 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Chain Backdoor: Do You Trust Diffusion Models as Generative Data Supplier?
Dec 12, 2025The increasing use of generative models such as diffusion models for synthetic data augmentation has greatly reduced the cost of data collection and labeling in downstream perception tasks. However, this new data source paradigm may introduce important security concerns. This work investigates backdoor propagation in such emerging generative data supply chains, namely Data-Chain Backdoor (DCB). Specifically, we find that open-source diffusion models can become hidden carriers of backdoors. Their strong distribution-fitting ability causes them to memorize and reproduce backdoor triggers during generation, which are subsequently inherited by downstream models, resulting in severe security risks. This threat is particularly concerning under clean-label attack scenarios, as it remains effective while having negligible impact on the utility of the synthetic data. Furthermore, we discover an Early-Stage Trigger Manifestation (ESTM) phenomenon: backdoor trigger patterns tend to surface more explicitly in the early, high-noise stages of the diffusion model's reverse generation process before being subtly integrated into the final samples. Overall, this work reveals a previously underexplored threat in generative data pipelines and provides initial insights toward mitigating backdoor risks in synthetic data generation.
T2I-Based Physical-World Appearance Attack against Traffic Sign Recognition Systems in Autonomous Driving
Nov 17, 2025Traffic Sign Recognition (TSR) systems play a critical role in Autonomous Driving (AD) systems, enabling real-time detection of road signs, such as STOP and speed limit signs. While these systems are increasingly integrated into commercial vehicles, recent research has exposed their vulnerability to physical-world adversarial appearance attacks. In such attacks, carefully crafted visual patterns are misinterpreted by TSR models as legitimate traffic signs, while remaining inconspicuous or benign to human observers. However, existing adversarial appearance attacks suffer from notable limitations. Pixel-level perturbation-based methods often lack stealthiness and tend to overfit to specific surrogate models, resulting in poor transferability to real-world TSR systems. On the other hand, text-to-image (T2I) diffusion model-based approaches demonstrate limited effectiveness and poor generalization to out-of-distribution sign types. In this paper, we present DiffSign, a novel T2I-based appearance attack framework designed to generate physically robust, highly effective, transferable, practical, and stealthy appearance attacks against TSR systems. To overcome the limitations of prior approaches, we propose a carefully designed attack pipeline that integrates CLIP-based loss and masked prompts to improve attack focus and controllability. We also propose two novel style customization methods to guide visual appearance and improve out-of-domain traffic sign attack generalization and attack stealthiness. We conduct extensive evaluations of DiffSign under varied real-world conditions, including different distances, angles, light conditions, and sign categories. Our method achieves an average physical-world attack success rate of 83.3%, leveraging DiffSign's high effectiveness in attack transferability.
Trapped by Their Own Light: Deployable and Stealth Retroreflective Patch Attacks on Traffic Sign Recognition Systems
Nov 13, 2025Traffic sign recognition plays a critical role in ensuring safe and efficient transportation of autonomous vehicles but remain vulnerable to adversarial attacks using stickers or laser projections. While existing attack vectors demonstrate security concerns, they suffer from visual detectability or implementation constraints, suggesting unexplored vulnerability surfaces in TSR systems. We introduce the Adversarial Retroreflective Patch (ARP), a novel attack vector that combines the high deployability of patch attacks with the stealthiness of laser projections by utilizing retroreflective materials activated only under victim headlight illumination. We develop a retroreflection simulation method and employ black-box optimization to maximize attack effectiveness. ARP achieves $\geq$93.4\% success rate in dynamic scenarios at 35 meters and $\geq$60\% success rate against commercial TSR systems in real-world conditions. Our user study demonstrates that ARP attacks maintain near-identical stealthiness to benign signs while achieving $\geq$1.9\% higher stealthiness scores than previous patch attacks. We propose the DPR Shield defense, employing strategically placed polarized filters, which achieves $\geq$75\% defense success rates for stop signs and speed limit signs against micro-prism patches.
