 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Efficiency of GPU Kernel Optimization Agents using a Domain-Specific Language and Speed-of-Light Guidance
Mar 30, 2026Optimizing GPU kernels with LLM agents is an iterative process over a large design space. Every candidate must be generated, compiled, validated, and profiled, so fewer trials will save both runtime and cost. We make two key observations. First, the abstraction level that agents operate at is important. If it is too low, the LLM wastes reasoning on low-impact details. If it is too high, it may miss important optimization choices. Second, agents cannot easily tell when they reach the point of diminishing returns, wasting resources as they continue searching. These observations motivate two design principles to improve efficiency: (1) a compact domain-specific language (DSL) that can be learned in context and lets the model reason at a higher level while preserving important optimization levers, and (2) Speed-of-Light (SOL) guidance that uses first-principles performance bounds to steer and budget search. We implement these principles in $μ$CUTLASS, a DSL with a compiler for CUTLASS-backed GPU kernels that covers kernel configuration, epilogue fusion, and multi-stage pipelines. We use SOL guidance to estimate headroom and guide optimization trials, deprioritize problems that are near SOL, and flag kernels that game the benchmark. On 59 KernelBench problems with the same iteration budgets, switching from generating low-level code to DSL code using GPT-5-mini turns a 0.40x geomean regression into a 1.27x speedup over PyTorch. Adding SOL-guided steering raises this to 1.56x. Across model tiers, $μ$CUTLASS + SOL-guidance lets weaker models outperform stronger baseline agents at lower token cost. SOL-guided budgeting saves 19-43% of tokens while retaining at least 95% of geomean speedup, with the best policy reaching a 1.68x efficiency gain. Lastly, SOL analysis helps detect benchmark-gaming cases, where kernels may appear fast while failing to perform the intended computation.
SOL-ExecBench: Speed-of-Light Benchmarking for Real-World GPU Kernels Against Hardware Limits
Mar 19, 2026As agentic AI systems become increasingly capable of generating and optimizing GPU kernels, progress is constrained by benchmarks that reward speedup over software baselines rather than proximity to hardware-efficient execution. We present SOL-ExecBench, a benchmark of 235 CUDA kernel optimization problems extracted from 124 production and emerging AI models spanning language, diffusion, vision, audio, video, and hybrid architectures, targeting NVIDIA Blackwell GPUs. The benchmark covers forward and backward workloads across BF16, FP8, and NVFP4, including kernels whose best performance is expected to rely on Blackwell-specific capabilities. Unlike prior benchmarks that evaluate kernels primarily relative to software implementations, SOL-ExecBench measures performance against analytically derived Speed-of-Light (SOL) bounds computed by SOLAR, our pipeline for deriving hardware-grounded SOL bounds, yielding a fixed target for hardware-efficient optimization. We report a SOL Score that quantifies how much of the gap between a release-defined scoring baseline and the hardware SOL bound a candidate kernel closes. To support robust evaluation of agentic optimizers, we additionally provide a sandboxed harness with GPU clock locking, L2 cache clearing, isolated subprocess execution, and static analysis based checks against common reward-hacking strategies. SOL-ExecBench reframes GPU kernel benchmarking from beating a mutable software baseline to closing the remaining gap to hardware Speed-of-Light.
