 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Reliability of Language Models in Instruction-Following
Dec 15, 2025Advanced LLMs have achieved near-ceiling instruction-following accuracy on benchmarks such as IFEval. However, these impressive scores do not necessarily translate to reliable services in real-world use, where users often vary their phrasing, contextual framing, and task formulations. In this paper, we study nuance-oriented reliability: whether models exhibit consistent competence across cousin prompts that convey analogous user intents but with subtle nuances. To quantify this, we introduce a new metric, reliable@k, and develop an automated pipeline that generates high-quality cousin prompts via data augmentation. Building upon this, we construct IFEval++ for systematic evaluation. Across 20 proprietary and 26 open-source LLMs, we find that current models exhibit substantial insufficiency in nuance-oriented reliability -- their performance can drop by up to 61.8% with nuanced prompt modifications. What's more, we characterize it and explore three potential improvement recipes. Our findings highlight nuance-oriented reliability as a crucial yet underexplored next step toward more dependable and trustworthy LLM behavior. Our code and benchmark are accessible: https://github.com/jianshuod/IFEval-pp.
Scaling Efficient Masked Autoencoder Learning on Large Remote Sensing Dataset
Jun 17, 2024Masked Image Modeling (MIM) has emerged as a pivotal approach for developing foundational visual models in the field of remote sensing (RS). However, current RS datasets are limited in volume and diversity, which significantly constrains the capacity of MIM methods to learn generalizable representations. In this study, we introduce \textbf{RS-4M}, a large-scale dataset designed to enable highly efficient MIM training on RS images. RS-4M comprises 4 million optical images encompassing abundant and fine-grained RS visual tasks, including object-level detection and pixel-level segmentation. Compared to natural images, RS images often contain massive redundant background pixels, which limits the training efficiency of the conventional MIM models. To address this, we propose an efficient MIM method, termed \textbf{SelectiveMAE}, which dynamically encodes and reconstructs a subset of patch tokens selected based on their semantic richness. SelectiveMAE roots in a progressive semantic token selection module, which evolves from reconstructing semantically analogical tokens to encoding complementary semantic dependencies. This approach transforms conventional MIM training into a progressive feature learning process, enabling SelectiveMAE to efficiently learn robust representations of RS images. Extensive experiments show that SelectiveMAE significantly boosts training efficiency by 2.2-2.7 times and enhances the classification, detection, and segmentation performance of the baseline MIM model.The dataset, source code, and trained models will be released.
A Survey of Time Series Anomaly Detection Methods in the AIOps Domain
Aug 01, 2023
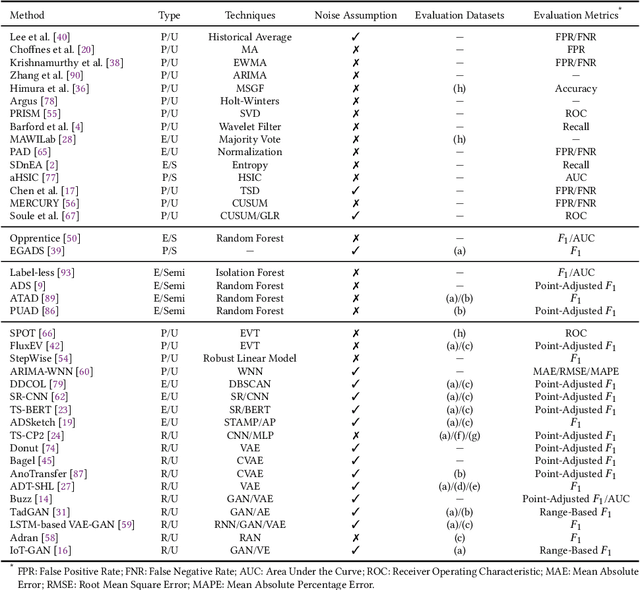

