 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlideSparse: Fast and Flexible (2N-2):2N Structured Sparsity
Mar 05, 2026NVIDIA's 2:4 Sparse Tensor Cores deliver 2x throughput but demand strict 50% pruning -- a ratio that collapses LLM reasoning accuracy (Qwen3: 54% to 15%). Milder $(2N-2):2N$ patterns (e.g., 6:8, 25% pruning) preserve accuracy yet receive no hardware support, falling back to dense execution without any benefit from sparsity. We present SlideSparse, the first system to unlock Sparse Tensor Core acceleration for the $(2N-2):2N$ model family on commodity GPUs. Our Sliding Window Decomposition reconstructs any $(2N-2):2N$ weight block into $N-1$ overlapping 2:4-compliant windows without any accuracy loss; Activation Lifting fuses the corresponding activation rearrangement into per-token quantization at near-zero cost. Integrated into vLLM, SlideSparse is evaluated across various GPUs (A100, H100, B200, RTX 4090, RTX 5080, DGX-spark), precisions (FP4, INT8, FP8, BF16, FP16), and model families (Llama, Qwen, BitNet). On compute-bound workloads, the measured speedup ratio (1.33x) approaches the theoretical upper-bound $N/(N-1)=4/3$ at 6:8 weight sparsity in Qwen2.5-7B, establishing $(2N-2):2N$ as a practical path to accuracy-preserving LLM acceleration. Code available at https://github.com/bcacdwk/vllmbench.
Covo-Audio Technical Report
Feb 10, 2026In this work, we present Covo-Audio, a 7B-parameter end-to-end LALM that directly processes continuous audio inputs and generates audio outputs within a single unified architecture. Through large-scale curated pretraining and targeted post-training, Covo-Audio achieves state-of-the-art or competitive performance among models of comparable scale across a broad spectrum of tasks, including speech-text modeling, spoken dialogue, speech understanding, audio understanding, and full-duplex voice interaction. Extensive evaluations demonstrate that the pretrained foundation model exhibits strong speech-text comprehension and semantic reasoning capabilities on multiple benchmarks, outperforming representative open-source models of comparable scale. Furthermore, Covo-Audio-Chat, the dialogue-oriented variant, demonstrates strong spoken conversational abilities, including understanding, contextual reasoning, instruction following, and generating contextually appropriate and empathetic responses, validating its applicability to real-world conversational assistant scenarios. Covo-Audio-Chat-FD, the evolved full-duplex model, achieves substantially superior performance on both spoken dialogue capabilities and full-duplex interaction behaviors, demonstrating its competence in practical robustness. To mitigate the high cost of deploying end-to-end LALMs for natural conversational systems, we propose an intelligence-speaker decoupling strategy that separates dialogue intelligence from voice rendering, enabling flexible voice customization with minimal text-to-speech (TTS) data while preserving dialogue performance. Overall, our results highlight the strong potential of 7B-scale models to integrate sophisticated audio intelligence with high-level semantic reasoning, and suggest a scalable path toward more capable and versatile LALMs.
OV-InstructTTS: Towards Open-Vocabulary Instruct Text-to-Speech
Jan 04, 2026Instruct Text-to-Speech (InstructTTS) leverages natural language descriptions as style prompts to guide speech synthesis. However, existing InstructTTS methods mainly rely on a direct combination of audio-related labels or their diverse rephrasings, making it difficult to handle flexible, high-level instructions. Such rigid control is insufficient for users such as content creators who wish to steer generation with descriptive instructions. To address these constraints, we introduce OV-InstructTTS, a new paradigm for open-vocabulary InstructTTS. We propose a comprehensive solution comprising a newly curated dataset, OV-Speech, and a novel reasoning-driven framework. The OV-Speech dataset pairs speech with open-vocabulary instructions, each augmented with a reasoning process that connects high-level instructions to acoustic features. The reasoning-driven framework infers emotional, acoustic, and paralinguistic information from open-vocabulary instructions before synthesizing speech. Evaluations show that this reasoning-driven approach significantly improves instruction-following fidelity and speech expressiveness. We believe this work can inspire the next user-friendly InstructTTS systems with stronger generalization and real-world applicability. The dataset and demos are publicly available on our project page.
