 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamingVLM: Real-Time Understanding for Infinite Video Streams
Oct 10, 2025Vision-language models (VLMs) could power real-time assistants and autonomous agents, but they face a critical challenge: understanding near-infinite video streams without escalating latency and memory usage. Processing entire videos with full attention leads to quadratic computational costs and poor performance on long videos. Meanwhile, simple sliding window methods are also flawed, as they either break coherence or suffer from high latency due to redundant recomputation. In this paper, we introduce StreamingVLM, a model designed for real-time, stable understanding of infinite visual input. Our approach is a unified framework that aligns training with streaming inference. During inference, we maintain a compact KV cache by reusing states of attention sinks, a short window of recent vision tokens, and a long window of recent text tokens. This streaming ability is instilled via a simple supervised fine-tuning (SFT) strategy that applies full attention on short, overlapped video chunks, which effectively mimics the inference-time attention pattern without training on prohibitively long contexts. For evaluation, we build Inf-Streams-Eval, a new benchmark with videos averaging over two hours that requires dense, per-second alignment between frames and text. On Inf-Streams-Eval, StreamingVLM achieves a 66.18% win rate against GPT-4O mini and maintains stable, real-time performance at up to 8 FPS on a single NVIDIA H100. Notably, our SFT strategy also enhances general VQA abilities without any VQA-specific fine-tuning, improving performance on LongVideoBench by +4.30 and OVOBench Realtime by +5.96. Code is available at https://github.com/mit-han-lab/streaming-vlm.
XAttention: Block Sparse Attention with Antidiagonal Scoring
Mar 20, 2025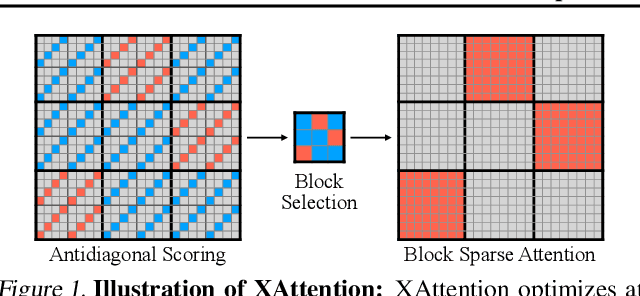
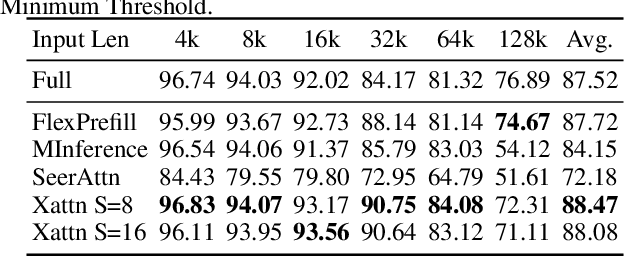
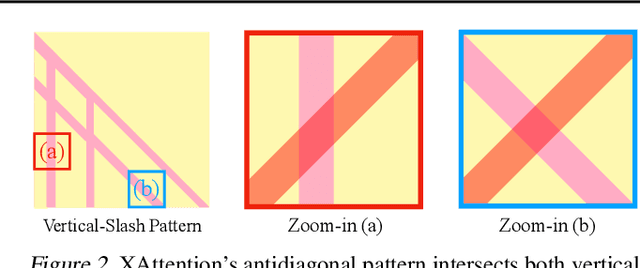
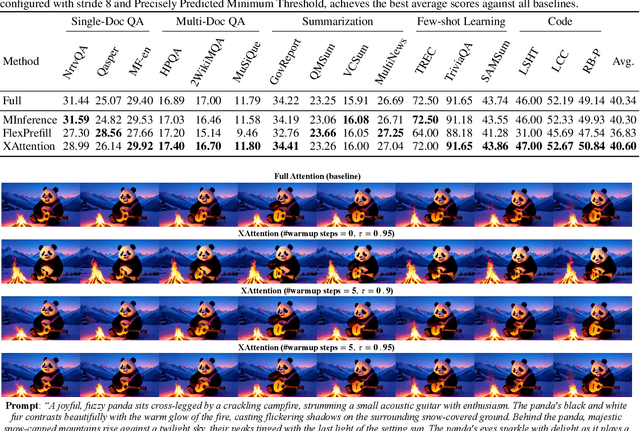
Long-Context Transformer Models (LCTMs) are vital for real-world applications but suffer high computational costs due to attention's quadratic complexity. Block-sparse attention mitigates this by focusing computation on critical regions, yet existing methods struggle with balancing accuracy and efficiency due to costly block importance measurements. In this paper, we introduce XAttention, a plug-and-play framework that dramatically accelerates long-context inference in Transformers models using sparse attention. XAttention's key innovation is the insight that the sum of antidiagonal values (i.e., from the lower-left to upper-right) in the attention matrix provides a powerful proxy for block importance. This allows for precise identification and pruning of non-essential blocks, resulting in high sparsity and dramatically accelerated inference. Across comprehensive evaluations on demanding long-context benchmarks-including RULER and LongBench for language, VideoMME for video understanding, and VBench for video generation. XAttention achieves accuracy comparable to full attention while delivering substantial computational gains. We demonstrate up to 13.5x acceleration in attention computation. These results underscore XAttention's ability to unlock the practical potential of block sparse attention, paving the way for scalable and efficient deployment of LCTMs in real-world applications. Code is available at https://github.com/mit-han-lab/x-attention.
