 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Rumor Spreading in Social Networks using LLM Agents
Feb 03, 2025With the rise of social media, misinformation has become increasingly prevalent, fueled largely by the spread of rumors. This study explores the use of Large Language Model (LLM) agents within a novel framework to simulate and analyze the dynamics of rumor propagation across social networks. To this end, we design a variety of LLM-based agent types and construct four distinct network structures to conduct these simulations. Our framework assesses the effectiveness of different network constructions and agent behaviors in influencing the spread of rumors. Our results demonstrate that the framework can simulate rumor spreading across more than one hundred agents in various networks with thousands of edges. The evaluations indicate that network structure, personas, and spreading schemes can significantly influence rumor dissemination, ranging from no spread to affecting 83\% of agents in iterations, thereby offering a realistic simulation of rumor spread in social networks.
Learned Compression for Compressed Learning
Dec 12, 2024Modern sensors produce increasingly rich streams of high-resolution data. Due to resource constraints, machine learning systems discard the vast majority of this information via resolution reduction. Compressed-domain learning allows models to operate on compact latent representations, allowing higher effective resolution for the same budget. However, existing compression systems are not ideal for compressed learning. Linear transform coding and end-to-end learned compression systems reduce bitrate, but do not uniformly reduce dimensionality; thus, they do not meaningfully increase efficiency. Generative autoencoders reduce dimensionality, but their adversarial or perceptual objectives lead to significant information loss. To address these limitations, we introduce WaLLoC (Wavelet Learned Lossy Compression), a neural codec architecture that combines linear transform coding with nonlinear dimensionality-reducing autoencoders. WaLLoC sandwiches a shallow, asymmetric autoencoder and entropy bottleneck between an invertible wavelet packet transform. Across several key metrics, WaLLoC outperforms the autoencoders used in state-of-the-art latent diffusion models. WaLLoC does not require perceptual or adversarial losses to represent high-frequency detail, providing compatibility with modalities beyond RGB images and stereo audio. WaLLoC's encoder consists almost entirely of linear operations, making it exceptionally efficient and suitable for mobile computing, remote sensing, and learning directly from compressed data. We demonstrate WaLLoC's capability for compressed-domain learning across several tasks, including image classification, colorization, document understanding, and music source separation. Our code, experiments, and pre-trained audio and image codecs are available at https://ut-sysml.org/walloc
SoK: A Systems Perspective on Compound AI Threats and Countermeasures
Nov 20, 2024



Large language models (LLMs) used across enterprises often use proprietary models and operate on sensitive inputs and data. The wide range of attack vectors identified in prior research - targeting various software and hardware components used in training and inference - makes it extremely challenging to enforce confidentiality and integrity policies. As we advance towards constructing compound AI inference pipelines that integrate multiple large language models (LLMs), the attack surfaces expand significantly. Attackers now focus on the AI algorithms as well as the software and hardware components associated with these systems. While current research often examines these elements in isolation, we find that combining cross-layer attack observations can enable powerful end-to-end attacks with minimal assumptions about the threat model. Given, the sheer number of existing attacks at each layer, we need a holistic and systemized understanding of different attack vectors at each layer. This SoK discusses different software and hardware attacks applicable to compound AI systems and demonstrates how combining multiple attack mechanisms can reduce the threat model assumptions required for an isolated attack. Next, we systematize the ML attacks in lines with the Mitre Att&ck framework to better position each attack based on the threat model. Finally, we outline the existing countermeasures for both software and hardware layers and discuss the necessity of a comprehensive defense strategy to enable the secure and high-performance deployment of compound AI systems.
Shrinking the Giant : Quasi-Weightless Transformers for Low Energy Inference
Nov 04, 2024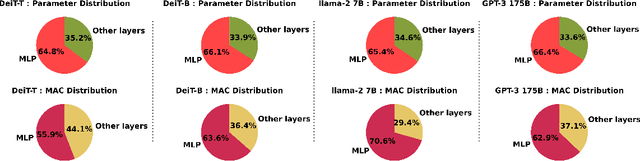

