 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Reconstruction of LiDAR Point Clouds under Jamming Attacks via Full-Waveform Representation and Simultaneous Laser Sensing
Apr 01, 2026LiDAR sensors are critical for autonomous driving perception, yet remain vulnerable to spoofing attacks. Jamming attacks inject high-frequency laser pulses that completely blind LiDAR sensors by overwhelming authentic returns with malicious signals. We discover that while point clouds become randomized, the underlying full-waveform data retains distinguishable signatures between attack and legitimate signals. In this work, we propose PULSAR-Net, capable of reconstructing authentic point clouds under jamming attacks by leveraging previously underutilized intermediate full-waveform representations and simultaneous laser sensing in modern LiDAR systems. PULSAR-Net adopts a novel U-Net architecture with axial spatial attention mechanisms specifically designed to identify attack-induced signals from authentic object returns in the full-waveform representation. To address the lack of full-waveform representations in existing LiDAR datasets under jamming attacks, we introduce a physics-aware dataset generation pipeline that synthesizes realistic full-waveform representations under jamming attacks. Despite being trained exclusively on synthetic data, PULSAR-Net achieves reconstruction rates of 92% and 73% for vehicles obscured by jamming attacks in real-world static and driving scenarios, respectively.
Trapped by Their Own Light: Deployable and Stealth Retroreflective Patch Attacks on Traffic Sign Recognition Systems
Nov 13, 2025Traffic sign recognition plays a critical role in ensuring safe and efficient transportation of autonomous vehicles but remain vulnerable to adversarial attacks using stickers or laser projections. While existing attack vectors demonstrate security concerns, they suffer from visual detectability or implementation constraints, suggesting unexplored vulnerability surfaces in TSR systems. We introduce the Adversarial Retroreflective Patch (ARP), a novel attack vector that combines the high deployability of patch attacks with the stealthiness of laser projections by utilizing retroreflective materials activated only under victim headlight illumination. We develop a retroreflection simulation method and employ black-box optimization to maximize attack effectiveness. ARP achieves $\geq$93.4\% success rate in dynamic scenarios at 35 meters and $\geq$60\% success rate against commercial TSR systems in real-world conditions. Our user study demonstrates that ARP attacks maintain near-identical stealthiness to benign signs while achieving $\geq$1.9\% higher stealthiness scores than previous patch attacks. We propose the DPR Shield defense, employing strategically placed polarized filters, which achieves $\geq$75\% defense success rates for stop signs and speed limit signs against micro-prism patches.
Interior-Point Vanishing Problem in Semidefinite Relaxations for Neural Network Verification
Jun 12, 2025Semidefinite programming (SDP) relaxation has emerged as a promising approach for neural network verification, offering tighter bounds than other convex relaxation methods for deep neural networks (DNNs) with ReLU activations. However, we identify a critical limitation in the SDP relaxation when applied to deep networks: interior-point vanishing, which leads to the loss of strict feasibility -- a crucial condition for the numerical stability and optimality of SDP. Through rigorous theoretical and empirical analysis, we demonstrate that as the depth of DNNs increases, the strict feasibility is likely to be lost, creating a fundamental barrier to scaling SDP-based verification. To address the interior-point vanishing, we design and investigate five solutions to enhance the feasibility conditions of the verification problem. Our methods can successfully solve 88% of the problems that could not be solved by existing methods, accounting for 41% of the total. Our analysis also reveals that the valid constraints for the lower and upper bounds for each ReLU unit are traditionally inherited from prior work without solid reasons, but are actually not only unbeneficial but also even harmful to the problem's feasibility. This work provides valuable insights into the fundamental challenges of SDP-based DNN verification and offers practical solutions to improve its applicability to deeper neural networks, contributing to the development of more reliable and secure systems with DNNs.
SLAMSpoof: Practical LiDAR Spoofing Attacks on Localization Systems Guided by Scan Matching Vulnerability Analysis
Feb 19, 2025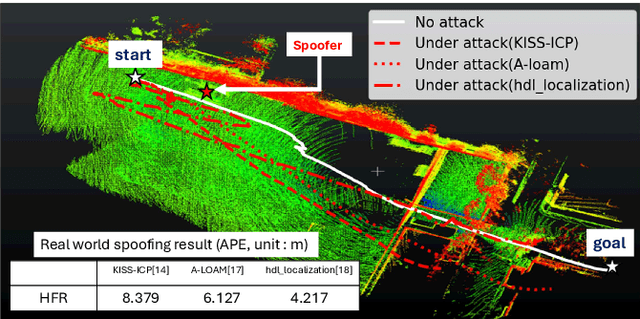