Internet-based services have seen remarkable success, generating vast amounts of monitored key performance indicators (KPIs) as univariate or multivariate time series. Monitoring and analyzing these time series are crucial for researchers, service operators, and on-call engineers to detect outliers or anomalies indicating service failures or significant events. Numerous advanced anomaly detection methods have emerged to address availability and performance issues. This review offers a comprehensive overview of time series anomaly detection in Artificial Intelligence for IT operations (AIOps), which uses AI capabilities to automate and optimize operational workflows. Additionally, it explores future directions for real-world and next-generation time-series anomaly detection based on recent advancements.
SoK: On the Semantic AI Security in Autonomous Driving
Mar 10, 2022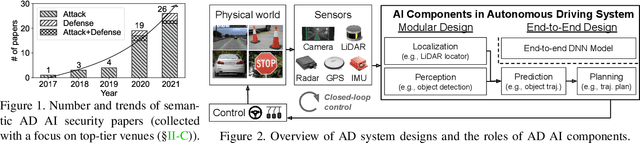
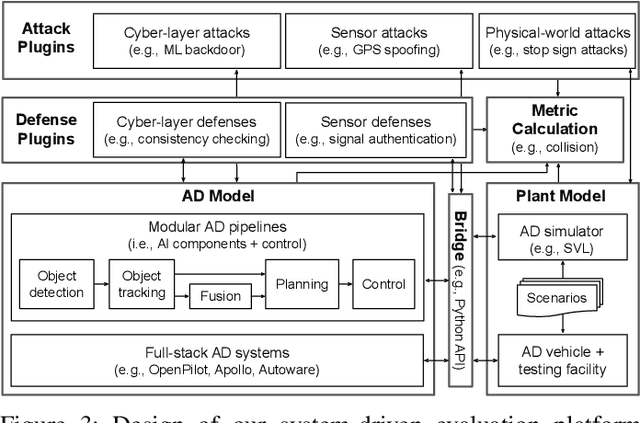


Autonomous Driving (AD) systems rely on AI components to make safety and correct driving decisions. Unfortunately, today's AI algorithms are known to be generally vulnerable to adversarial attacks. However, for such AI component-level vulnerabilities to be semantically impactful at the system level, it needs to address non-trivial semantic gaps both (1) from the system-level attack input spaces to those at AI component level, and (2) from AI component-level attack impacts to those at the system level. In this paper, we define such research space as semantic AI security as opposed to generic AI security. Over the past 5 years, increasingly more research works are performed to tackle such semantic AI security challenges in AD context, which has started to show an exponential growth trend. In this paper, we perform the first systematization of knowledge of such growing semantic AD AI security research space. In total, we collect and analyze 53 such papers, and systematically taxonomize them based on research aspects critical for the security field. We summarize 6 most substantial scientific gaps observed based on quantitative comparisons both vertically among existing AD AI security works and horizontally with security works from closely-related domains. With these, we are able to provide insights and potential future directions not only at the design level, but also at the research goal, methodology, and community levels. To address the most critical scientific methodology-level gap, we take the initiative to develop an open-source, uniform, and extensible system-driven evaluation platform, named PASS, for the semantic AD AI security research community. We also use our implemented platform prototype to showcase the capabilities and benefits of such a platform using representative semantic AD AI attacks.
Detecting Safety Problems of Multi-Sensor Fusion in Autonomous Driving
Sep 14, 2021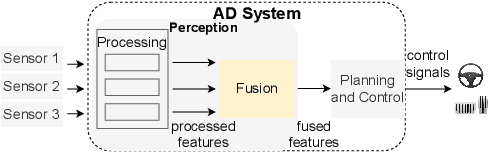

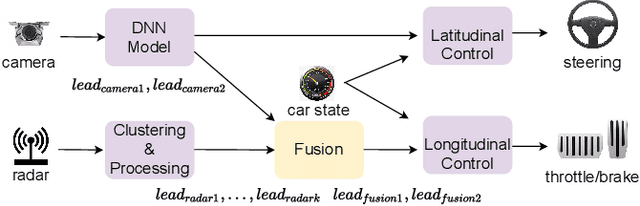

Autonomous driving (AD) systems have been thriving in recent years. In general, they receive sensor data, compute driving decisions, and output control signals to the vehicles. To smooth out the uncertainties brought by sensor inputs, AD systems usually leverage multi-sensor fusion (MSF) to fuse the sensor inputs and produce a more reliable understanding of the surroundings. However, MSF cannot completely eliminate the uncertainties since it lacks the knowledge about which sensor provides the most accurate data. As a result, critical consequences might happen unexpectedly. In this work, we observed that the popular MSF methods in an industry-grade Advanced Driver-Assistance System (ADAS) can mislead the car control and result in serious safety hazards. Misbehavior can happen regardless of the used fusion methods and the accurate data from at least one sensor. To attribute the safety hazards to a MSF method, we formally define the fusion errors and propose a way to distinguish safety violations causally induced by such errors. Further, we develop a novel evolutionary-based domain-specific search framework, FusionFuzz, for the efficient detection of fusion errors. We evaluate our framework on two widely used MSF methods. %in two driving environments. Experimental results show that FusionFuzz identifies more than 150 fusion errors. Finally, we provide several suggestions to improve the MSF methods under study.
Coverage-based Scene Fuzzing for Virtual Autonomous Driving Testing
Jun 02, 2021

