 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Block-Scaled Data Types
Mar 30, 2026NVFP4 has grown increasingly popular as a 4-bit format for quantizing large language models due to its hardware support and its ability to retain useful information with relatively few bits per parameter. However, the format is not without limitations: recent work has shown that NVFP4 suffers from its error distribution, resulting in large amounts of quantization error on near-maximal values in each group of 16 values. In this work, we leverage this insight to design new Adaptive Block-Scaled Data Types that can adapt to the distribution of their input values. For four-bit quantization, our proposed IF4 (Int/Float 4) data type selects between FP4 and INT4 representations for each group of 16 values, which are then scaled by an E4M3 scale factor as is done with NVFP4. The selected data type is denoted using the scale factor's sign bit, which is currently unused in NVFP4, and we apply the same insight to design formats for other bit-widths, including IF3 and IF6. When used to quantize language models, we find that IF4 outperforms existing 4-bit block-scaled formats, achieving lower loss during quantized training and achieving higher accuracy on many tasks in post-training quantization. We additionally design and evaluate an IF4 Multiply-Accumulate (MAC) unit to demonstrate that IF4 can be implemented efficiently in next-generation hardware accelerators. Our code is available at https://github.com/mit-han-lab/fouroversix.
Optimizing Mixture of Block Attention
Nov 14, 2025Mixture of Block Attention (MoBA) (Lu et al., 2025) is a promising building block for efficiently processing long contexts in LLMs by enabling queries to sparsely attend to a small subset of key-value blocks, drastically reducing computational cost. However, the design principles governing MoBA's performance are poorly understood, and it lacks an efficient GPU implementation, hindering its practical adoption. In this paper, we first develop a statistical model to analyze MoBA's underlying mechanics. Our model reveals that performance critically depends on the router's ability to accurately distinguish relevant from irrelevant blocks based on query-key affinities. We derive a signal-to-noise ratio that formally connects architectural parameters to this retrieval accuracy. Guided by our analysis, we identify two key pathways for improvement: using smaller block sizes and applying a short convolution on keys to cluster relevant signals, which enhances routing accuracy. While theoretically better, small block sizes are inefficient on GPUs. To bridge this gap, we introduce FlashMoBA, a hardware-aware CUDA kernel that enables efficient MoBA execution even with the small block sizes our theory recommends. We validate our insights by training LLMs from scratch, showing that our improved MoBA models match the performance of dense attention baselines. FlashMoBA achieves up to 14.7x speedup over FlashAttention-2 for small blocks, making our theoretically-grounded improvements practical. Code is available at: https://github.com/mit-han-lab/flash-moba.
XAttention: Block Sparse Attention with Antidiagonal Scoring
