 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Automated Design of Quantum Circuits for Imaginary Time Evolution Methods Using Deep Reinforcement Learning
Apr 09, 2026Efficient ground state search is fundamental to advancing combinatorial optimization problems and quantum chemistry. While the Variational Imaginary Time Evolution (VITE) method offers a useful alternative to Variational Quantum Eigensolver (VQE), and Quantum Approximate Optimization Algorithm (QAOA), its implementation on Noisy Intermediate-Scale Quantum (NISQ) devices is severely limited by the gate counts and depth of manually designed ansatz. Here, we present an automated framework for VITE circuit design using Double Deep-Q Networks (DDQN). Our approach treats circuit construction as a multi-objective optimization problem, simultaneously minimizing energy expectation values and optimizing circuit complexity. By introducing adoptive thresholds, we demonstrate significant hardware overhead reductions. In Max-Cut problems, our agent autonomously discovered circuits with approximately 37\% fewer gates and 43\% less depth than standard hardware-efficient ansatz on average. For molecular hydrogen ($H_2$), the DDQN also achieved the Full-CI limit, with maintaining a significantly shallower circuit. These results suggest that deep reinforcement learning can be helpful to find non-intuitive, optimal circuit structures, providing a pathway toward efficient, hardware-aware quantum algorithm design.
VisionClaw: Always-On AI Agents through Smart Glasses
Apr 03, 2026We present VisionClaw, an always-on wearable AI agent that integrates live egocentric perception with agentic task execution. Running on Meta Ray-Ban smart glasses, VisionClaw continuously perceives real-world context and enables in-situ, speech-driven action initiation and delegation via OpenClaw AI agents. Therefore, users can directly execute tasks through the smart glasses, such as adding real-world objects to an Amazon cart, generating notes from physical documents, receiving meeting briefings on the go, creating events from posters, or controlling IoT devices. We evaluate VisionClaw through a controlled laboratory study (N=12) and a longitudinal deployment study (N=5). Results show that integrating perception and execution enables faster task completion and reduces interaction overhead compared to non-always-on and non-agent baselines. Beyond performance gains, deployment findings reveal a shift in interaction: tasks are initiated opportunistically during ongoing activities, and execution is increasingly delegated rather than manually controlled. These results suggest a new paradigm for wearable AI agents, where perception and action are continuously coupled to support situated, hands-free interaction.
HumanoidTurk: Expanding VR Haptics with Humanoids for Driving Simulations
Jan 26, 2026We explore how humanoid robots can be repurposed as haptic media, extending beyond their conventional role as social, assistive, collaborative agents. To illustrate this approach, we implemented HumanoidTurk, taking a first step toward a humanoid-based haptic system that translates in-game g-force signals into synchronized motion feedback in VR driving. A pilot study involving six participants compared two synthesis methods, leading us to adopt a filter-based approach for smoother and more realistic feedback. A subsequent study with sixteen participants evaluated four conditions: no-feedback, controller, humanoid+controller, and human+controller. Results showed that humanoid feedback enhanced immersion, realism, and enjoyment, while introducing moderate costs in terms of comfort and simulation sickness. Interviews further highlighted the robot's consistency and predictability in contrast to the adaptability of human feedback. From these findings, we identify fidelity, adaptability, and versatility as emerging themes, positioning humanoids as a distinct haptic modality for immersive VR.
MapStory: LLM-Powered Text-Driven Map Animation Prototyping with Human-in-the-Loop Editing
May 28, 2025We introduce MapStory, an LLM-powered animation authoring tool that generates editable map animation sequences directly from natural language text. Given a user-written script, MapStory leverages an agentic architecture to automatically produce a scene breakdown, which decomposes the script into key animation building blocks such as camera movements, visual highlights, and animated elements. Our system includes a researcher component that accurately queries geospatial information by leveraging an LLM with web search, enabling the automatic extraction of relevant regions, paths, and coordinates while allowing users to edit and query for changes or additional information to refine the results. Additionally, users can fine-tune parameters of these blocks through an interactive timeline editor. We detail the system's design and architecture, informed by formative interviews with professional animators and an analysis of 200 existing map animation videos. Our evaluation, which includes expert interviews (N=5) and a usability study (N=12), demonstrates that MapStory enables users to create map animations with ease, facilitates faster iteration, encourages creative exploration, and lowers barriers to creating map-centric stories.