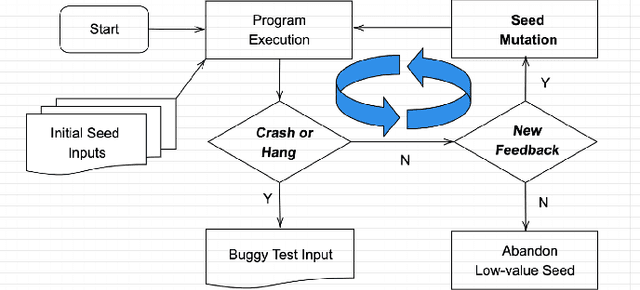
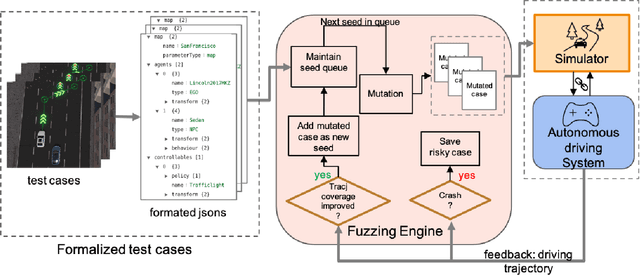
Simulation-based virtual testing has become an essential step to ensure the safety of autonomous driving systems. Testers need to handcraft the virtual driving scenes and configure various environmental settings like surrounding traffic, weather conditions, etc. Due to the huge amount of configuration possibilities, the human efforts are subject to the inefficiency in detecting flaws in industry-class autonomous driving system. This paper proposes a coverage-driven fuzzing technique to automatically generate diverse configuration parameters to form new driving scenes. Experimental results show that our fuzzing method can significantly reduce the cost in deriving new risky scenes from the initial setup designed by testers. We expect automated fuzzing will become a common practice in virtual testing for autonomous driving systems.
Potential Escalator-related Injury Identification and Prevention Based on Multi-module Integrated System for Public Health
Mar 17, 2021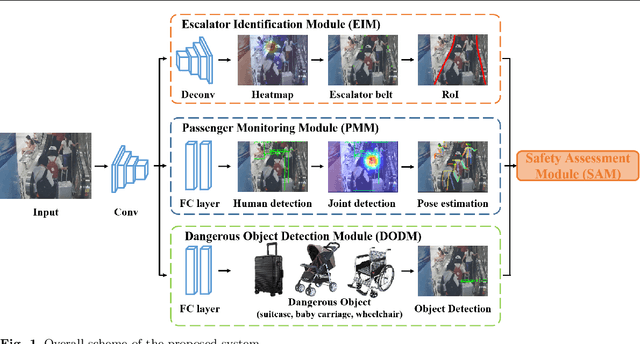


Escalator-related injuries threaten public health with the widespread use of escalators. The existing studies tend to focus on after-the-fact statistics, reflecting on the original design and use of defects to reduce the impact of escalator-related injuries, but few attention has been paid to ongoing and impending injuries. In this study, a multi-module escalator safety monitoring system based on computer vision is designed and proposed to simultaneously monitor and deal with three major injury triggers, including losing balance, not holding on to handrails and carrying large items. The escalator identification module is utilized to determine the escalator region, namely the region of interest. The passenger monitoring module is leveraged to estimate the passengers' pose to recognize unsafe behaviors on the escalator. The dangerous object detection module detects large items that may enter the escalator and raises alarms. The processing results of the above three modules are summarized in the safety assessment module as the basis for the intelligent decision of the system. The experimental results demonstrate that the proposed system has good performance and great application potential.
Towards Practical Lottery Ticket Hypothesis for Adversarial Training
Mar 06, 2020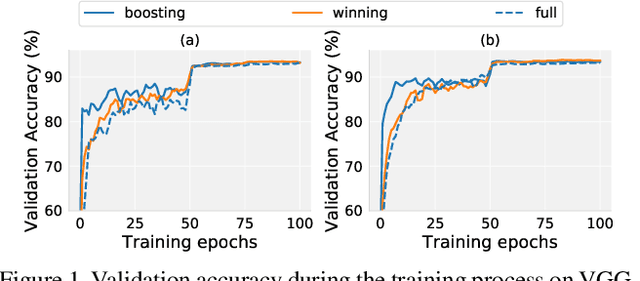