AI+HW 2035: Shaping the Next Decade
Mar 05, 2026Artificial intelligence (AI) and hardware (HW) are advancing at unprecedented rates, yet their trajectories have become inseparably intertwined. The global research community lacks a cohesive, long-term vision to strategically coordinate the development of AI and HW. This fragmentation constrains progress toward holistic, sustainable, and adaptive AI systems capable of learning, reasoning, and operating efficiently across cloud, edge, and physical environments. The future of AI depends not only on scaling intelligence, but on scaling efficiency, achieving exponential gains in intelligence per joule, rather than unbounded compute consumption. Addressing this grand challenge requires rethinking the entire computing stack. This vision paper lays out a 10-year roadmap for AI+HW co-design and co-development, spanning algorithms, architectures, systems, and sustainability. We articulate key insights that redefine scaling around energy efficiency, system-level integration, and cross-layer optimization. We identify key challenges and opportunities, candidly assess potential obstacles and pitfalls, and propose integrated solutions grounded in algorithmic innovation, hardware advances, and software abstraction. Looking ahead, we define what success means in 10 years: achieving a 1000x improvement in efficiency for AI training and inference; enabling energy-aware, self-optimizing systems that seamlessly span cloud, edge, and physical AI; democratizing access to advanced AI infrastructure; and embedding human-centric principles into the design of intelligent systems. Finally, we outline concrete action items for academia, industry, government, and the broader community, calling for coordinated national initiatives, shared infrastructure, workforce development, cross-agency collaboration, and sustained public-private partnerships to ensure that AI+HW co-design becomes a unifying long-term mission.
KernelBlaster: Continual Cross-Task CUDA Optimization via Memory-Augmented In-Context Reinforcement Learning
Feb 15, 2026Optimizing CUDA code across multiple generations of GPU architectures is challenging, as achieving peak performance requires an extensive exploration of an increasingly complex, hardware-specific optimization space. Traditional compilers are constrained by fixed heuristics, whereas finetuning Large Language Models (LLMs) can be expensive. However, agentic workflows for CUDA code optimization have limited ability to aggregate knowledge from prior exploration, leading to biased sampling and suboptimal solutions. We propose KernelBlaster, a Memory-Augmented In-context Reinforcement Learning (MAIC-RL) framework designed to improve CUDA optimization search capabilities of LLM-based GPU coding agents. KernelBlaster enables agents to learn from experience and make systematically informed decisions on future tasks by accumulating knowledge into a retrievable Persistent CUDA Knowledge Base. We propose a novel profile-guided, textual-gradient-based agentic flow for CUDA generation and optimization to achieve high performance across generations of GPU architectures. KernelBlaster guides LLM agents to systematically explore high-potential optimization strategies beyond naive rewrites. Compared to the PyTorch baseline, our method achieves geometric mean speedups of 1.43x, 2.50x, and 1.50x on KernelBench Levels 1, 2, and 3, respectively. We release KernelBlaster as an open-source agentic framework, accompanied by a test harness, verification components, and a reproducible evaluation pipeline.
