 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHide to Guide: Learning via Semantic Masking
May 24, 2026Reinforcement learning with verifiable rewards (RLVR) has become a powerful paradigm for improving language models on reasoning-intensive tasks, but its effectiveness is often limited by exploration. For example, models often fail on hard problems, leaving little useful reward signal. External expert traces offer a natural source of guidance, yet they may also expose reward-relevant content along the critical path to the verifier target, such as final answers, intermediate values, executable implementations, or answer-related entities. This content can create an unintended reward hacking channel, allowing the policy to obtain reward by copying the trace rather than learning the underlying reasoning or agentic behavior. Existing guided-RL methods reduce this risk by using partial trajectories, but they mainly control how much expert information is shown heuristically rather than which parts should be hidden. To this end, we propose Semantic Masked Expert Policy Optimization (SMEPO), a fine-grained semantic masking strategy for expert-guided RLVR. Instead of truncating traces coarsely or revealing them unchanged, SMEPO masks reward-relevant semantic spans along the critical path while preserving the expert's decomposition, plan, and procedural structure. This turns hard problems from reasoning from scratch into a fill-in-the-blank process: the policy can follow the expert's problem-solving route, but must still reconstruct the missing values, code, or entities by itself. SMEPO is simple to apply and requires no changes to the reward function or RL objective. Across diverse domains, including math, code, and agentic search, SMEPO improves accuracy by up to 3.2 points over GRPO and reduces training time by up to 4.2x. The code is available at https://github.com/mit-han-lab/SMEPO.
Stable Asynchrony: Variance-Controlled Off-Policy RL for LLMs
Feb 19, 2026Reinforcement learning (RL) is widely used to improve large language models on reasoning tasks, and asynchronous RL training is attractive because it increases end-to-end throughput. However, for widely adopted critic-free policy-gradient methods such as REINFORCE and GRPO, high asynchrony makes the policy-gradient estimator markedly $\textbf{higher variance}$: training on stale rollouts creates heavy-tailed importance ratios, causing a small fraction of samples to dominate updates. This amplification makes gradients noisy and learning unstable relative to matched on-policy training. Across math and general reasoning benchmarks, we find collapse is reliably predicted by effective sample size (ESS) and unstable gradient norms. Motivated by this diagnosis, we propose $\textbf{V}$ariance $\textbf{C}$ontrolled $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{VCPO}$), a general stabilization method for REINFORCE/GRPO-style algorithms that (i) scales learning rate based on effective sample size to dampen unreliable updates, and (ii) applies a closed-form minimum-variance baseline for the off-policy setting, avoiding an auxiliary value model and adding minimal overhead. Empirically, VCPO substantially improves robustness for asynchronous training across math, general reasoning, and tool-use tasks, outperforming a broad suite of baselines spanning masking/clipping stabilizers and algorithmic variants. This reduces long-context, multi-turn training time by 2.5$\times$ while matching synchronous performance, demonstrating that explicit control of policy-gradient variance is key for reliable asynchronous RL at scale.
ForeAct: Steering Your VLA with Efficient Visual Foresight Planning
Feb 12, 2026Vision-Language-Action (VLA) models convert high-level language instructions into concrete, executable actions, a task that is especially challenging in open-world environments. We present Visual Foresight Planning (ForeAct), a general and efficient planner that guides a VLA step-by-step using imagined future observations and subtask descriptions. With an imagined future observation, the VLA can focus on visuo-motor inference rather than high-level semantic reasoning, leading to improved accuracy and generalization. Our planner comprises a highly efficient foresight image generation module that predicts a high-quality 640$\times$480 future observation from the current visual input and language instruction within only 0.33s on an H100 GPU, together with a vision-language model that reasons over the task and produces subtask descriptions for both the generator and the VLA. Importantly, state-of-the-art VLAs can integrate our planner seamlessly by simply augmenting their visual inputs, without any architectural modification. The foresight generator is pretrained on over 1 million multi-task, cross-embodiment episodes, enabling it to learn robust embodied dynamics. We evaluate our framework on a benchmark that consists of 11 diverse, multi-step real-world tasks. It achieves an average success rate of 87.4%, demonstrating a +40.9% absolute improvement over the $π_0$ baseline (46.5%) and a +30.3% absolute improvement over $π_0$ augmented with textual subtask guidance (57.1%).
