 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025

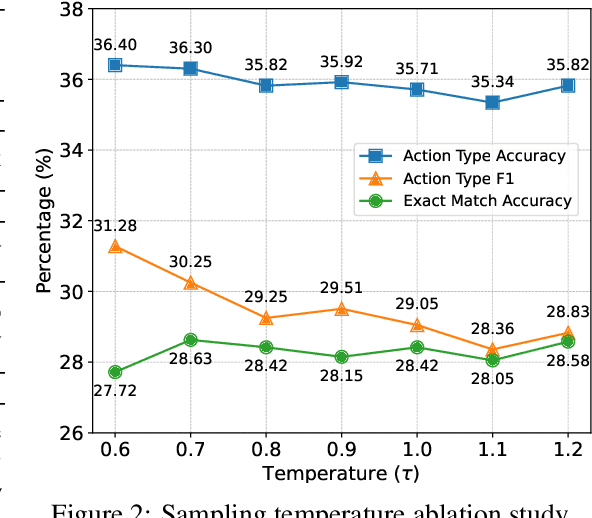

Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.
Inverse Delayed Reinforcement Learning
Dec 04, 2024



Inverse Reinforcement Learning (IRL) has demonstrated effectiveness in a variety of imitation tasks. In this paper, we introduce an IRL framework designed to extract rewarding features from expert trajectories affected by delayed disturbances. Instead of relying on direct observations, our approach employs an efficient off-policy adversarial training framework to derive expert features and recover optimal policies from augmented delayed observations. Empirical evaluations in the MuJoCo environment under diverse delay settings validate the effectiveness of our method. Furthermore, we provide a theoretical analysis showing that recovering expert policies from augmented delayed observations outperforms using direct delayed observations.
Model-Based Reward Shaping for Adversarial Inverse Reinforcement Learning in Stochastic Environments
Oct 04, 2024



In this paper, we aim to tackle the limitation of the Adversarial Inverse Reinforcement Learning (AIRL) method in stochastic environments where theoretical results cannot hold and performance is degraded. To address this issue, we propose a novel method which infuses the dynamics information into the reward shaping with the theoretical guarantee for the induced optimal policy in the stochastic environments. Incorporating our novel model-enhanced rewards, we present a novel Model-Enhanced AIRL framework, which integrates transition model estimation directly into reward shaping. Furthermore, we provide a comprehensive theoretical analysis of the reward error bound and performance difference bound for our method. The experimental results in MuJoCo benchmarks show that our method can achieve superior performance in stochastic environments and competitive performance in deterministic environments, with significant improvement in sample efficiency, compared to existing baselines.
Exploring Backdoor Attacks against Large Language Model-based Decision Making
May 27, 2024



Large Language Models (LLMs) have shown significant promise in decision-making tasks when fine-tuned on specific applications, leveraging their inherent common sense and reasoning abilities learned from vast amounts of data. However, these systems are exposed to substantial safety and security risks during the fine-tuning phase. In this work, we propose the first comprehensive framework for Backdoor Attacks against LLM-enabled Decision-making systems (BALD), systematically exploring how such attacks can be introduced during the fine-tuning phase across various channels. Specifically, we propose three attack mechanisms and corresponding backdoor optimization methods to attack different components in the LLM-based decision-making pipeline: word injection, scenario manipulation, and knowledge injection. Word injection embeds trigger words directly into the query prompt. Scenario manipulation occurs in the physical environment, where a high-level backdoor semantic scenario triggers the attack. Knowledge injection conducts backdoor attacks on retrieval augmented generation (RAG)-based LLM systems, strategically injecting word triggers into poisoned knowledge while ensuring the information remains factually accurate for stealthiness. We conduct extensive experiments with three popular LLMs (GPT-3.5, LLaMA2, PaLM2), using two datasets (HighwayEnv, nuScenes), and demonstrate the effectiveness and stealthiness of our backdoor triggers and mechanisms. Finally, we critically assess the strengths and weaknesses of our proposed approaches, highlight the inherent vulnerabilities of LLMs in decision-making tasks, and evaluate potential defenses to safeguard LLM-based decision making systems.