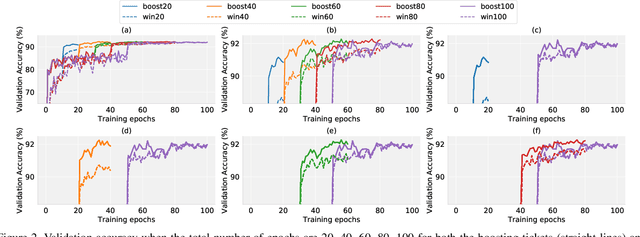

Recent research has proposed the lottery ticket hypothesis, suggesting that for a deep neural network, there exist trainable sub-networks performing equally or better than the original model with commensurate training steps. While this discovery is insightful, finding proper sub-networks requires iterative training and pruning. The high cost incurred limits the applications of the lottery ticket hypothesis. We show there exists a subset of the aforementioned sub-networks that converge significantly faster during the training process and thus can mitigate the cost issue. We conduct extensive experiments to show such sub-networks consistently exist across various model structures for a restrictive setting of hyperparameters ($e.g.$, carefully selected learning rate, pruning ratio, and model capacity). As a practical application of our findings, we demonstrate that such sub-networks can help in cutting down the total time of adversarial training, a standard approach to improve robustness, by up to 49\% on CIFAR-10 to achieve the state-of-the-art robustness.
Fooling Detection Alone is Not Enough: First Adversarial Attack against Multiple Object Tracking
May 30, 2019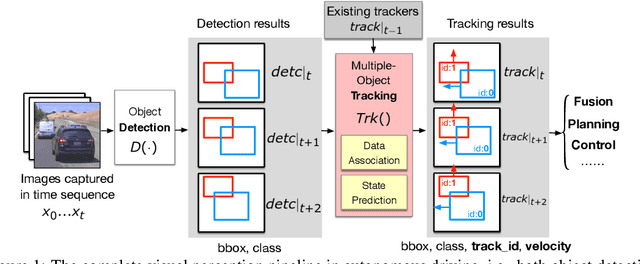
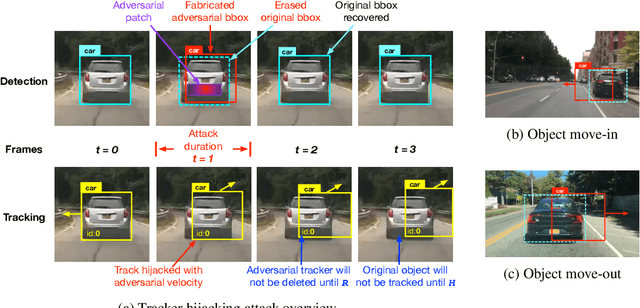
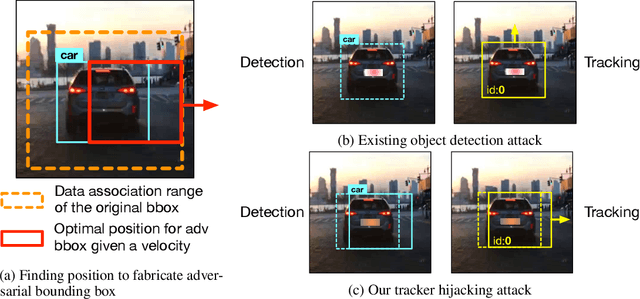
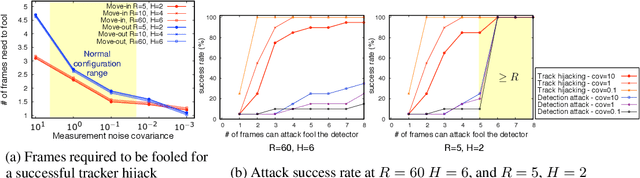
Recent work in adversarial machine learning started to focus on the visual perception in autonomous driving and studied Adversarial Examples (AEs) for object detection models. However, in such visual perception pipeline the detected objects must also be tracked, in a process called Multiple Object Tracking (MOT), to build the moving trajectories of surrounding obstacles. Since MOT is designed to be robust against errors in object detection, it poses a general challenge to existing attack techniques that blindly target objection detection: we find that a success rate of over 98% is needed for them to actually affect the tracking results, a requirement that no existing attack technique can satisfy. In this paper, we are the first to study adversarial machine learning attacks against the complete visual perception pipeline in autonomous driving, and discover a novel attack technique, tracker hijacking, that can effectively fool MOT using AEs on object detection. Using our technique, successful AEs on as few as one single frame can move an existing object in to or out of the headway of an autonomous vehicle to cause potential safety hazards. We perform evaluation using the Berkeley Deep Drive dataset and find that on average when 3 frames are attacked, our attack can have a nearly 100% success rate while attacks that blindly target object detection only have up to 25%.
Enhancing Cross-task Transferability of Adversarial Examples with Dispersion Reduction
May 08, 2019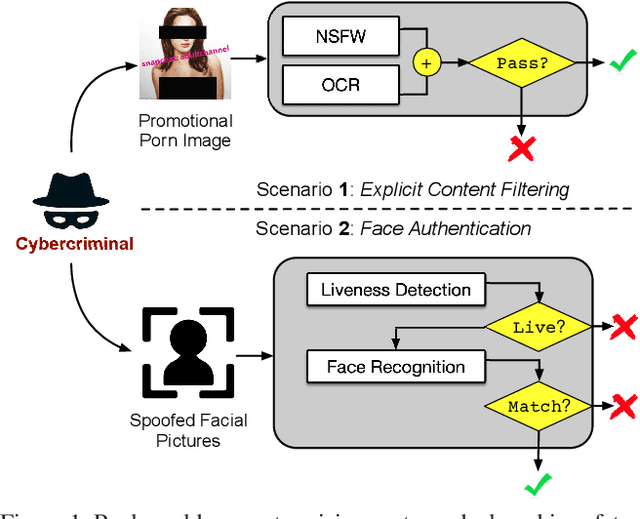
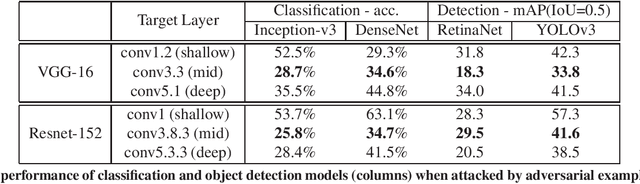