SLAMSpoof: Practical LiDAR Spoofing Attacks on Localization Systems Guided by Scan Matching Vulnerability Analysis
Feb 19, 2025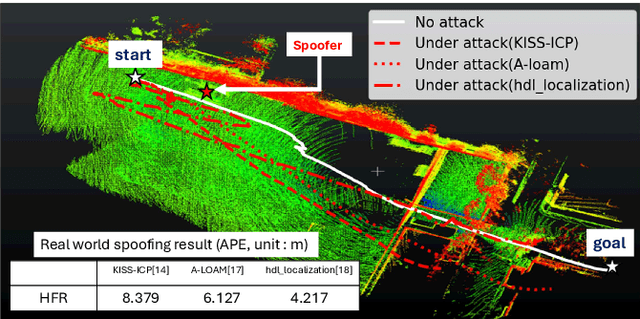

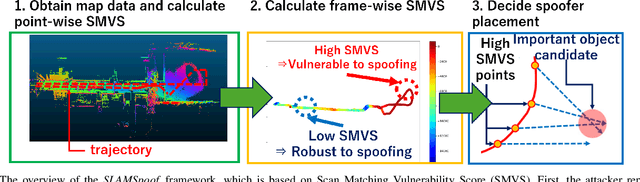
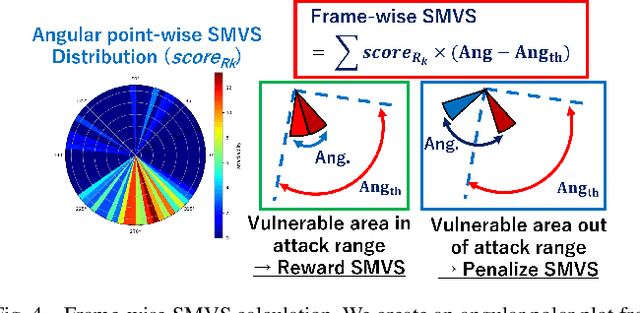
Accurate localization is essential for enabling modern full self-driving services. These services heavily rely on map-based traffic information to reduce uncertainties in recognizing lane shapes, traffic light locations, and traffic signs. Achieving this level of reliance on map information requires centimeter-level localization accuracy, which is currently only achievable with LiDAR sensors. However, LiDAR is known to be vulnerable to spoofing attacks that emit malicious lasers against LiDAR to overwrite its measurements. Once localization is compromised, the attack could lead the victim off roads or make them ignore traffic lights. Motivated by these serious safety implications, we design SLAMSpoof, the first practical LiDAR spoofing attack on localization systems for self-driving to assess the actual attack significance on autonomous vehicles. SLAMSpoof can effectively find the effective attack location based on our scan matching vulnerability score (SMVS), a point-wise metric representing the potential vulnerability to spoofing attacks. To evaluate the effectiveness of the attack, we conduct real-world experiments on ground vehicles and confirm its high capability in real-world scenarios, inducing position errors of $\geq$4.2 meters (more than typical lane width) for all 3 popular LiDAR-based localization algorithms. We finally discuss the potential countermeasures of this attack. Code is available at https://github.com/Keio-CSG/slamspoof
Everyday AR through AI-in-the-Loop
Dec 17, 2024
This workshop brings together experts and practitioners from augmented reality (AR) and artificial intelligence (AI) to shape the future of AI-in-the-loop everyday AR experiences. With recent advancements in both AR hardware and AI capabilities, we envision that everyday AR -- always-available and seamlessly integrated into users' daily environments -- is becoming increasingly feasible. This workshop will explore how AI can drive such everyday AR experiences. We discuss a range of topics, including adaptive and context-aware AR, generative AR content creation, always-on AI assistants, AI-driven accessible design, and real-world-oriented AI agents. Our goal is to identify the opportunities and challenges in AI-enabled AR, focusing on creating novel AR experiences that seamlessly blend the digital and physical worlds. Through the workshop, we aim to foster collaboration, inspire future research, and build a community to advance the research field of AI-enhanced AR.