SLAMSpoof: Practical LiDAR Spoofing Attacks on Localization Systems Guided by Scan Matching Vulnerability Analysis
Feb 19, 2025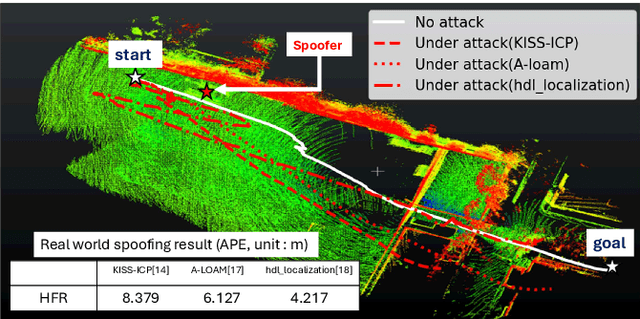

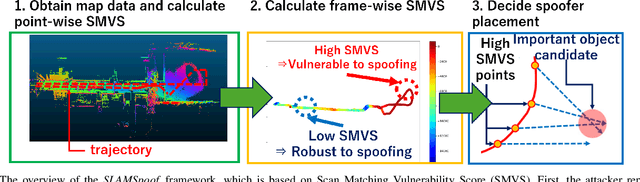
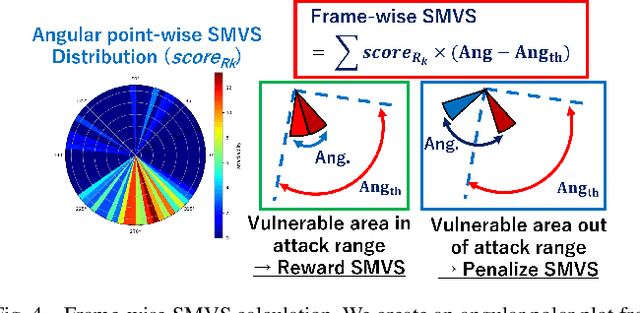
Accurate localization is essential for enabling modern full self-driving services. These services heavily rely on map-based traffic information to reduce uncertainties in recognizing lane shapes, traffic light locations, and traffic signs. Achieving this level of reliance on map information requires centimeter-level localization accuracy, which is currently only achievable with LiDAR sensors. However, LiDAR is known to be vulnerable to spoofing attacks that emit malicious lasers against LiDAR to overwrite its measurements. Once localization is compromised, the attack could lead the victim off roads or make them ignore traffic lights. Motivated by these serious safety implications, we design SLAMSpoof, the first practical LiDAR spoofing attack on localization systems for self-driving to assess the actual attack significance on autonomous vehicles. SLAMSpoof can effectively find the effective attack location based on our scan matching vulnerability score (SMVS), a point-wise metric representing the potential vulnerability to spoofing attacks. To evaluate the effectiveness of the attack, we conduct real-world experiments on ground vehicles and confirm its high capability in real-world scenarios, inducing position errors of $\geq$4.2 meters (more than typical lane width) for all 3 popular LiDAR-based localization algorithms. We finally discuss the potential countermeasures of this attack. Code is available at https://github.com/Keio-CSG/slamspoof
A Comprehensive Study of Bug-Fix Patterns in Autonomous Driving Systems
Feb 04, 2025



As autonomous driving systems (ADSes) become increasingly complex and integral to daily life, the importance of understanding the nature and mitigation of software bugs in these systems has grown correspondingly. Addressing the challenges of software maintenance in autonomous driving systems (e.g., handling real-time system decisions and ensuring safety-critical reliability) is crucial due to the unique combination of real-time decision-making requirements and the high stakes of operational failures in ADSes. The potential of automated tools in this domain is promising, yet there remains a gap in our comprehension of the challenges faced and the strategies employed during manual debugging and repair of such systems. In this paper, we present an empirical study that investigates bug-fix patterns in ADSes, with the aim of improving reliability and safety. We have analyzed the commit histories and bug reports of two major autonomous driving projects, Apollo and Autoware, from 1,331 bug fixes with the study of bug symptoms, root causes, and bug-fix patterns. Our study reveals several dominant bug-fix patterns, including those related to path planning, data flow, and configuration management. Additionally, we find that the frequency distribution of bug-fix patterns varies significantly depending on their nature and types and that certain categories of bugs are recurrent and more challenging to exterminate. Based on our findings, we propose a hierarchy of ADS bugs and two taxonomies of 15 syntactic bug-fix patterns and 27 semantic bug-fix patterns that offer guidance for bug identification and resolution. We also contribute a benchmark of 1,331 ADS bug-fix instances.
Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives
Jan 07, 2025



Recent advancements in Vision-Language Models (VLMs) have sparked interest in their use for autonomous driving, particularly in generating interpretable driving decisions through natural language. However, the assumption that VLMs inherently provide visually grounded, reliable, and interpretable explanations for driving remains largely unexamined. To address this gap, we introduce DriveBench, a benchmark dataset designed to evaluate VLM reliability across 17 settings (clean, corrupted, and text-only inputs), encompassing 19,200 frames, 20,498 question-answer pairs, three question types, four mainstream driving tasks, and a total of 12 popular VLMs. Our findings reveal that VLMs often generate plausible responses derived from general knowledge or textual cues rather than true visual grounding, especially under degraded or missing visual inputs. This behavior, concealed by dataset imbalances and insufficient evaluation metrics, poses significant risks in safety-critical scenarios like autonomous driving. We further observe that VLMs struggle with multi-modal reasoning and display heightened sensitivity to input corruptions, leading to inconsistencies in performance. To address these challenges, we propose refined evaluation metrics that prioritize robust visual grounding and multi-modal understanding. Additionally, we highlight the potential of leveraging VLMs' awareness of corruptions to enhance their reliability, offering a roadmap for developing more trustworthy and interpretable decision-making systems in real-world autonomous driving contexts. The benchmark toolkit is publicly accessible.
Revisiting Physical-World Adversarial Attack on Traffic Sign Recognition: A Commercial Systems Perspective
Sep 15, 2024Traffic Sign Recognition (TSR) is crucial for safe and correct driving automation. Recent works revealed a general vulnerability of TSR models to physical-world adversarial attacks, which can be low-cost, highly deployable, and capable of causing severe attack effects such as hiding a critical traffic sign or spoofing a fake one. However, so far existing works generally only considered evaluating the attack effects on academic TSR models, leaving the impacts of such attacks on real-world commercial TSR systems largely unclear. In this paper, we conduct the first large-scale measurement of physical-world adversarial attacks against commercial TSR systems. Our testing results reveal that it is possible for existing attack works from academia to have highly reliable (100\%) attack success against certain commercial TSR system functionality, but such attack capabilities are not generalizable, leading to much lower-than-expected attack success rates overall. We find that one potential major factor is a spatial memorization design that commonly exists in today's commercial TSR systems. We design new attack success metrics that can mathematically model the impacts of such design on the TSR system-level attack success, and use them to revisit existing attacks. Through these efforts, we uncover 7 novel observations, some of which directly challenge the observations or claims in prior works due to the introduction of the new metrics.
