in both understanding and generation tasks. However, whether these two capabilities are genuinely aligned and integrated within a single model remains unclear. To investigate this question, we introduce GapEval, a bidirectional benchmark designed to quantify the gap between understanding and generation capabilities, and quantitatively measure the cognitive coherence of the two "unified" directions. Each question can be answered in both modalities (image and text), enabling a symmetric evaluation of a model's bidirectional inference capability and cross-modal consistency. Experiments reveal a persistent gap between the two directions across a wide range of UMMs with different architectures, suggesting that current models achieve only surface-level unification rather than deep cognitive convergence of the two. To further explore the underlying mechanism, we conduct an empirical study from the perspective of knowledge manipulation to illustrate the underlying limitations. Our findings indicate that knowledge within UMMs often remains disjoint. The capability emergence and knowledge across modalities are unsynchronized, paving the way for further exploration.
CausalSpatial: A Benchmark for Object-Centric Causal Spatial Reasoning
Jan 19, 2026Humans can look at a static scene and instantly predict what happens next -- will moving this object cause a collision? We call this ability Causal Spatial Reasoning. However, current multimodal large language models (MLLMs) cannot do this, as they remain largely restricted to static spatial perception, struggling to answer "what-if" questions in a 3D scene. We introduce CausalSpatial, a diagnostic benchmark evaluating whether models can anticipate consequences of object motions across four tasks: Collision, Compatibility, Occlusion, and Trajectory. Results expose a severe gap: humans score 84% while GPT-5 achieves only 54%. Why do MLLMs fail? Our analysis uncovers a fundamental deficiency: models over-rely on textual chain-of-thought reasoning that drifts from visual evidence, producing fluent but spatially ungrounded hallucinations. To address this, we propose the Causal Object World model (COW), a framework that externalizes the simulation process by generating videos of hypothetical dynamics. With explicit visual cues of causality, COW enables models to ground their reasoning in physical reality rather than linguistic priors. We make the dataset and code publicly available here: https://github.com/CausalSpatial/CausalSpatial
Wait, We Don't Need to "Wait"! Removing Thinking Tokens Improves Reasoning Efficiency
Jun 10, 2025



Recent advances in large reasoning models have enabled complex, step-by-step reasoning but often introduce significant overthinking, resulting in verbose and redundant outputs that hinder efficiency. In this study, we examine whether explicit self-reflection, signaled by tokens such as "Wait" and "Hmm", is necessary for advanced reasoning. We propose NoWait, a simple yet effective approach that disables explicit self-reflection by suppressing these tokens during inference. Extensive experiments on ten benchmarks across textual, visual, and video reasoning tasks show that NoWait reduces chain-of-thought trajectory length by up to 27%-51% in five R1-style model series, without compromising model utility. NoWait thus offers a plug-and-play solution for efficient and utility-preserving multimodal reasoning.
CODESYNC: Synchronizing Large Language Models with Dynamic Code Evolution at Scale
Feb 23, 2025Large Language Models (LLMs) have exhibited exceptional performance in software engineering yet face challenges in adapting to continually evolving code knowledge, particularly regarding the frequent updates of third-party library APIs. This limitation, stemming from static pre-training datasets, often results in non-executable code or implementations with suboptimal safety and efficiency. To this end, this paper introduces CODESYNC, a data engine for identifying outdated code patterns and collecting real-time code knowledge updates from Python third-party libraries. Building upon CODESYNC, we develop CODESYNCBENCH, a comprehensive benchmark for assessing LLMs' ability to stay synchronized with code evolution, which covers real-world updates for 220 APIs from six Python libraries. Our benchmark offers 3,300 test cases across three evaluation tasks and an update-aware instruction tuning dataset consisting of 2,200 training samples. Extensive experiments on 14 state-of-the-art LLMs reveal that they struggle with dynamic code evolution, even with the support of advanced knowledge updating methods (e.g., DPO, ORPO, and SimPO). We believe that our benchmark can offer a strong foundation for the development of more effective methods for real-time code knowledge updating in the future. The experimental code and dataset are publicly available at: https://github.com/Lucky-voyage/Code-Sync.
GUI-WORLD: A Dataset for GUI-oriented Multimodal LLM-based Agents
Jun 16, 2024

