 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
Mar 13, 2026A recent cutting-edge topic in multimodal modeling is to unify visual comprehension and generation within a single model. However, the two tasks demand mismatched decoding regimes and visual representations, making it non-trivial to jointly optimize within a shared feature space. In this work, we present Cheers, a unified multimodal model that decouples patch-level details from semantic representations, thereby stabilizing semantics for multimodal understanding and improving fidelity for image generation via gated detail residuals. Cheers includes three key components: (i) a unified vision tokenizer that encodes and compresses image latent states into semantic tokens for efficient LLM conditioning, (ii) an LLM-based Transformer that unifies autoregressive decoding for text generation and diffusion decoding for image generation, and (iii) a cascaded flow matching head that decodes visual semantics first and then injects semantically gated detail residuals from the vision tokenizer to refine high-frequency content. Experiments on popular benchmarks demonstrate that Cheers matches or surpasses advanced UMMs in both visual understanding and generation. Cheers also achieves 4x token compression, enabling more efficient high-resolution image encoding and generation. Notably, Cheers outperforms the Tar-1.5B on the popular benchmarks GenEval and MMBench, while requiring only 20% of the training cost, indicating effective and efficient (i.e., 4x token compression) unified multimodal modeling. We will release all code and data for future research.
MERLIN: Building Low-SNR Robust Multimodal LLMs for Electromagnetic Signals
Mar 09, 2026The paradigm of Multimodal Large Language Models (MLLMs) offers a promising blueprint for advancing the electromagnetic (EM) domain. However, prevailing approaches often deviate from the native MLLM paradigm, instead using task-specific or pipelined architectures that lead to fundamental limitations in model performance and generalization. Fully realizing the MLLM potential in EM domain requires overcoming three main challenges: (1) Data. The scarcity of high-quality datasets with paired EM signals and descriptive text annotations used for MLLMs pre-training; (2) Benchmark. The absence of comprehensive benchmarks to systematically evaluate and compare the performance of models on EM signal-to-text tasks; (3) Model. A critical fragility in low Signal-to-Noise Ratio (SNR) environments, where critical signal features can be obscured, leading to significant performance degradation. To address these challenges, we introduce a tripartite contribution to establish a foundation for MLLMs in the EM domain. First, to overcome data scarcity, we construct and release EM-100k, a large-scale dataset comprising over 100,000 EM signal-text pairs. Second, to enable rigorous and standardized evaluation, we propose EM-Bench, the most comprehensive benchmark featuring diverse downstream tasks spanning from perception to reasoning. Finally, to tackle the core modeling challenge, we present MERLIN, a novel training framework designed not only to align low-level signal representations with high-level semantic text, but also to explicitly enhance model robustness and performance in challenging low-SNR environments. Comprehensive experiments validate our method, showing that MERLIN is state-of-the-art in the EM-Bench and exhibits remarkable robustness in low-SNR settings.
MM-UAVBench: How Well Do Multimodal Large Language Models See, Think, and Plan in Low-Altitude UAV Scenarios?
Dec 29, 2025While Multimodal Large Language Models (MLLMs) have exhibited remarkable general intelligence across diverse domains, their potential in low-altitude applications dominated by Unmanned Aerial Vehicles (UAVs) remains largely underexplored. Existing MLLM benchmarks rarely cover the unique challenges of low-altitude scenarios, while UAV-related evaluations mainly focus on specific tasks such as localization or navigation, without a unified evaluation of MLLMs'general intelligence. To bridge this gap, we present MM-UAVBench, a comprehensive benchmark that systematically evaluates MLLMs across three core capability dimensions-perception, cognition, and planning-in low-altitude UAV scenarios. MM-UAVBench comprises 19 sub-tasks with over 5.7K manually annotated questions, all derived from real-world UAV data collected from public datasets. Extensive experiments on 16 open-source and proprietary MLLMs reveal that current models struggle to adapt to the complex visual and cognitive demands of low-altitude scenarios. Our analyses further uncover critical bottlenecks such as spatial bias and multi-view understanding that hinder the effective deployment of MLLMs in UAV scenarios. We hope MM-UAVBench will foster future research on robust and reliable MLLMs for real-world UAV intelligence.