SHAPE-IT: Exploring Text-to-Shape-Display for Generative Shape-Changing Behaviors with LLMs
Sep 10, 2024



This paper introduces text-to-shape-display, a novel approach to generating dynamic shape changes in pin-based shape displays through natural language commands. By leveraging large language models (LLMs) and AI-chaining, our approach allows users to author shape-changing behaviors on demand through text prompts without programming. We describe the foundational aspects necessary for such a system, including the identification of key generative elements (primitive, animation, and interaction) and design requirements to enhance user interaction, based on formative exploration and iterative design processes. Based on these insights, we develop SHAPE-IT, an LLM-based authoring tool for a 24 x 24 shape display, which translates the user's textual command into executable code and allows for quick exploration through a web-based control interface. We evaluate the effectiveness of SHAPE-IT in two ways: 1) performance evaluation and 2) user evaluation (N= 10). The study conclusions highlight the ability to facilitate rapid ideation of a wide range of shape-changing behaviors with AI. However, the findings also expose accuracy-related challenges and limitations, prompting further exploration into refining the framework for leveraging AI to better suit the unique requirements of shape-changing systems.
RealitySummary: On-Demand Mixed Reality Document Enhancement using Large Language Models
May 28, 2024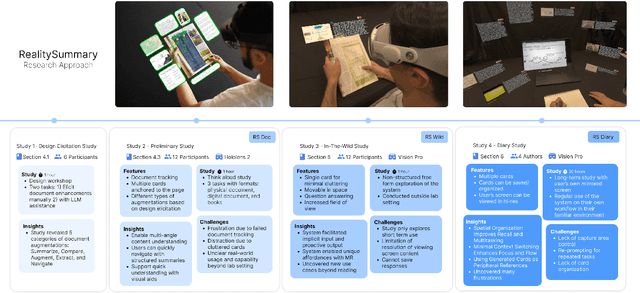
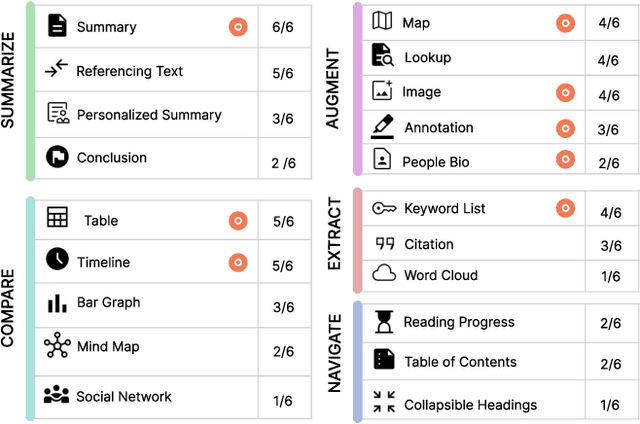
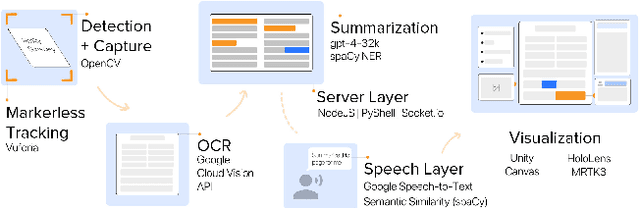

We introduce RealitySummary, a mixed reality reading assistant that can enhance any printed or digital document using on-demand text extraction, summarization, and augmentation. While augmented reading tools promise to enhance physical reading experiences with overlaid digital content, prior systems have typically required pre-processed documents, which limits their generalizability and real-world use cases. In this paper, we explore on-demand document augmentation by leveraging large language models. To understand generalizable techniques for diverse documents, we first conducted an exploratory design study which identified five categories of document enhancements (summarization, augmentation, navigation, comparison, and extraction). Based on this, we developed a proof-of-concept system that can automatically extract and summarize text using Google Cloud OCR and GPT-4, then embed information around documents using a Microsoft Hololens 2 and Apple Vision Pro. We demonstrate real-time examples of six specific document augmentations: 1) summaries, 2) comparison tables, 3) timelines, 4) keyword lists, 5) summary highlighting, and 6) information cards. Results from a usability study (N=12) and in-the-wild study (N=11) highlight the potential benefits of on-demand MR document enhancement and opportunities for future research.