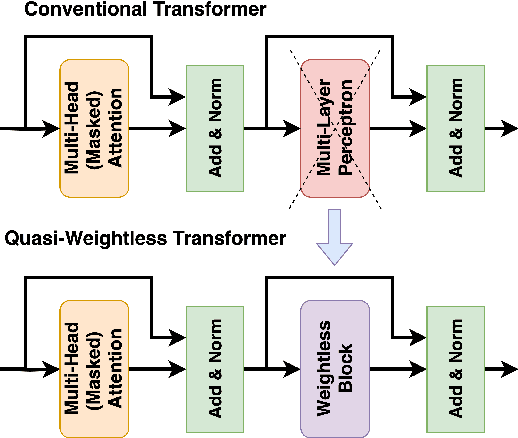
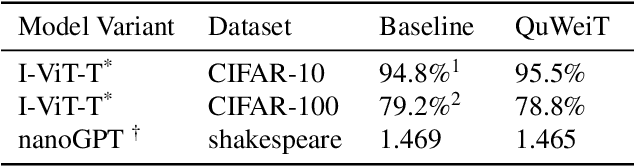
Transformers are set to become ubiquitous with applications ranging from chatbots and educational assistants to visual recognition and remote sensing. However, their increasing computational and memory demands is resulting in growing energy consumption. Building models with fast and energy-efficient inference is imperative to enable a variety of transformer-based applications. Look Up Table (LUT) based Weightless Neural Networks are faster than the conventional neural networks as their inference only involves a few lookup operations. Recently, an approach for learning LUT networks directly via an Extended Finite Difference method was proposed. We build on this idea, extending it for performing the functions of the Multi Layer Perceptron (MLP) layers in transformer models and integrating them with transformers to propose Quasi Weightless Transformers (QuWeiT). This allows for a computational and energy-efficient inference solution for transformer-based models. On I-ViT-T, we achieve a comparable accuracy of 95.64% on CIFAR-10 dataset while replacing approximately 55% of all the multiplications in the entire model and achieving a 2.2x energy efficiency. We also observe similar savings on experiments with the nanoGPT framework.
Shabari: Delayed Decision-Making for Faster and Efficient Serverless Functions
Jan 25, 2024



Serverless computing relieves developers from the burden of resource management, thus providing ease-of-use to the users and the opportunity to optimize resource utilization for the providers. However, today's serverless systems lack performance guarantees for function invocations, thus limiting support for performance-critical applications: we observed severe performance variability (up to 6x). Providers lack visibility into user functions and hence find it challenging to right-size them: we observed heavy resource underutilization (up to 80%). To understand the causes behind the performance variability and underutilization, we conducted a measurement study of commonly deployed serverless functions and learned that the function performance and resource utilization depend crucially on function semantics and inputs. Our key insight is to delay making resource allocation decisions until after the function inputs are available. We introduce Shabari, a resource management framework for serverless systems that makes decisions as late as possible to right-size each invocation to meet functions' performance objectives (SLOs) and improve resource utilization. Shabari uses an online learning agent to right-size each function invocation based on the features of the function input and makes cold-start-aware scheduling decisions. For a range of serverless functions and inputs, Shabari reduces SLO violations by 11-73% while not wasting any vCPUs and reducing wasted memory by 64-94% in the median case, compared to state-of-the-art systems, including Aquatope, Parrotfish, and Cypress.
Machine Perceptual Quality: Evaluating the Impact of Severe Lossy Compression on Audio and Image Models
Jan 15, 2024