ProCLIP: Progressive Vision-Language Alignment via LLM-based Embedder
Oct 22, 2025The original CLIP text encoder is limited by a maximum input length of 77 tokens, which hampers its ability to effectively process long texts and perform fine-grained semantic understanding. In addition, the CLIP text encoder lacks support for multilingual inputs. All these limitations significantly restrict its applicability across a broader range of tasks. Recent studies have attempted to replace the CLIP text encoder with an LLM-based embedder to enhance its ability in processing long texts, multilingual understanding, and fine-grained semantic comprehension. However, because the representation spaces of LLMs and the vision-language space of CLIP are pretrained independently without alignment priors, direct alignment using contrastive learning can disrupt the intrinsic vision-language alignment in the CLIP image encoder, leading to an underutilization of the knowledge acquired during pre-training. To address this challenge, we propose ProCLIP, a curriculum learning-based progressive vision-language alignment framework to effectively align the CLIP image encoder with an LLM-based embedder. Specifically, ProCLIP first distills knowledge from CLIP's text encoder into the LLM-based embedder to leverage CLIP's rich pretrained knowledge while establishing initial alignment between the LLM embedder and CLIP image encoder. Subsequently, ProCLIP further aligns the CLIP image encoder with the LLM-based embedder through image-text contrastive tuning, employing self-distillation regularization to avoid overfitting. To achieve a more effective alignment, instance semantic alignment loss and embedding structure alignment loss are employed during representation inheritance and contrastive tuning. The Code is available at https://github.com/VisionXLab/ProCLIP.
EMind: A Foundation Model for Multi-task Electromagnetic Signals Understanding
Aug 26, 2025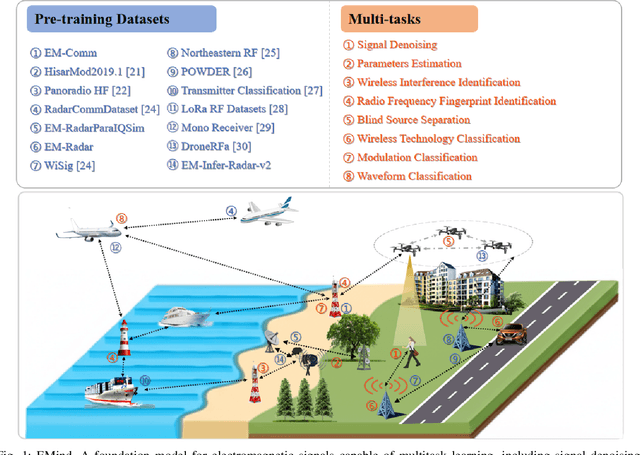
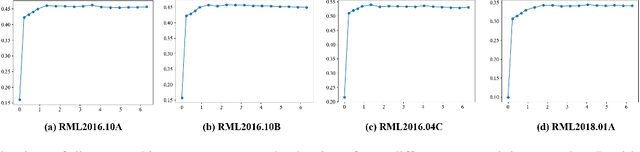
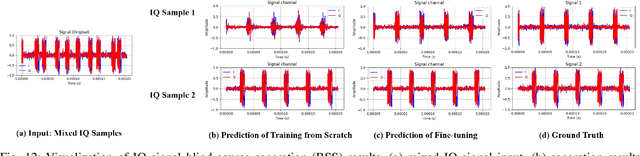
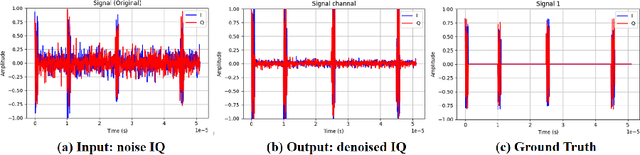
Deep understanding of electromagnetic signals is fundamental to dynamic spectrum management, intelligent transportation, autonomous driving and unmanned vehicle perception. The field faces challenges because electromagnetic signals differ greatly from text and images, showing high heterogeneity, strong background noise and complex joint time frequency structure, which prevents existing general models from direct use. Electromagnetic communication and sensing tasks are diverse, current methods lack cross task generalization and transfer efficiency, and the scarcity of large high quality datasets blocks the creation of a truly general multitask learning framework. To overcome these issue, we introduce EMind, an electromagnetic signals foundation model that bridges large scale pretraining and the unique nature of this modality. We build the first unified and largest standardized electromagnetic signal dataset covering multiple signal types and tasks. By exploiting the physical properties of electromagnetic signals, we devise a length adaptive multi-signal packing method and a hardware-aware training strategy that enable efficient use and representation learning from heterogeneous multi-source signals. Experiments show that EMind achieves strong performance and broad generalization across many downstream tasks, moving decisively from task specific models to a unified framework for electromagnetic intelligence. The code is available at: https://github.com/GabrielleTse/EMind.