GaussianDWM: 3D Gaussian Driving World Model for Unified Scene Understanding and Multi-Modal Generation
Dec 29, 2025Driving World Models (DWMs) have been developing rapidly with the advances of generative models. However, existing DWMs lack 3D scene understanding capabilities and can only generate content conditioned on input data, without the ability to interpret or reason about the driving environment. Moreover, current approaches represent 3D spatial information with point cloud or BEV features do not accurately align textual information with the underlying 3D scene. To address these limitations, we propose a novel unified DWM framework based on 3D Gaussian scene representation, which enables both 3D scene understanding and multi-modal scene generation, while also enabling contextual enrichment for understanding and generation tasks. Our approach directly aligns textual information with the 3D scene by embedding rich linguistic features into each Gaussian primitive, thereby achieving early modality alignment. In addition, we design a novel task-aware language-guided sampling strategy that removes redundant 3D Gaussians and injects accurate and compact 3D tokens into LLM. Furthermore, we design a dual-condition multi-modal generation model, where the information captured by our vision-language model is leveraged as a high-level language condition in combination with a low-level image condition, jointly guiding the multi-modal generation process. We conduct comprehensive studies on the nuScenes, and NuInteract datasets to validate the effectiveness of our framework. Our method achieves state-of-the-art performance. We will release the code publicly on GitHub https://github.com/dtc111111/GaussianDWM.
OmniDrive-R1: Reinforcement-driven Interleaved Multi-modal Chain-of-Thought for Trustworthy Vision-Language Autonomous Driving
Dec 16, 2025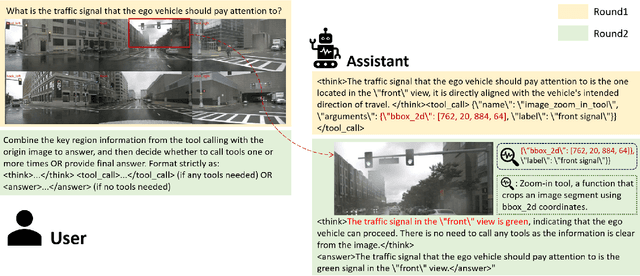

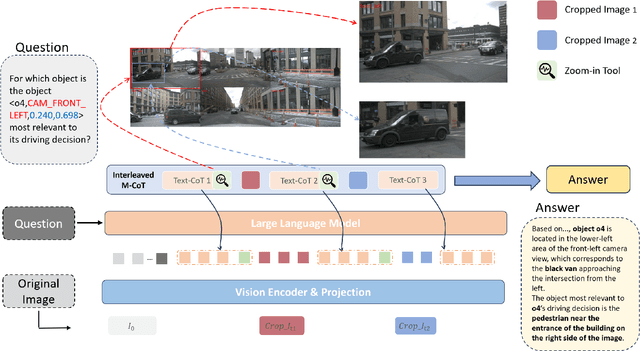

The deployment of Vision-Language Models (VLMs) in safety-critical domains like autonomous driving (AD) is critically hindered by reliability failures, most notably object hallucination. This failure stems from their reliance on ungrounded, text-based Chain-of-Thought (CoT) reasoning.While existing multi-modal CoT approaches attempt mitigation, they suffer from two fundamental flaws: (1) decoupled perception and reasoning stages that prevent end-to-end joint optimization, and (2) reliance on expensive, dense localization labels.Thus we introduce OmniDrive-R1, an end-to-end VLM framework designed for autonomous driving, which unifies perception and reasoning through an interleaved Multi-modal Chain-of-Thought (iMCoT) mechanism. Our core innovation is an Reinforcement-driven visual grounding capability, enabling the model to autonomously direct its attention and "zoom in" on critical regions for fine-grained analysis. This capability is enabled by our pure two-stage reinforcement learning training pipeline and Clip-GRPO algorithm. Crucially, Clip-GRPO introduces an annotation-free, process-based grounding reward. This reward not only eliminates the need for dense labels but also circumvents the instability of external tool calls by enforcing real-time cross-modal consistency between the visual focus and the textual reasoning. Extensive experiments on DriveLMM-o1 demonstrate our model's significant improvements. Compared to the baseline Qwen2.5VL-7B, OmniDrive-R1 improves the overall reasoning score from 51.77% to 80.35%, and the final answer accuracy from 37.81% to 73.62%.