Hugging Rain Man: A Novel Facial Action Units Dataset for Analyzing Atypical Facial Expressions in Children with Autism Spectrum Disorder
Nov 21, 2024



Children with Autism Spectrum Disorder (ASD) often exhibit atypical facial expressions. However, the specific objective facial features that underlie this subjective perception remain unclear. In this paper, we introduce a novel dataset, Hugging Rain Man (HRM), which includes facial action units (AUs) manually annotated by FACS experts for both children with ASD and typical development (TD). The dataset comprises a rich collection of posed and spontaneous facial expressions, totaling approximately 130,000 frames, along with 22 AUs, 10 Action Descriptors (ADs), and atypicality ratings. A statistical analysis of static images from the HRM reveals significant differences between the ASD and TD groups across multiple AUs and ADs when displaying the same emotional expressions, confirming that participants with ASD tend to demonstrate more irregular and diverse expression patterns. Subsequently, a temporal regression method was presented to analyze atypicality of dynamic sequences, thereby bridging the gap between subjective perception and objective facial characteristics. Furthermore, baseline results for AU detection are provided for future research reference. This work not only contributes to our understanding of the unique facial expression characteristics associated with ASD but also provides potential tools for ASD early screening. Portions of the dataset, features, and pretrained models are accessible at: \url{https://github.com/Jonas-DL/Hugging-Rain-Man}.
LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images
Mar 18, 2024



Visual encoding constitutes the basis of large multimodal models (LMMs) in understanding the visual world. Conventional LMMs process images in fixed sizes and limited resolutions, while recent explorations in this direction are limited in adaptivity, efficiency, and even correctness. In this work, we first take GPT-4V and LLaVA-1.5 as representative examples and expose systematic flaws rooted in their visual encoding strategy. To address the challenges, we present LLaVA-UHD, a large multimodal model that can efficiently perceive images in any aspect ratio and high resolution. LLaVA-UHD includes three key components: (1) An image modularization strategy that divides native-resolution images into smaller variable-sized slices for efficient and extensible encoding, (2) a compression module that further condenses image tokens from visual encoders, and (3) a spatial schema to organize slice tokens for LLMs. Comprehensive experiments show that LLaVA-UHD outperforms established LMMs trained with 2-3 orders of magnitude more data on 9 benchmarks. Notably, our model built on LLaVA-1.5 336x336 supports 6 times larger (i.e., 672x1088) resolution images using only 94% inference computation, and achieves 6.4 accuracy improvement on TextVQA. Moreover, the model can be efficiently trained in academic settings, within 23 hours on 8 A100 GPUs (vs. 26 hours of LLaVA-1.5). We make the data and code publicly available at https://github.com/thunlp/LLaVA-UHD.