GeoLLaVA-8K: Scaling Remote-Sensing Multimodal Large Language Models to 8K Resolution
May 27, 2025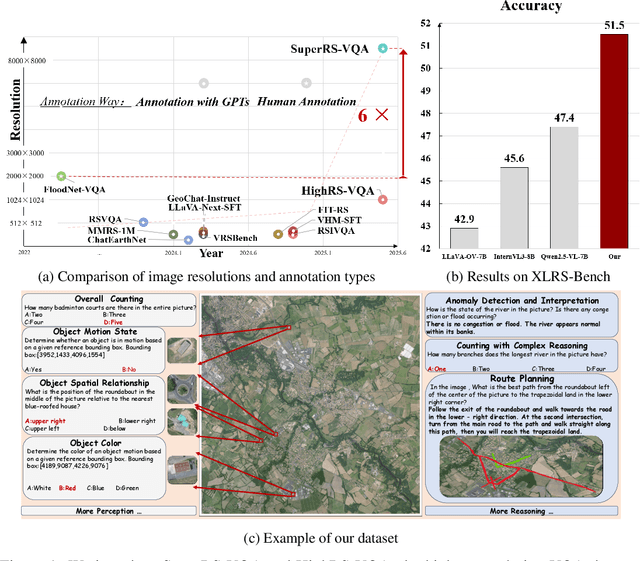
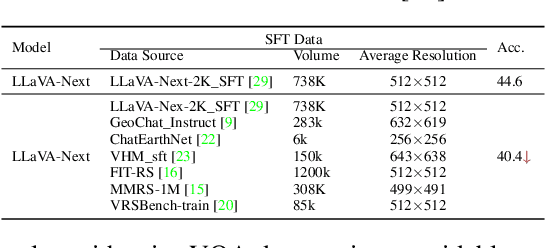
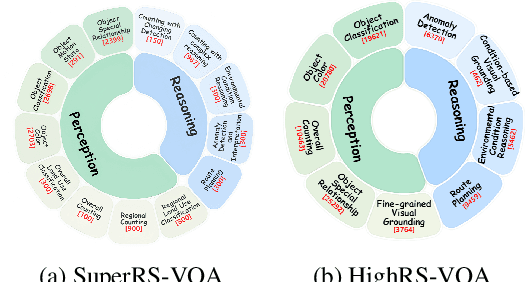
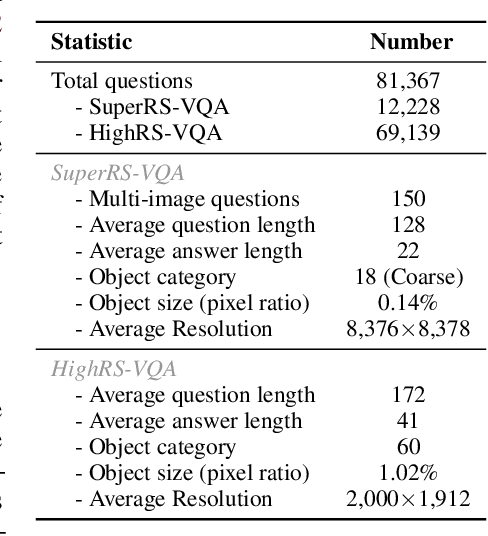
Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,376$\times$8,376) and HighRS-VQA (avg. 2,000$\times$1,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key semantics.Integrating these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K$\times$8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.
XLRS-Bench: Could Your Multimodal LLMs Understand Extremely Large Ultra-High-Resolution Remote Sensing Imagery?
Mar 31, 2025The astonishing breakthrough of multimodal large language models (MLLMs) has necessitated new benchmarks to quantitatively assess their capabilities, reveal their limitations, and indicate future research directions. However, this is challenging in the context of remote sensing (RS), since the imagery features ultra-high resolution that incorporates extremely complex semantic relationships. Existing benchmarks usually adopt notably smaller image sizes than real-world RS scenarios, suffer from limited annotation quality, and consider insufficient dimensions of evaluation. To address these issues, we present XLRS-Bench: a comprehensive benchmark for evaluating the perception and reasoning capabilities of MLLMs in ultra-high-resolution RS scenarios. XLRS-Bench boasts the largest average image size (8500$\times$8500) observed thus far, with all evaluation samples meticulously annotated manually, assisted by a novel semi-automatic captioner on ultra-high-resolution RS images. On top of the XLRS-Bench, 16 sub-tasks are defined to evaluate MLLMs' 10 kinds of perceptual capabilities and 6 kinds of reasoning capabilities, with a primary emphasis on advanced cognitive processes that facilitate real-world decision-making and the capture of spatiotemporal changes. The results of both general and RS-focused MLLMs on XLRS-Bench indicate that further efforts are needed for real-world RS applications. We have open-sourced XLRS-Bench to support further research in developing more powerful MLLMs for remote sensing.