Empowering Autonomous Driving with Large Language Models: A Safety Perspective
Nov 28, 2023Autonomous Driving (AD) faces crucial hurdles for commercial launch, notably in the form of diminished public trust and safety concerns from long-tail unforeseen driving scenarios. This predicament is due to the limitation of deep neural networks in AD software, which struggle with interpretability and exhibit poor generalization capabilities in out-of-distribution and uncertain scenarios. To this end, this paper advocates for the integration of Large Language Models (LLMs) into the AD system, leveraging their robust common-sense knowledge, reasoning abilities, and human-interaction capabilities. The proposed approach deploys the LLM as an intelligent decision-maker in planning, incorporating safety verifiers for contextual safety learning to enhance overall AD performance and safety. We present results from two case studies that affirm the efficacy of our approach. We further discuss the potential integration of LLM for other AD software components including perception, prediction, and simulation. Despite the observed challenges in the case studies, the integration of LLMs is promising and beneficial for reinforcing both safety and performance in AD.
State-wise Safe Reinforcement Learning With Pixel Observations
Nov 03, 2023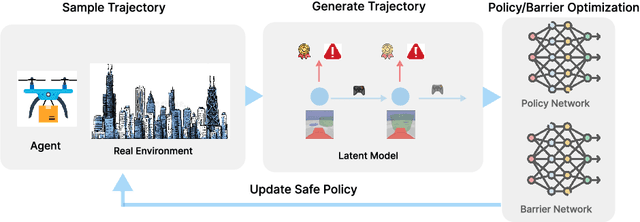
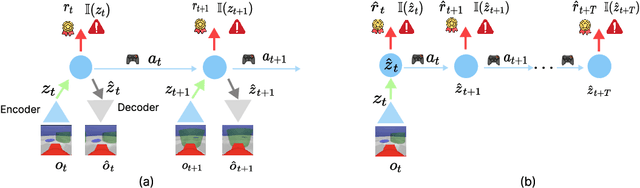
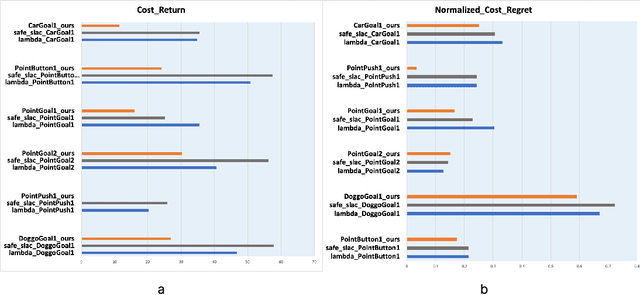
Reinforcement Learning(RL) in the context of safe exploration has long grappled with the challenges of the delicate balance between maximizing rewards and minimizing safety violations, the complexities arising from contact-rich or non-smooth environments, and high-dimensional pixel observations. Furthermore, incorporating state-wise safety constraints in the exploration and learning process, where the agent is prohibited from accessing unsafe regions without prior knowledge, adds an additional layer of complexity. In this paper, we propose a novel pixel-observation safe RL algorithm that efficiently encodes state-wise safety constraints with unknown hazard regions through the introduction of a latent barrier function learning mechanism. As a joint learning framework, our approach first involves constructing a latent dynamics model with low-dimensional latent spaces derived from pixel observations. Subsequently, we build and learn a latent barrier function on top of the latent dynamics and conduct policy optimization simultaneously, thereby improving both safety and the total expected return. Experimental evaluations on the safety-gym benchmark suite demonstrate that our proposed method significantly reduces safety violations throughout the training process and demonstrates faster safety convergence compared to existing methods while achieving competitive results in reward return.
Kinematics-aware Trajectory Generation and Prediction with Latent Stochastic Differential Modeling
Sep 17, 2023Trajectory generation and trajectory prediction are two critical tasks for autonomous vehicles, which generate various trajectories during development and predict the trajectories of surrounding vehicles during operation, respectively. However, despite significant advances in improving their performance, it remains a challenging problem to ensure that the generated/predicted trajectories are realistic, explainable, and physically feasible. Existing model-based methods provide explainable results, but are constrained by predefined model structures, limiting their capabilities to address complex scenarios. Conversely, existing deep learning-based methods have shown great promise in learning various traffic scenarios and improving overall performance, but they often act as opaque black boxes and lack explainability. In this work, we integrate kinematic knowledge with neural stochastic differential equations (SDE) and develop a variational autoencoder based on a novel latent kinematics-aware SDE (LK-SDE) to generate vehicle motions. Our approach combines the advantages of both model-based and deep learning-based techniques. Experimental results demonstrate that our method significantly outperforms baseline approaches in producing realistic, physically-feasible, and precisely-controllable vehicle trajectories, benefiting both generation and prediction tasks.