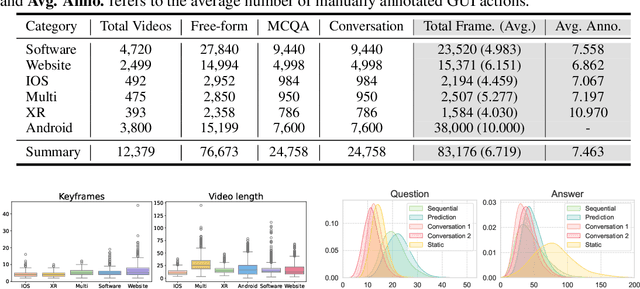

Recently, Multimodal Large Language Models (MLLMs) have been used as agents to control keyboard and mouse inputs by directly perceiving the Graphical User Interface (GUI) and generating corresponding code. However, current agents primarily exhibit excellent understanding capabilities in static environments and are predominantly applied in relatively simple domains, such as Web or mobile interfaces. We argue that a robust GUI agent should be capable of perceiving temporal information on the GUI, including dynamic Web content and multi-step tasks. Additionally, it should possess a comprehensive understanding of various GUI scenarios, including desktop software and multi-window interactions. To this end, this paper introduces a new dataset, termed GUI-World, which features meticulously crafted Human-MLLM annotations, extensively covering six GUI scenarios and eight types of GUI-oriented questions in three formats. We evaluate the capabilities of current state-of-the-art MLLMs, including ImageLLMs and VideoLLMs, in understanding various types of GUI content, especially dynamic and sequential content. Our findings reveal that ImageLLMs struggle with dynamic GUI content without manually annotated keyframes or operation history. On the other hand, VideoLLMs fall short in all GUI-oriented tasks given the sparse GUI video dataset. Based on GUI-World, we take the initial step of leveraging a fine-tuned VideoLLM as a GUI agent, demonstrating an improved understanding of various GUI tasks. However, due to the limitations in the performance of base LLMs, we conclude that using VideoLLMs as GUI agents remains a significant challenge. We believe our work provides valuable insights for future research in dynamic GUI content understanding. The code and dataset are publicly available at our project homepage: https://gui-world.github.io/.
Adaptive Fake Audio Detection with Low-Rank Model Squeezing
Jun 08, 2023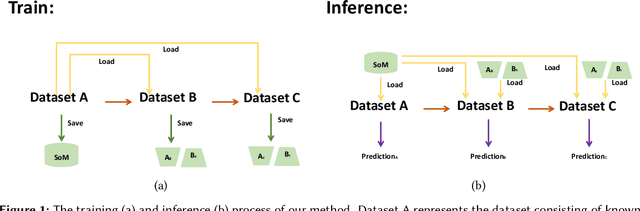
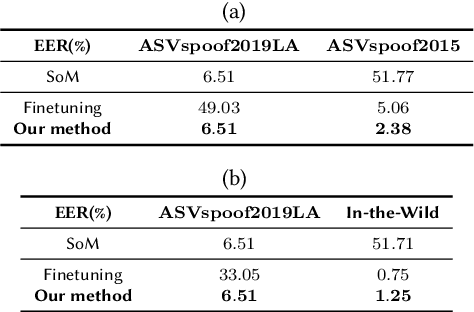

The rapid advancement of spoofing algorithms necessitates the development of robust detection methods capable of accurately identifying emerging fake audio. Traditional approaches, such as finetuning on new datasets containing these novel spoofing algorithms, are computationally intensive and pose a risk of impairing the acquired knowledge of known fake audio types. To address these challenges, this paper proposes an innovative approach that mitigates the limitations associated with finetuning. We introduce the concept of training low-rank adaptation matrices tailored specifically to the newly emerging fake audio types. During the inference stage, these adaptation matrices are combined with the existing model to generate the final prediction output. Extensive experimentation is conducted to evaluate the efficacy of the proposed method. The results demonstrate that our approach effectively preserves the prediction accuracy of the existing model for known fake audio types. Furthermore, our approach offers several advantages, including reduced storage memory requirements and lower equal error rates compared to conventional finetuning methods, particularly on specific spoofing algorithms.