Locality-aware Parallel Decoding for Efficient Autoregressive Image Generation
Jul 02, 2025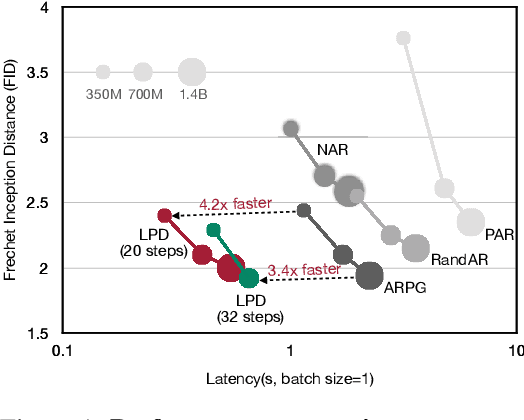



We present Locality-aware Parallel Decoding (LPD) to accelerate autoregressive image generation. Traditional autoregressive image generation relies on next-patch prediction, a memory-bound process that leads to high latency. Existing works have tried to parallelize next-patch prediction by shifting to multi-patch prediction to accelerate the process, but only achieved limited parallelization. To achieve high parallelization while maintaining generation quality, we introduce two key techniques: (1) Flexible Parallelized Autoregressive Modeling, a novel architecture that enables arbitrary generation ordering and degrees of parallelization. It uses learnable position query tokens to guide generation at target positions while ensuring mutual visibility among concurrently generated tokens for consistent parallel decoding. (2) Locality-aware Generation Ordering, a novel schedule that forms groups to minimize intra-group dependencies and maximize contextual support, enhancing generation quality. With these designs, we reduce the generation steps from 256 to 20 (256$\times$256 res.) and 1024 to 48 (512$\times$512 res.) without compromising quality on the ImageNet class-conditional generation, and achieving at least 3.4$\times$ lower latency than previous parallelized autoregressive models.
LServe: Efficient Long-sequence LLM Serving with Unified Sparse Attention
Feb 20, 2025Large language models (LLMs) have shown remarkable potential in processing long sequences, yet efficiently serving these long-context models remains challenging due to the quadratic computational complexity of attention in the prefilling stage and the large memory footprint of the KV cache in the decoding stage. To address these issues, we introduce LServe, an efficient system that accelerates long-sequence LLM serving via hybrid sparse attention. This method unifies different hardware-friendly, structured sparsity patterns for both prefilling and decoding attention into a single framework, where computations on less important tokens are skipped block-wise. LServe demonstrates the compatibility of static and dynamic sparsity in long-context LLM attention. This design enables multiplicative speedups by combining these optimizations. Specifically, we convert half of the attention heads to nearly free streaming heads in both the prefilling and decoding stages. Additionally, we find that only a constant number of KV pages is required to preserve long-context capabilities, irrespective of context length. We then design a hierarchical KV page selection policy that dynamically prunes KV pages based on query-centric similarity. On average, LServe accelerates LLM prefilling by up to 2.9x and decoding by 1.3-2.1x over vLLM, maintaining long-context accuracy. Code is released at https://github.com/mit-han-lab/omniserve.
NVILA: Efficient Frontier Visual Language Models
Dec 05, 2024
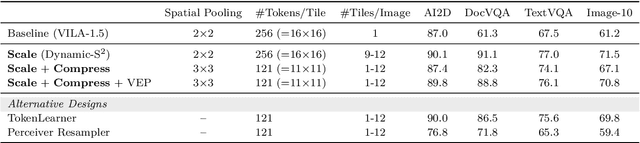

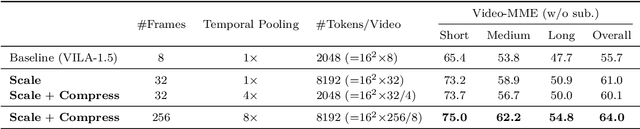
Visual language models (VLMs) have made significant advances in accuracy in recent years. However, their efficiency has received much less attention. This paper introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy. Building on top of VILA, we improve its model architecture by first scaling up the spatial and temporal resolutions, and then compressing visual tokens. This "scale-then-compress" approach enables NVILA to efficiently process high-resolution images and long videos. We also conduct a systematic investigation to enhance the efficiency of NVILA throughout its entire lifecycle, from training and fine-tuning to deployment. NVILA matches or surpasses the accuracy of many leading open and proprietary VLMs across a wide range of image and video benchmarks. At the same time, it reduces training costs by 4.5X, fine-tuning memory usage by 3.4X, pre-filling latency by 1.6-2.2X, and decoding latency by 1.2-2.8X. We will soon make our code and models available to facilitate reproducibility.