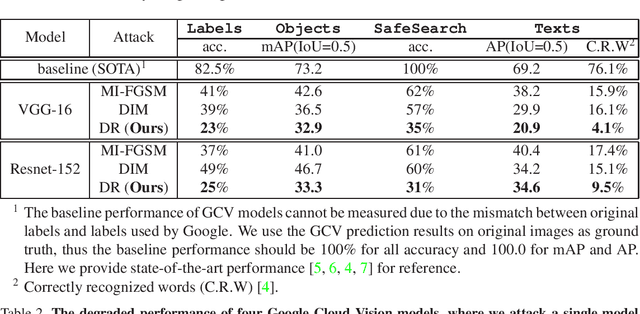
Neural networks are known to be vulnerable to carefully crafted adversarial examples, and these malicious samples often transfer, i.e., they maintain their effectiveness even against other models. With great efforts delved into the transferability of adversarial examples, surprisingly, less attention has been paid to its impact on real-world deep learning deployment. In this paper, we investigate the transferability of adversarial examples across a wide range of real-world computer vision tasks, including image classification, explicit content detection, optical character recognition (OCR), and object detection. It represents the cybercriminal's situation where an ensemble of different detection mechanisms need to be evaded all at once. We propose practical attack that overcomes existing attacks' limitation of requiring task-specific loss functions by targeting on the `dispersion' of internal feature map. We report evaluation on four different computer vision tasks provided by Google Cloud Vision APIs to show how our approach outperforms existing attacks by degrading performance of multiple CV tasks by a large margin with only modest perturbations.