Video-R1: Reinforcing Video Reasoning in MLLMs
Mar 27, 2025



Inspired by DeepSeek-R1's success in eliciting reasoning abilities through rule-based reinforcement learning (RL), we introduce Video-R1 as the first attempt to systematically explore the R1 paradigm for eliciting video reasoning within multimodal large language models (MLLMs). However, directly applying RL training with the GRPO algorithm to video reasoning presents two primary challenges: (i) a lack of temporal modeling for video reasoning, and (ii) the scarcity of high-quality video-reasoning data. To address these issues, we first propose the T-GRPO algorithm, which encourages models to utilize temporal information in videos for reasoning. Additionally, instead of relying solely on video data, we incorporate high-quality image-reasoning data into the training process. We have constructed two datasets: Video-R1-COT-165k for SFT cold start and Video-R1-260k for RL training, both comprising image and video data. Experimental results demonstrate that Video-R1 achieves significant improvements on video reasoning benchmarks such as VideoMMMU and VSI-Bench, as well as on general video benchmarks including MVBench and TempCompass, etc. Notably, Video-R1-7B attains a 35.8% accuracy on video spatial reasoning benchmark VSI-bench, surpassing the commercial proprietary model GPT-4o. All codes, models, data are released.
DeepPerception: Advancing R1-like Cognitive Visual Perception in MLLMs for Knowledge-Intensive Visual Grounding
Mar 17, 2025Human experts excel at fine-grained visual discrimination by leveraging domain knowledge to refine perceptual features, a capability that remains underdeveloped in current Multimodal Large Language Models (MLLMs). Despite possessing vast expert-level knowledge, MLLMs struggle to integrate reasoning into visual perception, often generating direct responses without deeper analysis. To bridge this gap, we introduce knowledge-intensive visual grounding (KVG), a novel visual grounding task that requires both fine-grained perception and domain-specific knowledge integration. To address the challenges of KVG, we propose DeepPerception, an MLLM enhanced with cognitive visual perception capabilities. Our approach consists of (1) an automated data synthesis pipeline that generates high-quality, knowledge-aligned training samples, and (2) a two-stage training framework combining supervised fine-tuning for cognitive reasoning scaffolding and reinforcement learning to optimize perception-cognition synergy. To benchmark performance, we introduce KVG-Bench a comprehensive dataset spanning 10 domains with 1.3K manually curated test cases. Experimental results demonstrate that DeepPerception significantly outperforms direct fine-tuning, achieving +8.08\% accuracy improvements on KVG-Bench and exhibiting +4.60\% superior cross-domain generalization over baseline approaches. Our findings highlight the importance of integrating cognitive processes into MLLMs for human-like visual perception and open new directions for multimodal reasoning research. The data, codes, and models are released at https://github.com/thunlp/DeepPerception.
Towards Self-Improving Systematic Cognition for Next-Generation Foundation MLLMs
Mar 16, 2025Despite their impressive capabilities, Multimodal Large Language Models (MLLMs) face challenges with fine-grained perception and complex reasoning. Prevalent pre-training approaches focus on enhancing perception by training on high-quality image captions due to the extremely high cost of collecting chain-of-thought (CoT) reasoning data for improving reasoning. While leveraging advanced MLLMs for caption generation enhances scalability, the outputs often lack comprehensiveness and accuracy. In this paper, we introduce Self-Improving Cognition (SIcog), a self-learning framework designed to construct next-generation foundation MLLMs by enhancing their systematic cognitive capabilities through multimodal pre-training with self-generated data. Specifically, we propose chain-of-description, an approach that improves an MLLM's systematic perception by enabling step-by-step visual understanding, ensuring greater comprehensiveness and accuracy. Additionally, we adopt a structured CoT reasoning technique to enable MLLMs to integrate in-depth multimodal reasoning. To construct a next-generation foundation MLLM with self-improved cognition, SIcog first equips an MLLM with systematic perception and reasoning abilities using minimal external annotations. The enhanced models then generate detailed captions and CoT reasoning data, which are further curated through self-consistency. This curated data is ultimately used to refine the MLLM during multimodal pre-training, facilitating next-generation foundation MLLM construction. Extensive experiments on both low- and high-resolution MLLMs across diverse benchmarks demonstrate that, with merely 213K self-generated pre-training samples, SIcog produces next-generation foundation MLLMs with significantly improved cognition, achieving benchmark-leading performance compared to prevalent pre-training approaches.