 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
Training Video Foundation Models with NVIDIA NeMo
Mar 17, 2025Video Foundation Models (VFMs) have recently been used to simulate the real world to train physical AI systems and develop creative visual experiences. However, there are significant challenges in training large-scale, high quality VFMs that can generate high-quality videos. We present a scalable, open-source VFM training pipeline with NVIDIA NeMo, providing accelerated video dataset curation, multimodal data loading, and parallelized video diffusion model training and inference. We also provide a comprehensive performance analysis highlighting best practices for efficient VFM training and inference.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Llama 3 Meets MoE: Efficient Upcycling
Dec 13, 2024



Scaling large language models (LLMs) significantly improves performance but comes with prohibitive computational costs. Mixture-of-Experts (MoE) models offer an efficient alternative, increasing capacity without a proportional rise in compute requirements. However, training MoE models from scratch poses challenges like overfitting and routing instability. We present an efficient training recipe leveraging pre-trained dense checkpoints, training an 8-Expert Top-2 MoE model from Llama 3-8B with less than $1\%$ of typical pre-training compute. Our approach enhances downstream performance on academic benchmarks, achieving a $\textbf{2%}$ improvement in 0-shot accuracy on MMLU, while reaching a Model FLOPs Utilization (MFU) of $\textbf{46.8%}$ during training using our framework. We also integrate online upcycling in NeMo for seamless use of pre-trained weights, enabling cost-effective development of high-capacity MoE models.
Upcycling Large Language Models into Mixture of Experts
Oct 10, 2024



Upcycling pre-trained dense language models into sparse mixture-of-experts (MoE) models is an efficient approach to increase the model capacity of already trained models. However, optimal techniques for upcycling at scale remain unclear. In this work, we conduct an extensive study of upcycling methods and hyperparameters for billion-parameter scale language models. We propose a novel "virtual group" initialization scheme and weight scaling approach to enable upcycling into fine-grained MoE architectures. Through ablations, we find that upcycling outperforms continued dense model training. In addition, we show that softmax-then-topK expert routing improves over topK-then-softmax approach and higher granularity MoEs can help improve accuracy. Finally, we upcycled Nemotron-4 15B on 1T tokens and compared it to a continuously trained version of the same model on the same 1T tokens: the continuous trained model achieved 65.3% MMLU, whereas the upcycled model achieved 67.6%. Our results offer insights and best practices to effectively leverage upcycling for building MoE language models.
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Aug 21, 2024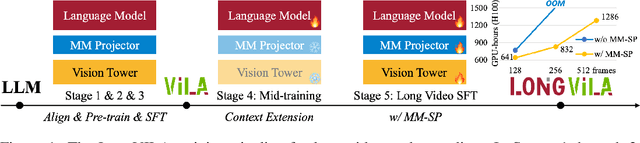

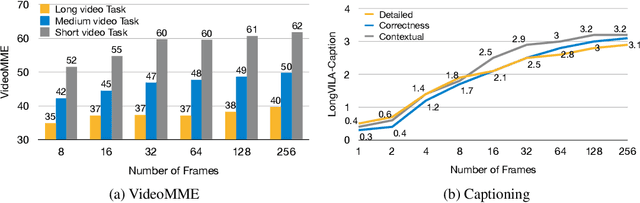
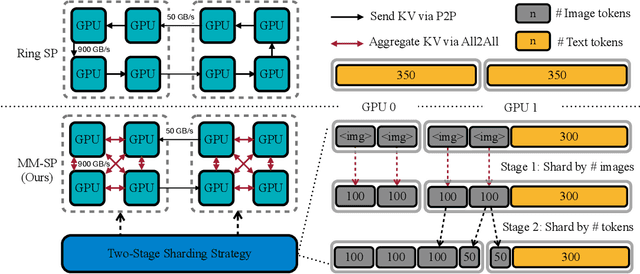
Long-context capability is critical for multi-modal foundation models, especially for long video understanding. We introduce LongVILA, a full-stack solution for long-context visual-language models by co-designing the algorithm and system. For model training, we upgrade existing VLMs to support long video understanding by incorporating two additional stages, i.e., long context extension and long supervised fine-tuning. However, training on long video is computationally and memory intensive. We introduce the long-context Multi-Modal Sequence Parallelism (MM-SP) system that efficiently parallelizes long video training and inference, enabling 2M context length training on 256 GPUs without any gradient checkpointing. LongVILA efficiently extends the number of video frames of VILA from 8 to 1024, improving the long video captioning score from 2.00 to 3.26 (out of 5), achieving 99.5% accuracy in 1400-frame (274k context length) video needle-in-a-haystack. LongVILA-8B demonstrates consistent accuracy improvements on long videos in the VideoMME benchmark as the number of frames increases. Besides, MM-SP is 2.1x - 5.7x faster than ring sequence parallelism and 1.1x - 1.4x faster than Megatron with context parallelism + tensor parallelism. Moreover, it seamlessly integrates with Hugging Face Transformers.