Perception Activator: An intuitive and portable framework for brain cognitive exploration
Jul 03, 2025Recent advances in brain-vision decoding have driven significant progress, reconstructing with high fidelity perceived visual stimuli from neural activity, e.g., functional magnetic resonance imaging (fMRI), in the human visual cortex. Most existing methods decode the brain signal using a two-level strategy, i.e., pixel-level and semantic-level. However, these methods rely heavily on low-level pixel alignment yet lack sufficient and fine-grained semantic alignment, resulting in obvious reconstruction distortions of multiple semantic objects. To better understand the brain's visual perception patterns and how current decoding models process semantic objects, we have developed an experimental framework that uses fMRI representations as intervention conditions. By injecting these representations into multi-scale image features via cross-attention, we compare both downstream performance and intermediate feature changes on object detection and instance segmentation tasks with and without fMRI information. Our results demonstrate that incorporating fMRI signals enhances the accuracy of downstream detection and segmentation, confirming that fMRI contains rich multi-object semantic cues and coarse spatial localization information-elements that current models have yet to fully exploit or integrate.
Mitigating Audiovisual Mismatch in Visual-Guide Audio Captioning
May 28, 2025Current vision-guided audio captioning systems frequently fail to address audiovisual misalignment in real-world scenarios, such as dubbed content or off-screen sounds. To bridge this critical gap, we present an entropy-aware gated fusion framework that dynamically modulates visual information flow through cross-modal uncertainty quantification. Our novel approach employs attention entropy analysis in cross-attention layers to automatically identify and suppress misleading visual cues during modal fusion. Complementing this architecture, we develop a batch-wise audiovisual shuffling technique that generates synthetic mismatched training pairs, greatly enhancing model resilience against alignment noise. Evaluations on the AudioCaps benchmark demonstrate our system's superior performance over existing baselines, especially in mismatched modality scenarios. Furthermore, our solution demonstrates an approximately 6x improvement in inference speed compared to the baseline.
Hearing from Silence: Reasoning Audio Descriptions from Silent Videos via Vision-Language Model
May 19, 2025Humans can intuitively infer sounds from silent videos, but whether multimodal large language models can perform modal-mismatch reasoning without accessing target modalities remains relatively unexplored. Current text-assisted-video-to-audio (VT2A) methods excel in video foley tasks but struggle to acquire audio descriptions during inference. We introduce the task of Reasoning Audio Descriptions from Silent Videos (SVAD) to address this challenge and investigate vision-language models' (VLMs) capabilities on this task. To further enhance the VLMs' reasoning capacity for the SVAD task, we construct a CoT-AudioCaps dataset and propose a Chain-of-Thought-based supervised fine-tuning strategy. Experiments on SVAD and subsequent VT2A tasks demonstrate our method's effectiveness in two key aspects: significantly improving VLMs' modal-mismatch reasoning for SVAD and effectively addressing the challenge of acquiring audio descriptions during VT2A inference.