In the field of neural data compression, the prevailing focus has been on optimizing algorithms for either classical distortion metrics, such as PSNR or SSIM, or human perceptual quality. With increasing amounts of data consumed by machines rather than humans, a new paradigm of machine-oriented compression$\unicode{x2013}$which prioritizes the retention of features salient for machine perception over traditional human-centric criteria$\unicode{x2013}$has emerged, creating several new challenges to the development, evaluation, and deployment of systems utilizing lossy compression. In particular, it is unclear how different approaches to lossy compression will affect the performance of downstream machine perception tasks. To address this under-explored area, we evaluate various perception models$\unicode{x2013}$including image classification, image segmentation, speech recognition, and music source separation$\unicode{x2013}$under severe lossy compression. We utilize several popular codecs spanning conventional, neural, and generative compression architectures. Our results indicate three key findings: (1) using generative compression, it is feasible to leverage highly compressed data while incurring a negligible impact on machine perceptual quality; (2) machine perceptual quality correlates strongly with deep similarity metrics, indicating a crucial role of these metrics in the development of machine-oriented codecs; and (3) using lossy compressed datasets, (e.g. ImageNet) for pre-training can lead to counter-intuitive scenarios where lossy compression increases machine perceptual quality rather than degrading it. To encourage engagement on this growing area of research, our code and experiments are available at: https://github.com/danjacobellis/MPQ.
MOSEL: Inference Serving Using Dynamic Modality Selection
Oct 27, 2023Rapid advancements over the years have helped machine learning models reach previously hard-to-achieve goals, sometimes even exceeding human capabilities. However, to attain the desired accuracy, the model sizes and in turn their computational requirements have increased drastically. Thus, serving predictions from these models to meet any target latency and cost requirements of applications remains a key challenge, despite recent work in building inference-serving systems as well as algorithmic approaches that dynamically adapt models based on inputs. In this paper, we introduce a form of dynamism, modality selection, where we adaptively choose modalities from inference inputs while maintaining the model quality. We introduce MOSEL, an automated inference serving system for multi-modal ML models that carefully picks input modalities per request based on user-defined performance and accuracy requirements. MOSEL exploits modality configurations extensively, improving system throughput by 3.6$\times$ with an accuracy guarantee and shortening job completion times by 11$\times$.
INFaaS: Managed & Model-less Inference Serving
May 30, 2019

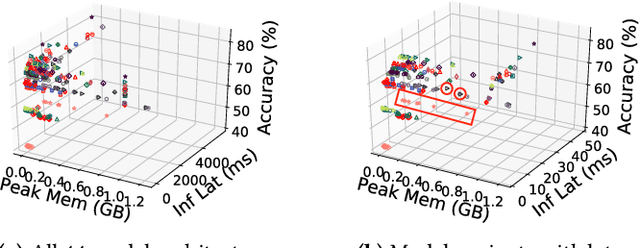
The number of applications relying on inference from machine learning models is already large and expected to keep growing. For instance, Facebook applications issue tens-of-trillions of inference queries per day with varying performance, accuracy, and cost constraints. Unfortunately, existing inference serving systems are neither easy to use nor cost effective. Developers must manually match the performance, accuracy, and cost constraints of their applications to a large design space that includes decisions such as selecting the right model and model optimizations, selecting the right hardware architecture, selecting the right scale-out factor, and avoiding cold-start effects. These interacting decisions are difficult to make, especially when the application load varies over time, applications evolve over time, and the available resources vary over time. We present INFaaS, an inference-as-a-service system that abstracts resource management and model selection. Users simply specify their inference task along with any performance and accuracy requirements for queries. Given the currently available resources, INFaaS automatically selects and serves inference queries using a specific model that satisfies these requirements. INFaaS autoscales resources as model load changes both within and across inference workers. It also shares workers across users and models to increase utilization. We evaluate INFaaS using 44 model architectures and their 270 model variants against serving systems rely on users for model se push model variant section and pre-load models, fix the scale policy, or use dedicated hardware resources. Our evaluation on realistic workloads shows that INFaaS achieves 2$\times$ higher throughput and violates latency SLO goals 3$\times$ less frequently, while maintaining high utilization and having overheads that are less than 12% of millisecond-scale queries.