SlowPerception: Physical-World Latency Attack against Visual Perception in Autonomous Driving
Jun 09, 2024Autonomous Driving (AD) systems critically depend on visual perception for real-time object detection and multiple object tracking (MOT) to ensure safe driving. However, high latency in these visual perception components can lead to significant safety risks, such as vehicle collisions. While previous research has extensively explored latency attacks within the digital realm, translating these methods effectively to the physical world presents challenges. For instance, existing attacks rely on perturbations that are unrealistic or impractical for AD, such as adversarial perturbations affecting areas like the sky, or requiring large patches that obscure most of a camera's view, thus making them impossible to be conducted effectively in the real world. In this paper, we introduce SlowPerception, the first physical-world latency attack against AD perception, via generating projector-based universal perturbations. SlowPerception strategically creates numerous phantom objects on various surfaces in the environment, significantly increasing the computational load of Non-Maximum Suppression (NMS) and MOT, thereby inducing substantial latency. Our SlowPerception achieves second-level latency in physical-world settings, with an average latency of 2.5 seconds across different AD perception systems, scenarios, and hardware configurations. This performance significantly outperforms existing state-of-the-art latency attacks. Additionally, we conduct AD system-level impact assessments, such as vehicle collisions, using industry-grade AD systems with production-grade AD simulators with a 97% average rate. We hope that our analyses can inspire further research in this critical domain, enhancing the robustness of AD systems against emerging vulnerabilities.
ControlLoc: Physical-World Hijacking Attack on Visual Perception in Autonomous Driving
Jun 09, 2024



Recent research in adversarial machine learning has focused on visual perception in Autonomous Driving (AD) and has shown that printed adversarial patches can attack object detectors. However, it is important to note that AD visual perception encompasses more than just object detection; it also includes Multiple Object Tracking (MOT). MOT enhances the robustness by compensating for object detection errors and requiring consistent object detection results across multiple frames before influencing tracking results and driving decisions. Thus, MOT makes attacks on object detection alone less effective. To attack such robust AD visual perception, a digital hijacking attack has been proposed to cause dangerous driving scenarios. However, this attack has limited effectiveness. In this paper, we introduce a novel physical-world adversarial patch attack, ControlLoc, designed to exploit hijacking vulnerabilities in entire AD visual perception. ControlLoc utilizes a two-stage process: initially identifying the optimal location for the adversarial patch, and subsequently generating the patch that can modify the perceived location and shape of objects with the optimal location. Extensive evaluations demonstrate the superior performance of ControlLoc, achieving an impressive average attack success rate of around 98.1% across various AD visual perceptions and datasets, which is four times greater effectiveness than the existing hijacking attack. The effectiveness of ControlLoc is further validated in physical-world conditions, including real vehicle tests under different conditions such as outdoor light conditions with an average attack success rate of 77.5%. AD system-level impact assessments are also included, such as vehicle collision, using industry-grade AD systems and production-grade AD simulators with an average vehicle collision rate and unnecessary emergency stop rate of 81.3%.
Exploring Backdoor Attacks against Large Language Model-based Decision Making
May 27, 2024



Large Language Models (LLMs) have shown significant promise in decision-making tasks when fine-tuned on specific applications, leveraging their inherent common sense and reasoning abilities learned from vast amounts of data. However, these systems are exposed to substantial safety and security risks during the fine-tuning phase. In this work, we propose the first comprehensive framework for Backdoor Attacks against LLM-enabled Decision-making systems (BALD), systematically exploring how such attacks can be introduced during the fine-tuning phase across various channels. Specifically, we propose three attack mechanisms and corresponding backdoor optimization methods to attack different components in the LLM-based decision-making pipeline: word injection, scenario manipulation, and knowledge injection. Word injection embeds trigger words directly into the query prompt. Scenario manipulation occurs in the physical environment, where a high-level backdoor semantic scenario triggers the attack. Knowledge injection conducts backdoor attacks on retrieval augmented generation (RAG)-based LLM systems, strategically injecting word triggers into poisoned knowledge while ensuring the information remains factually accurate for stealthiness. We conduct extensive experiments with three popular LLMs (GPT-3.5, LLaMA2, PaLM2), using two datasets (HighwayEnv, nuScenes), and demonstrate the effectiveness and stealthiness of our backdoor triggers and mechanisms. Finally, we critically assess the strengths and weaknesses of our proposed approaches, highlight the inherent vulnerabilities of LLMs in decision-making tasks, and evaluate potential defenses to safeguard LLM-based decision making systems.