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Oct 14, 2024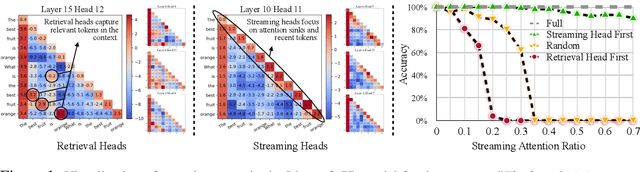
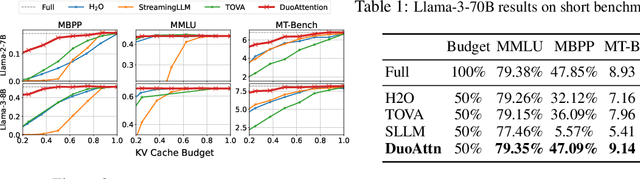
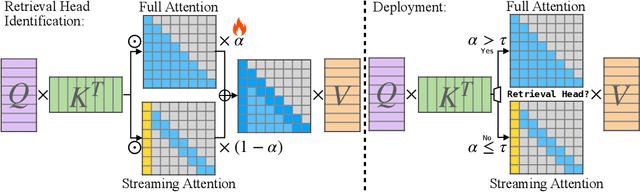

Deploying long-context large language models (LLMs) is essential but poses significant computational and memory challenges. Caching all Key and Value (KV) states across all attention heads consumes substantial memory. Existing KV cache pruning methods either damage the long-context capabilities of LLMs or offer only limited efficiency improvements. In this paper, we identify that only a fraction of attention heads, a.k.a, Retrieval Heads, are critical for processing long contexts and require full attention across all tokens. In contrast, all other heads, which primarily focus on recent tokens and attention sinks--referred to as Streaming Heads--do not require full attention. Based on this insight, we introduce DuoAttention, a framework that only applies a full KV cache to retrieval heads while using a light-weight, constant-length KV cache for streaming heads, which reduces both LLM's decoding and pre-filling memory and latency without compromising its long-context abilities. DuoAttention uses a lightweight, optimization-based algorithm with synthetic data to identify retrieval heads accurately. Our method significantly reduces long-context inference memory by up to 2.55x for MHA and 1.67x for GQA models while speeding up decoding by up to 2.18x and 1.50x and accelerating pre-filling by up to 1.73x and 1.63x for MHA and GQA models, respectively, with minimal accuracy loss compared to full attention. Notably, combined with quantization, DuoAttention enables Llama-3-8B decoding with 3.3 million context length on a single A100 GPU. Code is provided in https://github.com/mit-han-lab/duo-attention.
HART: Efficient Visual Generation with Hybrid Autoregressive Transformer
Oct 14, 2024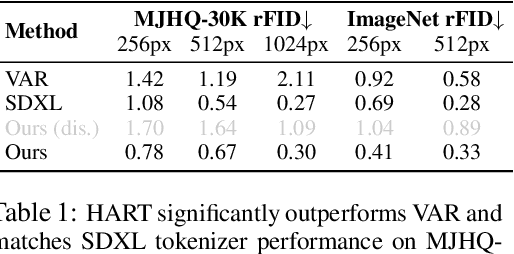

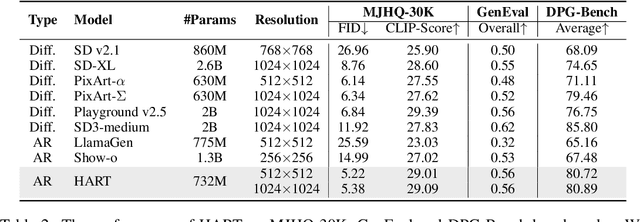

We introduce Hybrid Autoregressive Transformer (HART), an autoregressive (AR) visual generation model capable of directly generating 1024x1024 images, rivaling diffusion models in image generation quality. Existing AR models face limitations due to the poor image reconstruction quality of their discrete tokenizers and the prohibitive training costs associated with generating 1024px images. To address these challenges, we present the hybrid tokenizer, which decomposes the continuous latents from the autoencoder into two components: discrete tokens representing the big picture and continuous tokens representing the residual components that cannot be represented by the discrete tokens. The discrete component is modeled by a scalable-resolution discrete AR model, while the continuous component is learned with a lightweight residual diffusion module with only 37M parameters. Compared with the discrete-only VAR tokenizer, our hybrid approach improves reconstruction FID from 2.11 to 0.30 on MJHQ-30K, leading to a 31% generation FID improvement from 7.85 to 5.38. HART also outperforms state-of-the-art diffusion models in both FID and CLIP score, with 4.5-7.7x higher throughput and 6.9-13.4x lower MACs. Our code is open sourced at https://github.com/mit-han-lab/hart.
Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
Oct 14, 2024
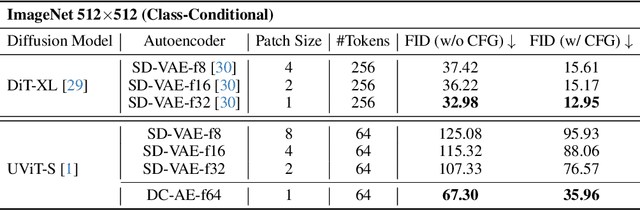
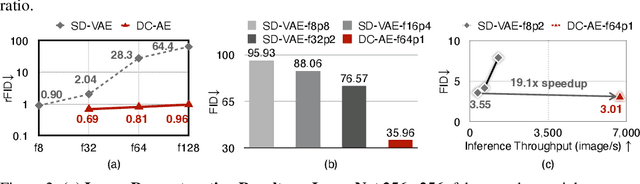
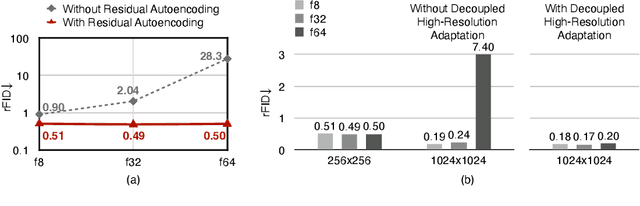
We present Deep Compression Autoencoder (DC-AE), a new family of autoencoder models for accelerating high-resolution diffusion models. Existing autoencoder models have demonstrated impressive results at a moderate spatial compression ratio (e.g., 8x), but fail to maintain satisfactory reconstruction accuracy for high spatial compression ratios (e.g., 64x). We address this challenge by introducing two key techniques: (1) Residual Autoencoding, where we design our models to learn residuals based on the space-to-channel transformed features to alleviate the optimization difficulty of high spatial-compression autoencoders; (2) Decoupled High-Resolution Adaptation, an efficient decoupled three-phases training strategy for mitigating the generalization penalty of high spatial-compression autoencoders. With these designs, we improve the autoencoder's spatial compression ratio up to 128 while maintaining the reconstruction quality. Applying our DC-AE to latent diffusion models, we achieve significant speedup without accuracy drop. For example, on ImageNet 512x512, our DC-AE provides 19.1x inference speedup and 17.9x training speedup on H100 GPU for UViT-H while achieving a better FID, compared with the widely used SD-VAE-f8 autoencoder. Our code is available at https://github.com/mit-han-lab/efficientvit.
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Aug 21, 2024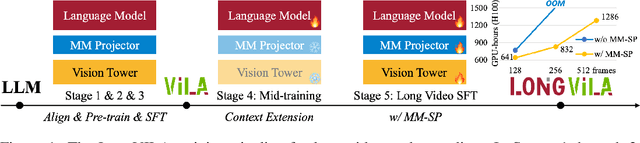

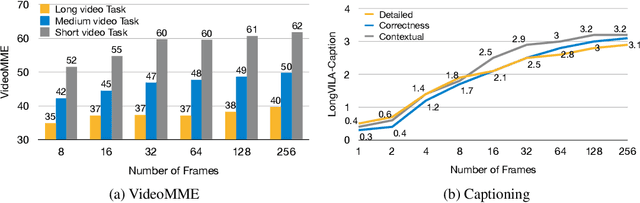
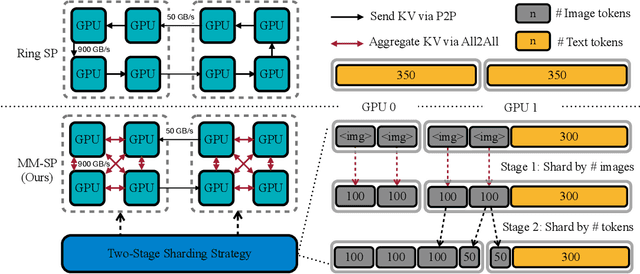
Long-context capability is critical for multi-modal foundation models, especially for long video understanding. We introduce LongVILA, a full-stack solution for long-context visual-language models by co-designing the algorithm and system. For model training, we upgrade existing VLMs to support long video understanding by incorporating two additional stages, i.e., long context extension and long supervised fine-tuning. However, training on long video is computationally and memory intensive. We introduce the long-context Multi-Modal Sequence Parallelism (MM-SP) system that efficiently parallelizes long video training and inference, enabling 2M context length training on 256 GPUs without any gradient checkpointing. LongVILA efficiently extends the number of video frames of VILA from 8 to 1024, improving the long video captioning score from 2.00 to 3.26 (out of 5), achieving 99.5% accuracy in 1400-frame (274k context length) video needle-in-a-haystack. LongVILA-8B demonstrates consistent accuracy improvements on long videos in the VideoMME benchmark as the number of frames increases. Besides, MM-SP is 2.1x - 5.7x faster than ring sequence parallelism and 1.1x - 1.4x faster than Megatron with context parallelism + tensor parallelism. Moreover, it seamlessly integrates with Hugging Face Transformers.