Accelerating Mixture-of-Experts Training with Adaptive Expert Replication
Apr 28, 2025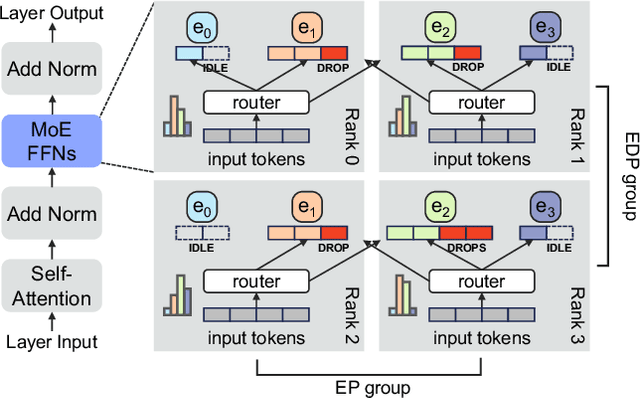

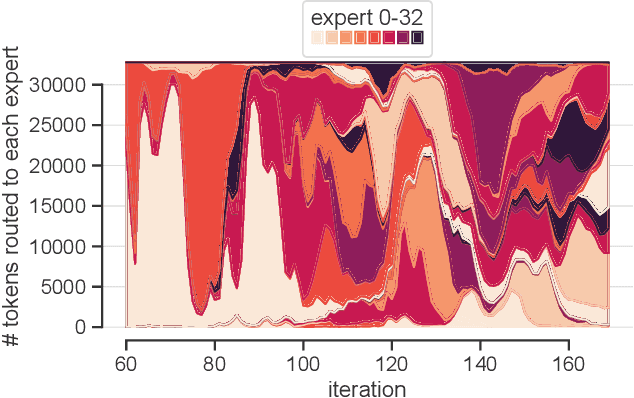
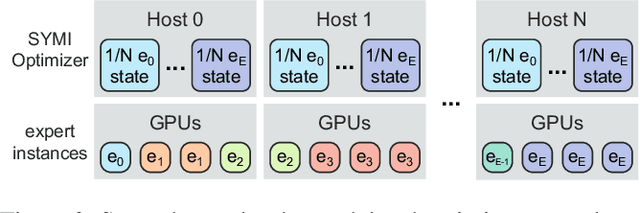
Mixture-of-Experts (MoE) models have become a widely adopted solution to continue scaling model sizes without a corresponding linear increase in compute. During MoE model training, each input token is dynamically routed to a subset of experts -- sparsely-activated feed-forward networks -- within each transformer layer. The distribution of tokens assigned to each expert varies widely and rapidly over the course of training. To handle the wide load imbalance across experts, current systems are forced to either drop tokens assigned to popular experts, degrading convergence, or frequently rebalance resources allocated to each expert based on popularity, incurring high state migration overheads. To break this performance-accuracy tradeoff, we introduce SwiftMoE, an adaptive MoE training system. The key insight of SwiftMoE is to decouple the placement of expert parameters from their large optimizer state. SwiftMoE statically partitions the optimizer of each expert across all training nodes. Meanwhile, SwiftMoE dynamically adjusts the placement of expert parameters by repurposing existing weight updates, avoiding migration overheads. In doing so, SwiftMoE right-sizes the GPU resources allocated to each expert, on a per-iteration basis, with minimal overheads. Compared to state-of-the-art MoE training systems, DeepSpeed and FlexMoE, SwiftMoE is able to achieve a 30.5% and 25.9% faster time-to-convergence, respectively.
Efficient GNN Training Through Structure-Aware Randomized Mini-Batching
Apr 25, 2025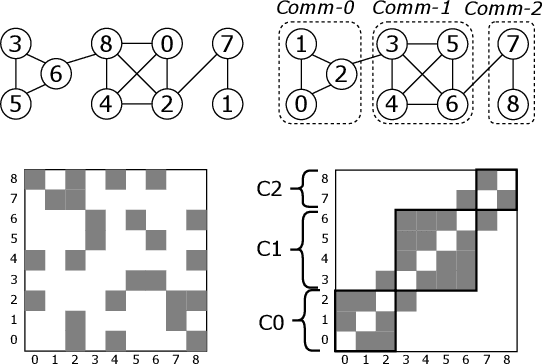

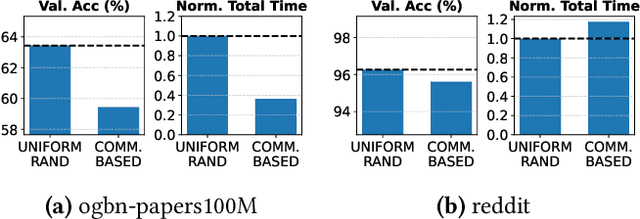
Graph Neural Networks (GNNs) enable learning on realworld graphs and mini-batch training has emerged as the de facto standard for training GNNs because it can scale to very large graphs and improve convergence. Current mini-batch construction policies largely ignore efficiency considerations of GNN training. Specifically, existing mini-batching techniques employ randomization schemes to improve accuracy and convergence. However, these randomization schemes are often agnostic to the structural properties of the graph (for eg. community structure), resulting in highly irregular memory access patterns during GNN training that make suboptimal use of on-chip GPU caches. On the other hand, while deterministic mini-batching based solely on graph structure delivers fast runtime performance, the lack of randomness compromises both the final model accuracy and training convergence speed. In this paper, we present Community-structure-aware Randomized Mini-batching (COMM-RAND), a novel methodology that bridges the gap between the above extremes. COMM-RAND allows practitioners to explore the space between pure randomness and pure graph structural awareness during mini-batch construction, leading to significantly more efficient GNN training with similar accuracy. We evaluated COMM-RAND across four popular graph learning benchmarks. COMM-RAND cuts down GNN training time by up to 2.76x (1.8x on average) while achieving an accuracy that is within 1.79% points (0.42% on average) compared to popular random mini-batching approaches.
