 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Training Video Foundation Models with NVIDIA NeMo
Mar 17, 2025Video Foundation Models (VFMs) have recently been used to simulate the real world to train physical AI systems and develop creative visual experiences. However, there are significant challenges in training large-scale, high quality VFMs that can generate high-quality videos. We present a scalable, open-source VFM training pipeline with NVIDIA NeMo, providing accelerated video dataset curation, multimodal data loading, and parallelized video diffusion model training and inference. We also provide a comprehensive performance analysis highlighting best practices for efficient VFM training and inference.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Apr 19, 2024



Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
FlexShard: Flexible Sharding for Industry-Scale Sequence Recommendation Models
Jan 08, 2023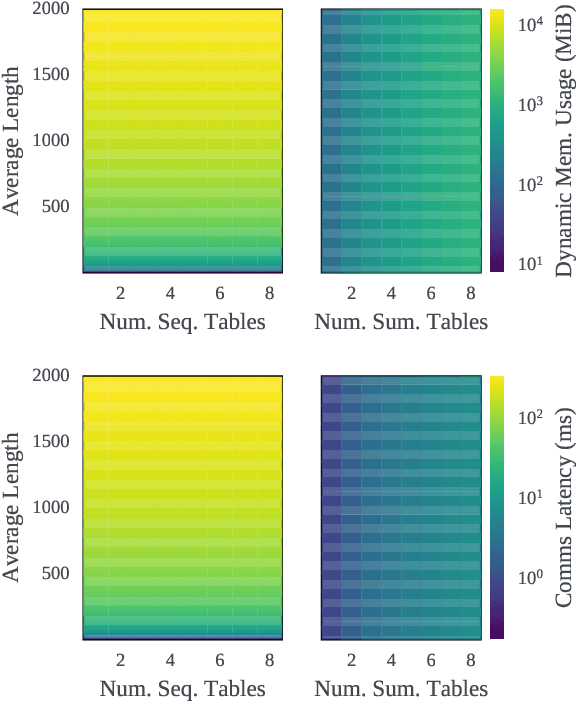

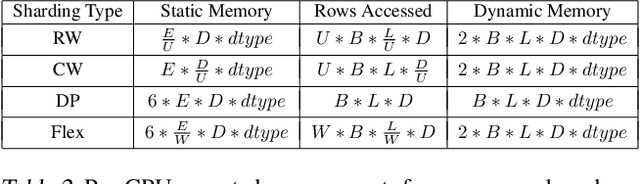
Sequence-based deep learning recommendation models (DLRMs) are an emerging class of DLRMs showing great improvements over their prior sum-pooling based counterparts at capturing users' long term interests. These improvements come at immense system cost however, with sequence-based DLRMs requiring substantial amounts of data to be dynamically materialized and communicated by each accelerator during a single iteration. To address this rapidly growing bottleneck, we present FlexShard, a new tiered sequence embedding table sharding algorithm which operates at a per-row granularity by exploiting the insight that not every row is equal. Through precise replication of embedding rows based on their underlying probability distribution, along with the introduction of a new sharding strategy adapted to the heterogeneous, skewed performance of real-world cluster network topologies, FlexShard is able to significantly reduce communication demand while using no additional memory compared to the prior state-of-the-art. When evaluated on production-scale sequence DLRMs, FlexShard was able to reduce overall global all-to-all communication traffic by over 85%, resulting in end-to-end training communication latency improvements of almost 6x over the prior state-of-the-art approach.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 15, 2021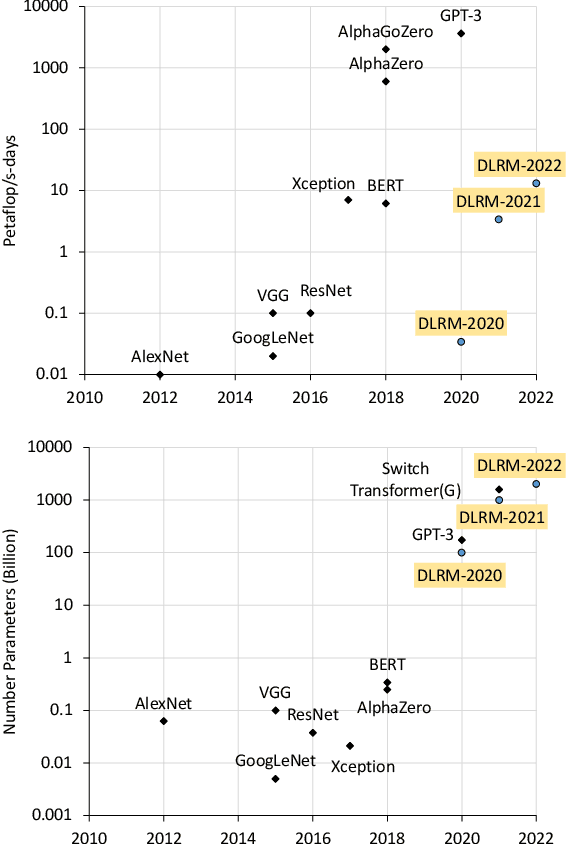