Safety-Assured Speculative Planning with Adaptive Prediction
Jul 21, 2023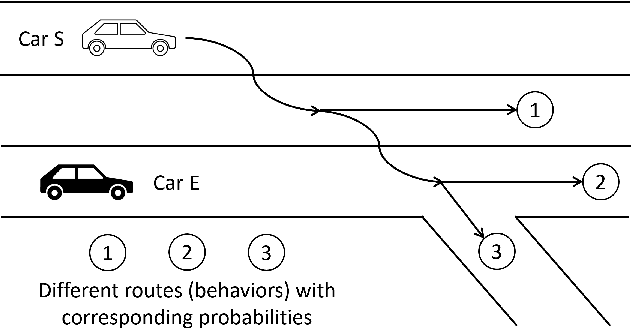
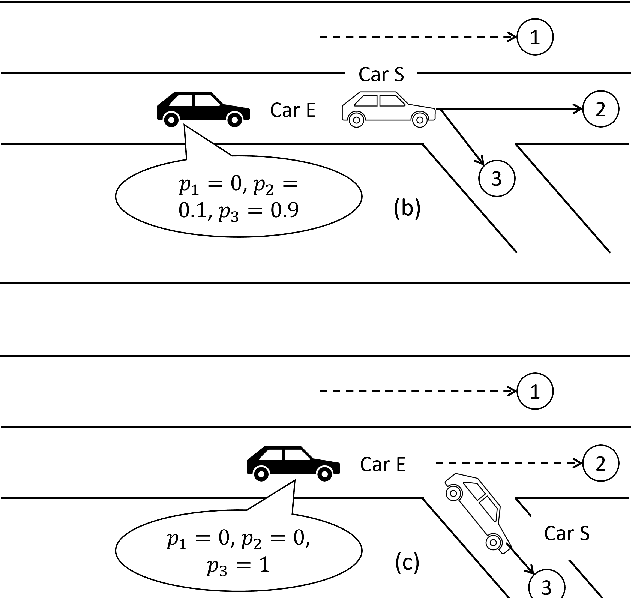
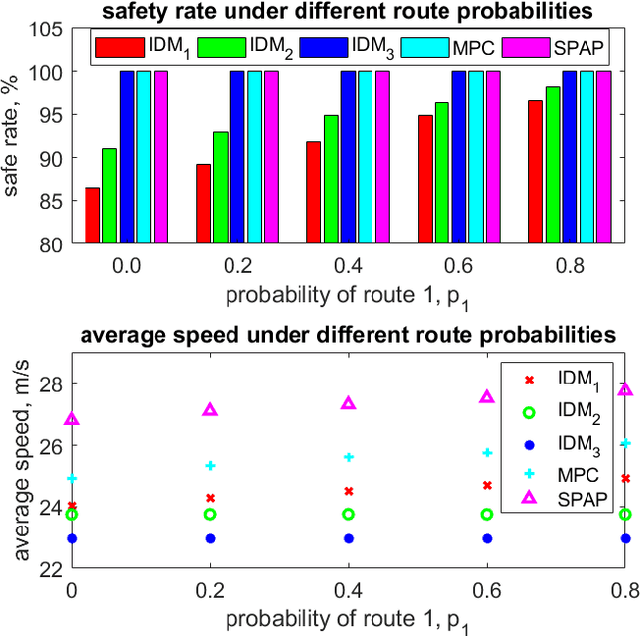
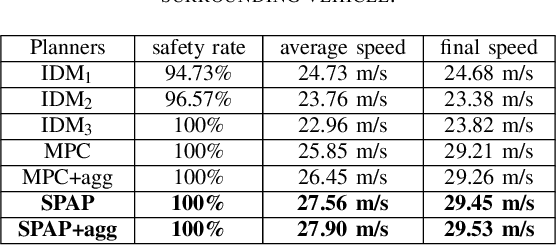
Recently significant progress has been made in vehicle prediction and planning algorithms for autonomous driving. However, it remains quite challenging for an autonomous vehicle to plan its trajectory in complex scenarios when it is difficult to accurately predict its surrounding vehicles' behaviors and trajectories. In this work, to maximize performance while ensuring safety, we propose a novel speculative planning framework based on a prediction-planning interface that quantifies both the behavior-level and trajectory-level uncertainties of surrounding vehicles. Our framework leverages recent prediction algorithms that can provide one or more possible behaviors and trajectories of the surrounding vehicles with probability estimation. It adapts those predictions based on the latest system states and traffic environment, and conducts planning to maximize the expected reward of the ego vehicle by considering the probabilistic predictions of all scenarios and ensure system safety by ruling out actions that may be unsafe in worst case. We demonstrate the effectiveness of our approach in improving system performance and ensuring system safety over other baseline methods, via extensive simulations in SUMO on a challenging multi-lane highway lane-changing case study.