AI Metropolis: Scaling Large Language Model-based Multi-Agent Simulation with Out-of-order Execution
Nov 05, 2024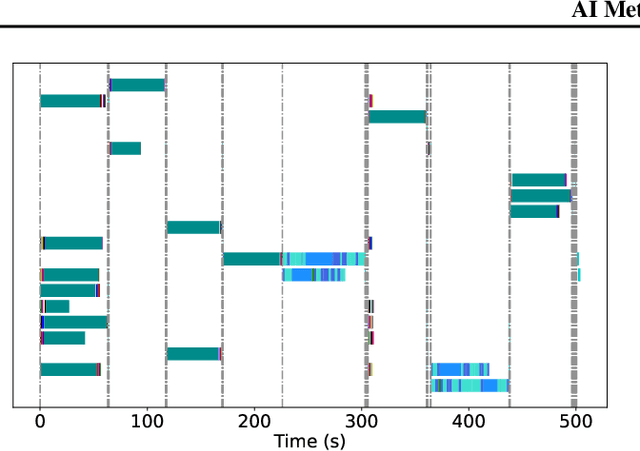
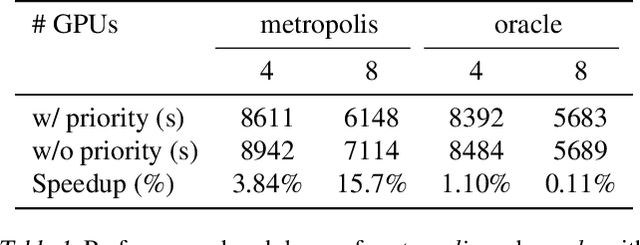
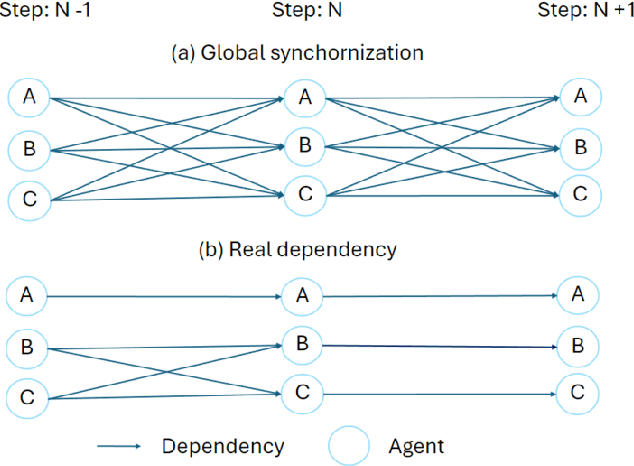
With more advanced natural language understanding and reasoning capabilities, large language model (LLM)-powered agents are increasingly developed in simulated environments to perform complex tasks, interact with other agents, and exhibit emergent behaviors relevant to social science and gaming. However, current multi-agent simulations frequently suffer from inefficiencies due to the limited parallelism caused by false dependencies, resulting in performance bottlenecks. In this paper, we introduce AI Metropolis, a simulation engine that improves the efficiency of LLM agent simulations by incorporating out-of-order execution scheduling. By dynamically tracking real dependencies between agents, AI Metropolis minimizes false dependencies, enhancing parallelism and enabling efficient hardware utilization. Our evaluations demonstrate that AI Metropolis achieves speedups from 1.3x to 4.15x over standard parallel simulation with global synchronization, approaching optimal performance as the number of agents increases.
