 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlash-Fusion: Enabling Expressive, Low-Latency Queries on IoT Sensor Streams with LLMs
Nov 14, 2025Smart cities and pervasive IoT deployments have generated interest in IoT data analysis across transportation and urban planning. At the same time, Large Language Models offer a new interface for exploring IoT data - particularly through natural language. Users today face two key challenges when working with IoT data using LLMs: (1) data collection infrastructure is expensive, producing terabytes of low-level sensor readings that are too granular for direct use, and (2) data analysis is slow, requiring iterative effort and technical expertise. Directly feeding all IoT telemetry to LLMs is impractical due to finite context windows, prohibitive token costs at scale, and non-interactive latencies. What is missing is a system that first parses a user's query to identify the analytical task, then selects the relevant data slices, and finally chooses the right representation before invoking an LLM. We present Flash-Fusion, an end-to-end edge-cloud system that reduces the IoT data collection and analysis burden on users. Two principles guide its design: (1) edge-based statistical summarization (achieving 73.5% data reduction) to address data volume, and (2) cloud-based query planning that clusters behavioral data and assembles context-rich prompts to address data interpretation. We deploy Flash-Fusion on a university bus fleet and evaluate it against a baseline that feeds raw data to a state-of-the-art LLM. Flash-Fusion achieves a 95% latency reduction and 98% decrease in token usage and cost while maintaining high-quality responses. It enables personas across disciplines - safety officers, urban planners, fleet managers, and data scientists - to efficiently iterate over IoT data without the burden of manual query authoring or preprocessing.
INFaaS: Managed & Model-less Inference Serving
May 30, 2019

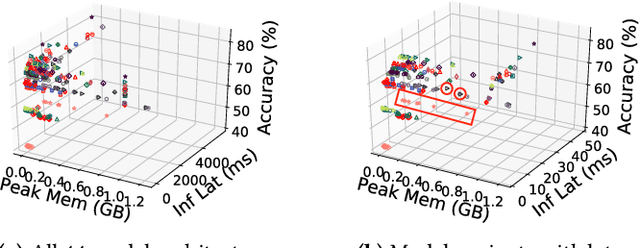
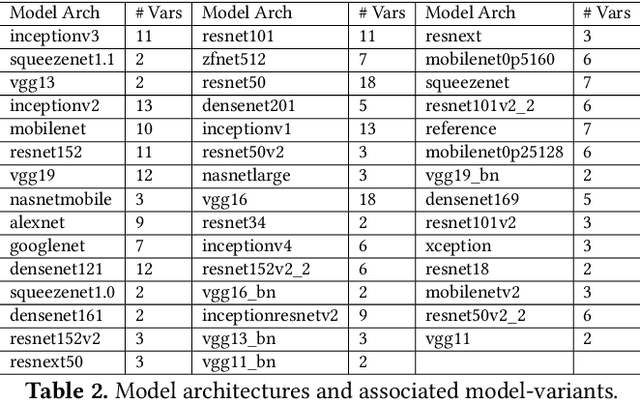
The number of applications relying on inference from machine learning models is already large and expected to keep growing. For instance, Facebook applications issue tens-of-trillions of inference queries per day with varying performance, accuracy, and cost constraints. Unfortunately, existing inference serving systems are neither easy to use nor cost effective. Developers must manually match the performance, accuracy, and cost constraints of their applications to a large design space that includes decisions such as selecting the right model and model optimizations, selecting the right hardware architecture, selecting the right scale-out factor, and avoiding cold-start effects. These interacting decisions are difficult to make, especially when the application load varies over time, applications evolve over time, and the available resources vary over time. We present INFaaS, an inference-as-a-service system that abstracts resource management and model selection. Users simply specify their inference task along with any performance and accuracy requirements for queries. Given the currently available resources, INFaaS automatically selects and serves inference queries using a specific model that satisfies these requirements. INFaaS autoscales resources as model load changes both within and across inference workers. It also shares workers across users and models to increase utilization. We evaluate INFaaS using 44 model architectures and their 270 model variants against serving systems rely on users for model se push model variant section and pre-load models, fix the scale policy, or use dedicated hardware resources. Our evaluation on realistic workloads shows that INFaaS achieves 2$\times$ higher throughput and violates latency SLO goals 3$\times$ less frequently, while maintaining high utilization and having overheads that are less than 12% of millisecond-scale queries.