DynamicDTA: Drug-Target Binding Affinity Prediction Using Dynamic Descriptors and Graph Representation
May 13, 2025Predicting drug-target binding affinity (DTA) is essential for identifying potential therapeutic candidates in drug discovery. However, most existing models rely heavily on static protein structures, often overlooking the dynamic nature of proteins, which is crucial for capturing conformational flexibility that will be beneficial for protein binding interactions. We introduce DynamicDTA, an innovative deep learning framework that incorporates static and dynamic protein features to enhance DTA prediction. The proposed DynamicDTA takes three types of inputs, including drug sequence, protein sequence, and dynamic descriptors. A molecular graph representation of the drug sequence is generated and subsequently processed through graph convolutional network, while the protein sequence is encoded using dilated convolutions. Dynamic descriptors, such as root mean square fluctuation, are processed through a multi-layer perceptron. These embedding features are fused with static protein features using cross-attention, and a tensor fusion network integrates all three modalities for DTA prediction. Extensive experiments on three datasets demonstrate that DynamicDTA achieves by at least 3.4% improvement in RMSE score with comparison to seven state-of-the-art baseline methods. Additionally, predicting novel drugs for Human Immunodeficiency Virus Type 1 and visualizing the docking complexes further demonstrates the reliability and biological relevance of DynamicDTA.
ASMR: Activation-sharing Multi-resolution Coordinate Networks For Efficient Inference
May 20, 2024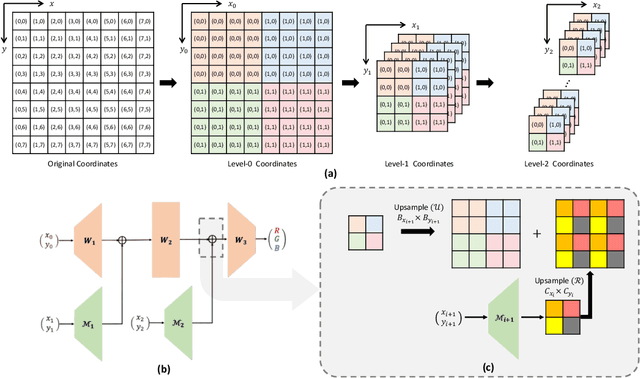
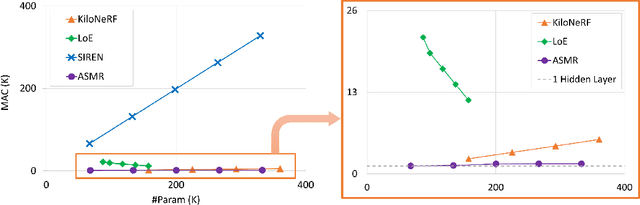
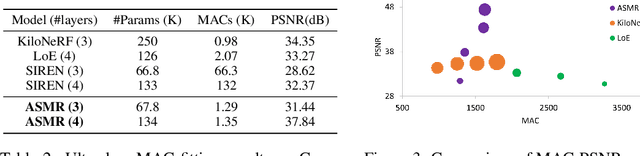
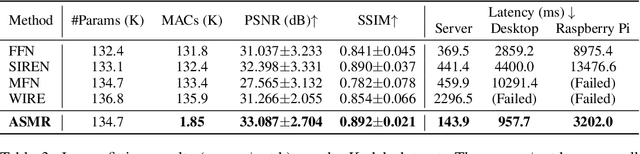
Coordinate network or implicit neural representation (INR) is a fast-emerging method for encoding natural signals (such as images and videos) with the benefits of a compact neural representation. While numerous methods have been proposed to increase the encoding capabilities of an INR, an often overlooked aspect is the inference efficiency, usually measured in multiply-accumulate (MAC) count. This is particularly critical in use cases where inference throughput is greatly limited by hardware constraints. To this end, we propose the Activation-Sharing Multi-Resolution (ASMR) coordinate network that combines multi-resolution coordinate decomposition with hierarchical modulations. Specifically, an ASMR model enables the sharing of activations across grids of the data. This largely decouples its inference cost from its depth which is directly correlated to its reconstruction capability, and renders a near O(1) inference complexity irrespective of the number of layers. Experiments show that ASMR can reduce the MAC of a vanilla SIREN model by up to 500x while achieving an even higher reconstruction quality than its SIREN baseline.