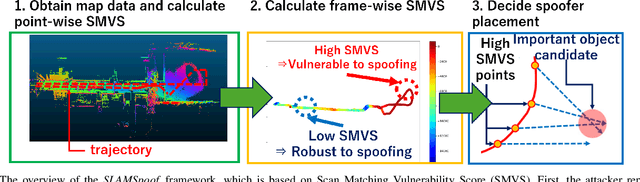
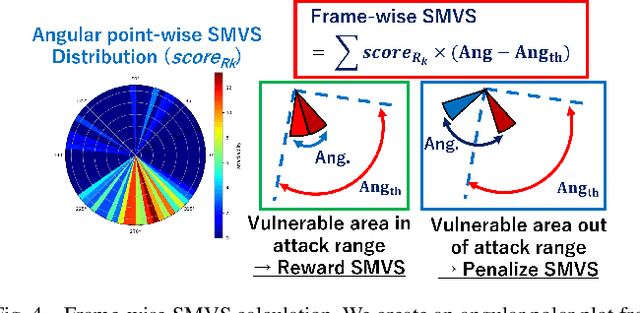
Accurate localization is essential for enabling modern full self-driving services. These services heavily rely on map-based traffic information to reduce uncertainties in recognizing lane shapes, traffic light locations, and traffic signs. Achieving this level of reliance on map information requires centimeter-level localization accuracy, which is currently only achievable with LiDAR sensors. However, LiDAR is known to be vulnerable to spoofing attacks that emit malicious lasers against LiDAR to overwrite its measurements. Once localization is compromised, the attack could lead the victim off roads or make them ignore traffic lights. Motivated by these serious safety implications, we design SLAMSpoof, the first practical LiDAR spoofing attack on localization systems for self-driving to assess the actual attack significance on autonomous vehicles. SLAMSpoof can effectively find the effective attack location based on our scan matching vulnerability score (SMVS), a point-wise metric representing the potential vulnerability to spoofing attacks. To evaluate the effectiveness of the attack, we conduct real-world experiments on ground vehicles and confirm its high capability in real-world scenarios, inducing position errors of $\geq$4.2 meters (more than typical lane width) for all 3 popular LiDAR-based localization algorithms. We finally discuss the potential countermeasures of this attack. Code is available at https://github.com/Keio-CSG/slamspoof
Revisiting Physical-World Adversarial Attack on Traffic Sign Recognition: A Commercial Systems Perspective
Sep 15, 2024Traffic Sign Recognition (TSR) is crucial for safe and correct driving automation. Recent works revealed a general vulnerability of TSR models to physical-world adversarial attacks, which can be low-cost, highly deployable, and capable of causing severe attack effects such as hiding a critical traffic sign or spoofing a fake one. However, so far existing works generally only considered evaluating the attack effects on academic TSR models, leaving the impacts of such attacks on real-world commercial TSR systems largely unclear. In this paper, we conduct the first large-scale measurement of physical-world adversarial attacks against commercial TSR systems. Our testing results reveal that it is possible for existing attack works from academia to have highly reliable (100\%) attack success against certain commercial TSR system functionality, but such attack capabilities are not generalizable, leading to much lower-than-expected attack success rates overall. We find that one potential major factor is a spatial memorization design that commonly exists in today's commercial TSR systems. We design new attack success metrics that can mathematically model the impacts of such design on the TSR system-level attack success, and use them to revisit existing attacks. Through these efforts, we uncover 7 novel observations, some of which directly challenge the observations or claims in prior works due to the introduction of the new metrics.
Exploring Backdoor Attacks against Large Language Model-based Decision Making
May 27, 2024



Large Language Models (LLMs) have shown significant promise in decision-making tasks when fine-tuned on specific applications, leveraging their inherent common sense and reasoning abilities learned from vast amounts of data. However, these systems are exposed to substantial safety and security risks during the fine-tuning phase. In this work, we propose the first comprehensive framework for Backdoor Attacks against LLM-enabled Decision-making systems (BALD), systematically exploring how such attacks can be introduced during the fine-tuning phase across various channels. Specifically, we propose three attack mechanisms and corresponding backdoor optimization methods to attack different components in the LLM-based decision-making pipeline: word injection, scenario manipulation, and knowledge injection. Word injection embeds trigger words directly into the query prompt. Scenario manipulation occurs in the physical environment, where a high-level backdoor semantic scenario triggers the attack. Knowledge injection conducts backdoor attacks on retrieval augmented generation (RAG)-based LLM systems, strategically injecting word triggers into poisoned knowledge while ensuring the information remains factually accurate for stealthiness. We conduct extensive experiments with three popular LLMs (GPT-3.5, LLaMA2, PaLM2), using two datasets (HighwayEnv, nuScenes), and demonstrate the effectiveness and stealthiness of our backdoor triggers and mechanisms. Finally, we critically assess the strengths and weaknesses of our proposed approaches, highlight the inherent vulnerabilities of LLMs in decision-making tasks, and evaluate potential defenses to safeguard LLM-based decision making systems.
Invisible Reflections: Leveraging Infrared Laser Reflections to Target Traffic Sign Perception
Jan 07, 2024