Learning Representation for Anomaly Detection of Vehicle Trajectories
Mar 09, 2023Predicting the future trajectories of surrounding vehicles based on their history trajectories is a critical task in autonomous driving. However, when small crafted perturbations are introduced to those history trajectories, the resulting anomalous (or adversarial) trajectories can significantly mislead the future trajectory prediction module of the ego vehicle, which may result in unsafe planning and even fatal accidents. Therefore, it is of great importance to detect such anomalous trajectories of the surrounding vehicles for system safety, but few works have addressed this issue. In this work, we propose two novel methods for learning effective and efficient representations for online anomaly detection of vehicle trajectories. Different from general time-series anomaly detection, anomalous vehicle trajectory detection deals with much richer contexts on the road and fewer observable patterns on the anomalous trajectories themselves. To address these challenges, our methods exploit contrastive learning techniques and trajectory semantics to capture the patterns underlying the driving scenarios for effective anomaly detection under supervised and unsupervised settings, respectively. We conduct extensive experiments to demonstrate that our supervised method based on contrastive learning and unsupervised method based on reconstruction with semantic latent space can significantly improve the performance of anomalous trajectory detection in their corresponding settings over various baseline methods. We also demonstrate our methods' generalization ability to detect unseen patterns of anomalies.
Connectivity Enhanced Safe Neural Network Planner for Lane Changing in Mixed Traffic
Feb 06, 2023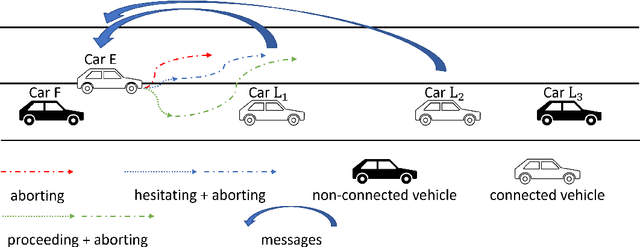
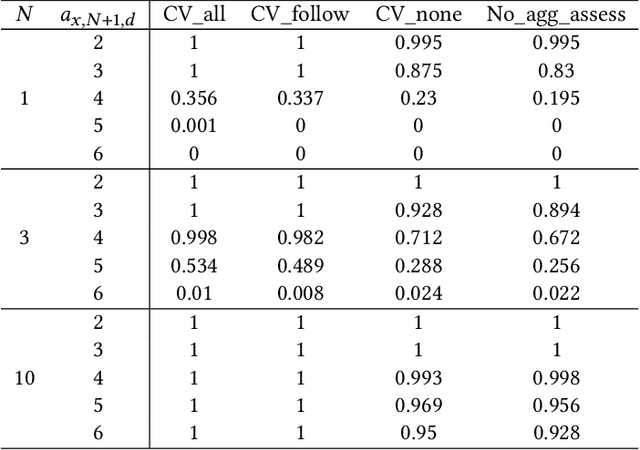
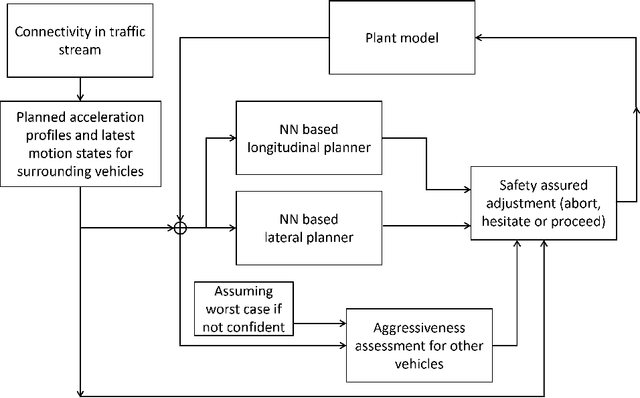
Connectivity technology has shown great potentials in improving the safety and efficiency of transportation systems by providing information beyond the perception and prediction capabilities of individual vehicles. However, it is expected that human-driven and autonomous vehicles, and connected and non-connected vehicles need to share the transportation network during the transition period to fully connected and automated transportation systems. Such mixed traffic scenarios significantly increase the complexity in analyzing system behavior and quantifying uncertainty for highly interactive scenarios, e.g., lane changing. It is even harder to ensure system safety when neural network based planners are leveraged to further improve efficiency. In this work, we propose a connectivity-enhanced neural network based lane changing planner. By cooperating with surrounding connected vehicles in dynamic environment, our proposed planner will adapt its planned trajectory according to the analysis of a safe evasion trajectory. We demonstrate the strength of our planner design in improving efficiency and ensuring safety in various mixed traffic scenarios with extensive simulations. We also analyze the system robustness when the communication or coordination is not perfect.