Cloud Atlas: Efficient Fault Localization for Cloud Systems using Language Models and Causal Insight
Jul 11, 2024Runtime failure and performance degradation is commonplace in modern cloud systems. For cloud providers, automatically determining the root cause of incidents is paramount to ensuring high reliability and availability as prompt fault localization can enable faster diagnosis and triage for timely resolution. A compelling solution explored in recent work is causal reasoning using causal graphs to capture relationships between varied cloud system performance metrics. To be effective, however, systems developers must correctly define the causal graph of their system, which is a time-consuming, brittle, and challenging task that increases in difficulty for large and dynamic systems and requires domain expertise. Alternatively, automated data-driven approaches have limited efficacy for cloud systems due to the inherent rarity of incidents. In this work, we present Atlas, a novel approach to automatically synthesizing causal graphs for cloud systems. Atlas leverages large language models (LLMs) to generate causal graphs using system documentation, telemetry, and deployment feedback. Atlas is complementary to data-driven causal discovery techniques, and we further enhance Atlas with a data-driven validation step. We evaluate Atlas across a range of fault localization scenarios and demonstrate that Atlas is capable of generating causal graphs in a scalable and generalizable manner, with performance that far surpasses that of data-driven algorithms and is commensurate to the ground-truth baseline.
SlipStream: Adapting Pipelines for Distributed Training of Large DNNs Amid Failures
May 22, 2024



Training large Deep Neural Network (DNN) models requires thousands of GPUs for days or weeks at a time. At these scales, failures are frequent and can have a big impact on training throughput. Restoring performance using spare GPU servers becomes increasingly expensive as models grow. SlipStream is a system for efficient DNN training in the presence of failures, without using spare servers. It exploits the functional redundancy inherent in distributed training systems -- servers hold the same model parameters across data-parallel groups -- as well as the bubbles in the pipeline schedule within each data-parallel group. SlipStream dynamically re-routes the work of a failed server to its data-parallel peers, ensuring continuous training despite multiple failures. However, re-routing work leads to imbalances across pipeline stages that degrades training throughput. SlipStream introduces two optimizations that allow re-routed work to execute within bubbles of the original pipeline schedule. First, it decouples the backward pass computation into two phases. Second, it staggers the execution of the optimizer step across pipeline stages. Combined, these optimizations enable schedules that minimize or even eliminate training throughput degradation during failures. We describe a prototype for SlipStream and show that it achieves high training throughput under multiple failures, outperforming recent proposals for fault-tolerant training such as Oobleck and Bamboo by up to 1.46x and 1.64x, respectively.
cedar: Composable and Optimized Machine Learning Input Data Pipelines
Jan 25, 2024



The input data pipeline is an essential component of each machine learning (ML) training job. It is responsible for reading massive amounts of training data, processing batches of samples using complex transformations, and loading them onto training nodes at low latency and high throughput. Performant input data systems are becoming increasingly critical, driven by skyrocketing data volumes and training throughput demands. Unfortunately, current input data systems cannot fully leverage key performance optimizations, resulting in hugely inefficient infrastructures that require significant resources -- or worse -- underutilize expensive accelerators. To address these demands, we present cedar, a programming model and framework that allows users to easily build, optimize, and execute input data pipelines. cedar presents an easy-to-use programming interface, allowing users to define input data pipelines using composable operators that support arbitrary ML frameworks and libraries. Meanwhile, cedar transparently applies a complex and extensible set of optimization techniques (e.g., offloading, caching, prefetching, fusion, and reordering). It then orchestrates processing across a customizable set of local and distributed compute resources in order to maximize processing performance and efficiency, all without user input. On average across six diverse input data pipelines, cedar achieves a 2.49x, 1.87x, 2.18x, and 2.74x higher performance compared to tf.data, tf.data service, Ray Data, and PyTorch's DataLoader, respectively.