Mar 20, 2025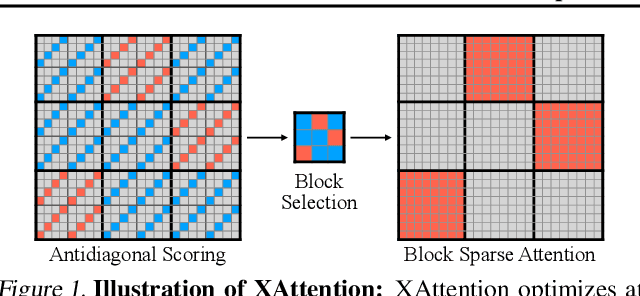
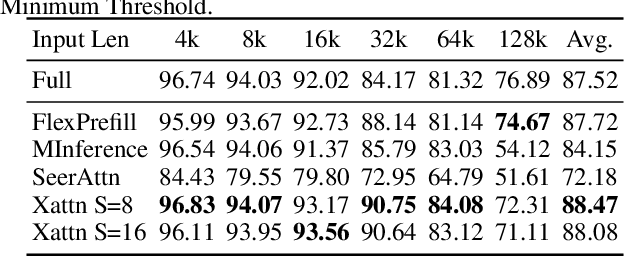
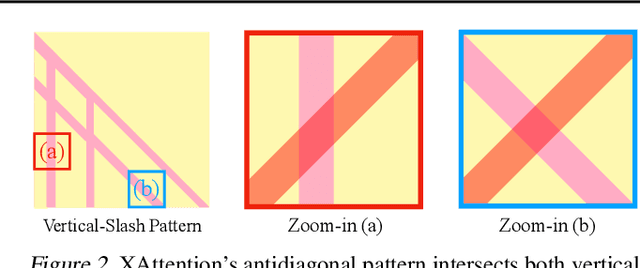
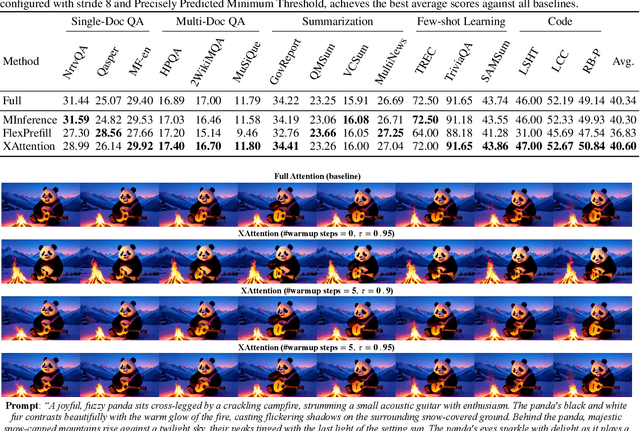
Long-Context Transformer Models (LCTMs) are vital for real-world applications but suffer high computational costs due to attention's quadratic complexity. Block-sparse attention mitigates this by focusing computation on critical regions, yet existing methods struggle with balancing accuracy and efficiency due to costly block importance measurements. In this paper, we introduce XAttention, a plug-and-play framework that dramatically accelerates long-context inference in Transformers models using sparse attention. XAttention's key innovation is the insight that the sum of antidiagonal values (i.e., from the lower-left to upper-right) in the attention matrix provides a powerful proxy for block importance. This allows for precise identification and pruning of non-essential blocks, resulting in high sparsity and dramatically accelerated inference. Across comprehensive evaluations on demanding long-context benchmarks-including RULER and LongBench for language, VideoMME for video understanding, and VBench for video generation. XAttention achieves accuracy comparable to full attention while delivering substantial computational gains. We demonstrate up to 13.5x acceleration in attention computation. These results underscore XAttention's ability to unlock the practical potential of block sparse attention, paving the way for scalable and efficient deployment of LCTMs in real-world applications. Code is available at https://github.com/mit-han-lab/x-attention.
LServe: Efficient Long-sequence LLM Serving with Unified Sparse Attention
Feb 20, 2025Large language models (LLMs) have shown remarkable potential in processing long sequences, yet efficiently serving these long-context models remains challenging due to the quadratic computational complexity of attention in the prefilling stage and the large memory footprint of the KV cache in the decoding stage. To address these issues, we introduce LServe, an efficient system that accelerates long-sequence LLM serving via hybrid sparse attention. This method unifies different hardware-friendly, structured sparsity patterns for both prefilling and decoding attention into a single framework, where computations on less important tokens are skipped block-wise. LServe demonstrates the compatibility of static and dynamic sparsity in long-context LLM attention. This design enables multiplicative speedups by combining these optimizations. Specifically, we convert half of the attention heads to nearly free streaming heads in both the prefilling and decoding stages. Additionally, we find that only a constant number of KV pages is required to preserve long-context capabilities, irrespective of context length. We then design a hierarchical KV page selection policy that dynamically prunes KV pages based on query-centric similarity. On average, LServe accelerates LLM prefilling by up to 2.9x and decoding by 1.3-2.1x over vLLM, maintaining long-context accuracy. Code is released at https://github.com/mit-han-lab/omniserve.
SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
Nov 07, 2024



Diffusion models have been proven highly effective at generating high-quality images. However, as these models grow larger, they require significantly more memory and suffer from higher latency, posing substantial challenges for deployment. In this work, we aim to accelerate diffusion models by quantizing their weights and activations to 4 bits. At such an aggressive level, both weights and activations are highly sensitive, where conventional post-training quantization methods for large language models like smoothing become insufficient. To overcome this limitation, we propose SVDQuant, a new 4-bit quantization paradigm. Different from smoothing which redistributes outliers between weights and activations, our approach absorbs these outliers using a low-rank branch. We first consolidate the outliers by shifting them from activations to weights, then employ a high-precision low-rank branch to take in the weight outliers with Singular Value Decomposition (SVD). This process eases the quantization on both sides. However, na\"{\i}vely running the low-rank branch independently incurs significant overhead due to extra data movement of activations, negating the quantization speedup. To address this, we co-design an inference engine Nunchaku that fuses the kernels of the low-rank branch into those of the low-bit branch to cut off redundant memory access. It can also seamlessly support off-the-shelf low-rank adapters (LoRAs) without the need for re-quantization. Extensive experiments on SDXL, PixArt-$\Sigma$, and FLUX.1 validate the effectiveness of SVDQuant in preserving image quality. We reduce the memory usage for the 12B FLUX.1 models by 3.5$\times$, achieving 3.0$\times$ speedup over the 4-bit weight-only quantized baseline on the 16GB laptop 4090 GPU, paving the way for more interactive applications on PCs. Our quantization library and inference engine are open-sourced.
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Oct 14, 2024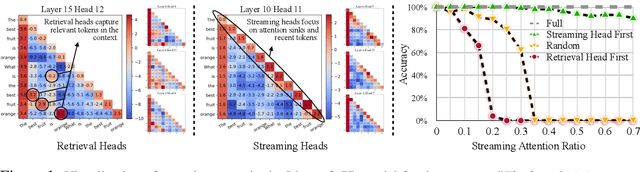
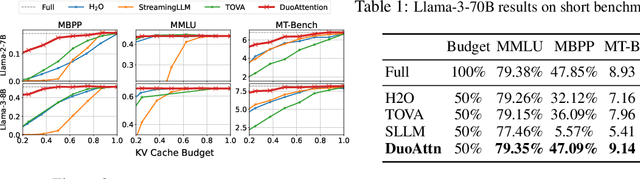
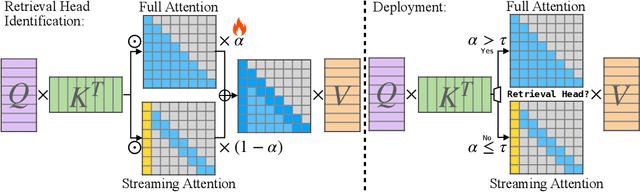

Deploying long-context large language models (LLMs) is essential but poses significant computational and memory challenges. Caching all Key and Value (KV) states across all attention heads consumes substantial memory. Existing KV cache pruning methods either damage the long-context capabilities of LLMs or offer only limited efficiency improvements. In this paper, we identify that only a fraction of attention heads, a.k.a, Retrieval Heads, are critical for processing long contexts and require full attention across all tokens. In contrast, all other heads, which primarily focus on recent tokens and attention sinks--referred to as Streaming Heads--do not require full attention. Based on this insight, we introduce DuoAttention, a framework that only applies a full KV cache to retrieval heads while using a light-weight, constant-length KV cache for streaming heads, which reduces both LLM's decoding and pre-filling memory and latency without compromising its long-context abilities. DuoAttention uses a lightweight, optimization-based algorithm with synthetic data to identify retrieval heads accurately. Our method significantly reduces long-context inference memory by up to 2.55x for MHA and 1.67x for GQA models while speeding up decoding by up to 2.18x and 1.50x and accelerating pre-filling by up to 1.73x and 1.63x for MHA and GQA models, respectively, with minimal accuracy loss compared to full attention. Notably, combined with quantization, DuoAttention enables Llama-3-8B decoding with 3.3 million context length on a single A100 GPU. Code is provided in https://github.com/mit-han-lab/duo-attention.