All vehicles must follow the rules that govern traffic behavior, regardless of whether the vehicles are human-driven or Connected Autonomous Vehicles (CAVs). Road signs indicate locally active rules, such as speed limits and requirements to yield or stop. Recent research has demonstrated attacks, such as adding stickers or projected colored patches to signs, that cause CAV misinterpretation, resulting in potential safety issues. Humans can see and potentially defend against these attacks. But humans can not detect what they can not observe. We have developed an effective physical-world attack that leverages the sensitivity of filterless image sensors and the properties of Infrared Laser Reflections (ILRs), which are invisible to humans. The attack is designed to affect CAV cameras and perception, undermining traffic sign recognition by inducing misclassification. In this work, we formulate the threat model and requirements for an ILR-based traffic sign perception attack to succeed. We evaluate the effectiveness of the ILR attack with real-world experiments against two major traffic sign recognition architectures on four IR-sensitive cameras. Our black-box optimization methodology allows the attack to achieve up to a 100% attack success rate in indoor, static scenarios and a >80.5% attack success rate in our outdoor, moving vehicle scenarios. We find the latest state-of-the-art certifiable defense is ineffective against ILR attacks as it mis-certifies >33.5% of cases. To address this, we propose a detection strategy based on the physical properties of IR laser reflections which can detect 96% of ILR attacks.
Intriguing Properties of Diffusion Models: A Large-Scale Dataset for Evaluating Natural Attack Capability in Text-to-Image Generative Models
Aug 30, 2023



Denoising probabilistic diffusion models have shown breakthrough performance that can generate more photo-realistic images or human-level illustrations than the prior models such as GANs. This high image-generation capability has stimulated the creation of many downstream applications in various areas. However, we find that this technology is indeed a double-edged sword: We identify a new type of attack, called the Natural Denoising Diffusion (NDD) attack based on the finding that state-of-the-art deep neural network (DNN) models still hold their prediction even if we intentionally remove their robust features, which are essential to the human visual system (HVS), by text prompts. The NDD attack can generate low-cost, model-agnostic, and transferrable adversarial attacks by exploiting the natural attack capability in diffusion models. Motivated by the finding, we construct a large-scale dataset, Natural Denoising Diffusion Attack (NDDA) dataset, to systematically evaluate the risk of the natural attack capability of diffusion models with state-of-the-art text-to-image diffusion models. We evaluate the natural attack capability by answering 6 research questions. Through a user study to confirm the validity of the NDD attack, we find that the NDD attack can achieve an 88% detection rate while being stealthy to 93% of human subjects. We also find that the non-robust features embedded by diffusion models contribute to the natural attack capability. To confirm the model-agnostic and transferrable attack capability, we perform the NDD attack against an AD vehicle and find that 73% of the physically printed attacks can be detected as a stop sign. We hope that our study and dataset can help our community to be aware of the risk of diffusion models and facilitate further research toward robust DNN models.
Does Physical Adversarial Example Really Matter to Autonomous Driving? Towards System-Level Effect of Adversarial Object Evasion Attack
Aug 23, 2023



In autonomous driving (AD), accurate perception is indispensable to achieving safe and secure driving. Due to its safety-criticality, the security of AD perception has been widely studied. Among different attacks on AD perception, the physical adversarial object evasion attacks are especially severe. However, we find that all existing literature only evaluates their attack effect at the targeted AI component level but not at the system level, i.e., with the entire system semantics and context such as the full AD pipeline. Thereby, this raises a critical research question: can these existing researches effectively achieve system-level attack effects (e.g., traffic rule violations) in the real-world AD context? In this work, we conduct the first measurement study on whether and how effectively the existing designs can lead to system-level effects, especially for the STOP sign-evasion attacks due to their popularity and severity. Our evaluation results show that all the representative prior works cannot achieve any system-level effects. We observe two design limitations in the prior works: 1) physical model-inconsistent object size distribution in pixel sampling and 2) lack of vehicle plant model and AD system model consideration. Then, we propose SysAdv, a novel system-driven attack design in the AD context and our evaluation results show that the system-level effects can be significantly improved, i.e., the violation rate increases by around 70%.
Revisiting LiDAR Spoofing Attack Capabilities against Object Detection: Improvements, Measurement, and New Attack
Mar 19, 2023



LiDAR (Light Detection And Ranging) is an indispensable sensor for precise long- and wide-range 3D sensing, which directly benefited the recent rapid deployment of autonomous driving (AD). Meanwhile, such a safety-critical application strongly motivates its security research. A recent line of research demonstrates that one can manipulate the LiDAR point cloud and fool object detection by firing malicious lasers against LiDAR. However, these efforts face 3 critical research gaps: (1) evaluating only on a specific LiDAR (VLP-16); (2) assuming unvalidated attack capabilities; and (3) evaluating with models trained on limited datasets. To fill these critical research gaps, we conduct the first large-scale measurement study on LiDAR spoofing attack capabilities on object detectors with 9 popular LiDARs in total and 3 major types of object detectors. To perform this measurement, we significantly improved the LiDAR spoofing capability with more careful optics and functional electronics, which allows us to be the first to clearly demonstrate and quantify key attack capabilities assumed in prior works. However, we further find that such key assumptions actually can no longer hold for all the other (8 out of 9) LiDARs that are more recent than VLP-16 due to various recent LiDAR features. To this end, we further identify a new type of LiDAR spoofing attack that can improve on this and be applicable to a much more general and recent set of LiDARs. We find that its attack capability is enough to (1) cause end-to-end safety hazards in simulated AD scenarios, and (2) remove real vehicles in the physical world. We also discuss the defense side.