 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexShard: Flexible Sharding for Industry-Scale Sequence Recommendation Models
Paper and Code
Jan 08, 2023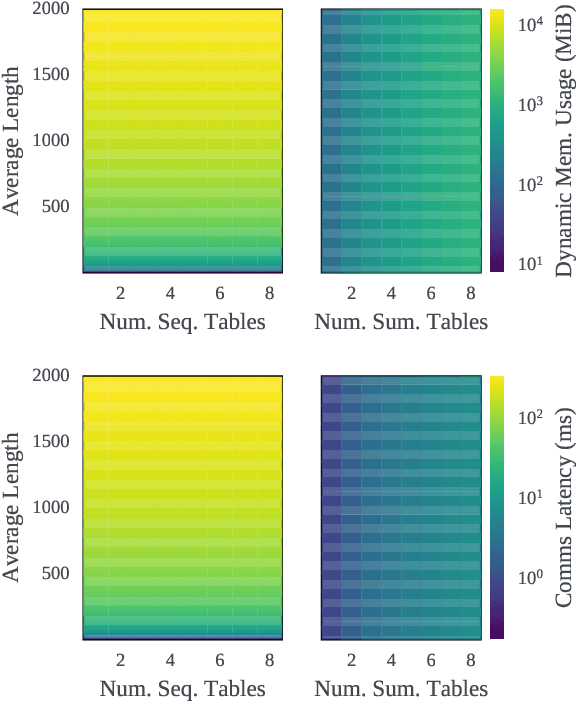

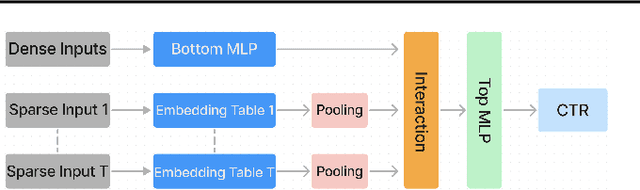
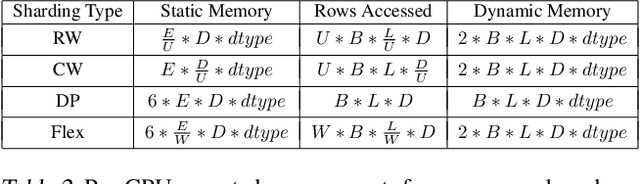
Sequence-based deep learning recommendation models (DLRMs) are an emerging class of DLRMs showing great improvements over their prior sum-pooling based counterparts at capturing users' long term interests. These improvements come at immense system cost however, with sequence-based DLRMs requiring substantial amounts of data to be dynamically materialized and communicated by each accelerator during a single iteration. To address this rapidly growing bottleneck, we present FlexShard, a new tiered sequence embedding table sharding algorithm which operates at a per-row granularity by exploiting the insight that not every row is equal. Through precise replication of embedding rows based on their underlying probability distribution, along with the introduction of a new sharding strategy adapted to the heterogeneous, skewed performance of real-world cluster network topologies, FlexShard is able to significantly reduce communication demand while using no additional memory compared to the prior state-of-the-art. When evaluated on production-scale sequence DLRMs, FlexShard was able to reduce overall global all-to-all communication traffic by over 85%, resulting in end-to-end training communication latency improvements of almost 6x over the prior state-of-the-art approach.