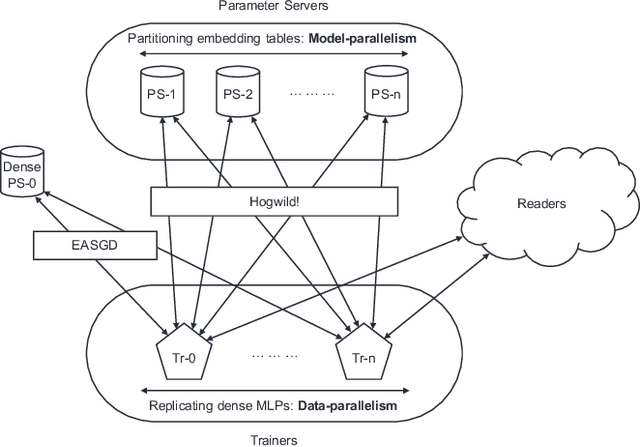
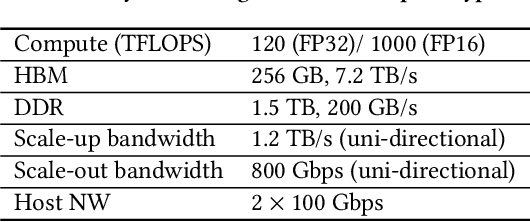
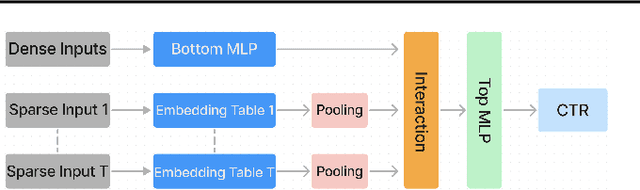
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of Zion platform, namely ZionEX. We demonstrate the capability to train very large DLRMs with up to 12 Trillion parameters and show that we can attain 40X speedup in terms of time to solution over previous systems. We achieve this by (i) designing the ZionEX platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
Removing Stripes, Scratches, and Curtaining with Non-Recoverable Compressed Sensing
Jan 23, 2019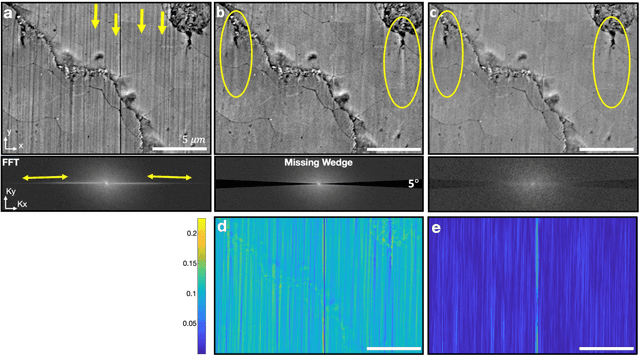

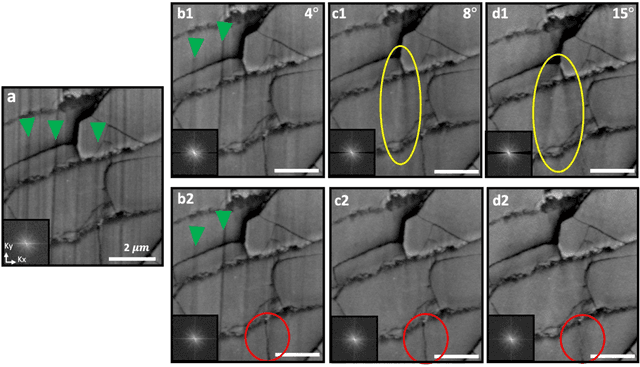

Highly-directional image artifacts such as ion mill curtaining, mechanical scratches, or image striping from beam instability degrade the interpretability of micrographs. These unwanted, aperiodic features extend the image along a primary direction and occupy a small wedge of information in Fourier space. Deleting this wedge of data replaces stripes, scratches, or curtaining, with more complex streaking and blurring artifacts-known within the tomography community as missing wedge artifacts. Here, we overcome this problem by recovering the missing region using total variation minimization, which leverages image sparsity based reconstruction techniques-colloquially referred to as compressed sensing-to reliably restore images corrupted by stripe like features. Our approach removes beam instability, ion mill curtaining, mechanical scratches, or any stripe features and remains robust at low signal-to-noise. The success of this approach is achieved by exploiting compressed sensings inability to recover directional structures that are highly localized and missing in Fourier Space.