Augmented Conversation with Embedded Speech-Driven On-the-Fly Referencing in AR
May 28, 2024
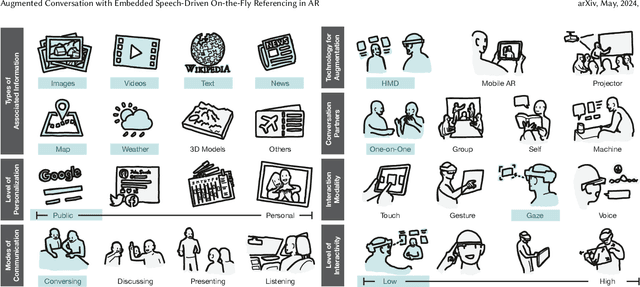
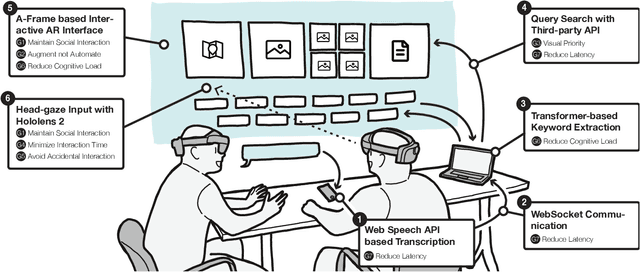
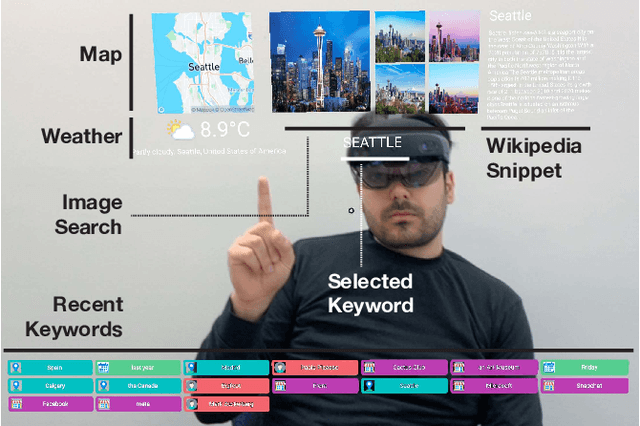
This paper introduces the concept of augmented conversation, which aims to support co-located in-person conversations via embedded speech-driven on-the-fly referencing in augmented reality (AR). Today computing technologies like smartphones allow quick access to a variety of references during the conversation. However, these tools often create distractions, reducing eye contact and forcing users to focus their attention on phone screens and manually enter keywords to access relevant information. In contrast, AR-based on-the-fly referencing provides relevant visual references in real-time, based on keywords extracted automatically from the spoken conversation. By embedding these visual references in AR around the conversation partner, augmented conversation reduces distraction and friction, allowing users to maintain eye contact and supporting more natural social interactions. To demonstrate this concept, we developed \system, a Hololens-based interface that leverages real-time speech recognition, natural language processing and gaze-based interactions for on-the-fly embedded visual referencing. In this paper, we explore the design space of visual referencing for conversations, and describe our our implementation -- building on seven design guidelines identified through a user-centered design process. An initial user study confirms that our system decreases distraction and friction in conversations compared to smartphone searches, while providing highly useful and relevant information.
Augmented Physics: A Machine Learning-Powered Tool for Creating Interactive Physics Simulations from Static Diagrams
May 28, 2024
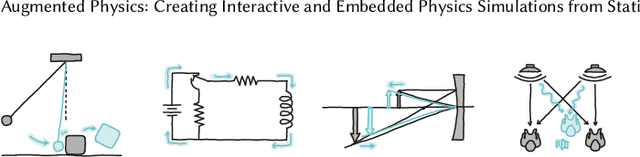


We introduce Augmented Physics, a machine learning-powered tool designed for creating interactive physics simulations from static textbook diagrams. Leveraging computer vision techniques, such as Segment Anything and OpenCV, our web-based system enables users to semi-automatically extract diagrams from physics textbooks and then generate interactive simulations based on the extracted content. These interactive diagrams are seamlessly integrated into scanned textbook pages, facilitating interactive and personalized learning experiences across various physics concepts, including gravity, optics, circuits, and kinematics. Drawing on an elicitation study with seven physics instructors, we explore four key augmentation techniques: 1) augmented experiments, 2) animated diagrams, 3) bi-directional manipulatives, and 4) parameter visualization. We evaluate our system through technical evaluation, a usability study (N=12), and expert interviews (N=12). The study findings suggest that our system can facilitate more engaging and personalized learning experiences in physics education.