 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI for Auto-Research: Roadmap & User Guide
May 18, 2026AI-assisted research is crossing a threshold: fully automated systems can now generate research papers for as little as $15, while long-horizon agents can execute experiments, draft manuscripts, and simulate critique with minimal human input. Yet this productivity frontier exposes a deeper integrity problem: under scientific pressure, even frontier LLMs still fabricate results, miss hidden errors, and fail to judge novelty reliably. Studying developments through April 2026, we present an end-to-end analysis of AI across the complete research lifecycle, organized into four epistemological phases: Creation (idea generation, literature review, coding & experiments, tables & figures), Writing (paper writing), Validation (peer review, rebuttal & revision), and Dissemination (posters, slides, videos, social media, project pages, and interactive agents). We identify a sharp, stage-dependent boundary between reliable assistance and unreliable autonomy: AI excels at structured, retrieval-grounded, and tool-mediated tasks, but remains fragile for genuinely novel ideas, research-level experiments, and scientific judgment. Generated ideas often degrade after implementation, research code lags far behind pattern-matching benchmarks, and end-to-end autonomous systems have not yet consistently reached major-venue acceptance standards. We further show that greater automation can obscure rather than eliminate failure modes, making human-governed collaboration the most credible deployment paradigm. Finally, we provide a structured taxonomy, benchmark suite, and tool inventory, cross-stage design principles, and a practitioner-oriented playbook, with resources maintained at our project page.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
PaniCar: Securing the Perception of Advanced Driving Assistance Systems Against Emergency Vehicle Lighting
May 08, 2025
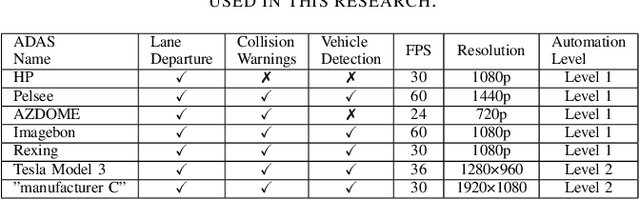

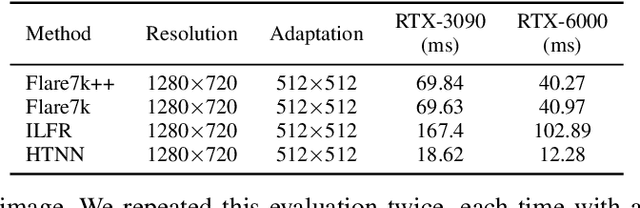
The safety of autonomous cars has come under scrutiny in recent years, especially after 16 documented incidents involving Teslas (with autopilot engaged) crashing into parked emergency vehicles (police cars, ambulances, and firetrucks). While previous studies have revealed that strong light sources often introduce flare artifacts in the captured image, which degrade the image quality, the impact of flare on object detection performance remains unclear. In this research, we unveil PaniCar, a digital phenomenon that causes an object detector's confidence score to fluctuate below detection thresholds when exposed to activated emergency vehicle lighting. This vulnerability poses a significant safety risk, and can cause autonomous vehicles to fail to detect objects near emergency vehicles. In addition, this vulnerability could be exploited by adversaries to compromise the security of advanced driving assistance systems (ADASs). We assess seven commercial ADASs (Tesla Model 3, "manufacturer C", HP, Pelsee, AZDOME, Imagebon, Rexing), four object detectors (YOLO, SSD, RetinaNet, Faster R-CNN), and 14 patterns of emergency vehicle lighting to understand the influence of various technical and environmental factors. We also evaluate four SOTA flare removal methods and show that their performance and latency are insufficient for real-time driving constraints. To mitigate this risk, we propose Caracetamol, a robust framework designed to enhance the resilience of object detectors against the effects of activated emergency vehicle lighting. Our evaluation shows that on YOLOv3 and Faster RCNN, Caracetamol improves the models' average confidence of car detection by 0.20, the lower confidence bound by 0.33, and reduces the fluctuation range by 0.33. In addition, Caracetamol is capable of processing frames at a rate of between 30-50 FPS, enabling real-time ADAS car detection.
Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives
Jan 07, 2025



Recent advancements in Vision-Language Models (VLMs) have sparked interest in their use for autonomous driving, particularly in generating interpretable driving decisions through natural language. However, the assumption that VLMs inherently provide visually grounded, reliable, and interpretable explanations for driving remains largely unexamined. To address this gap, we introduce DriveBench, a benchmark dataset designed to evaluate VLM reliability across 17 settings (clean, corrupted, and text-only inputs), encompassing 19,200 frames, 20,498 question-answer pairs, three question types, four mainstream driving tasks, and a total of 12 popular VLMs. Our findings reveal that VLMs often generate plausible responses derived from general knowledge or textual cues rather than true visual grounding, especially under degraded or missing visual inputs. This behavior, concealed by dataset imbalances and insufficient evaluation metrics, poses significant risks in safety-critical scenarios like autonomous driving. We further observe that VLMs struggle with multi-modal reasoning and display heightened sensitivity to input corruptions, leading to inconsistencies in performance. To address these challenges, we propose refined evaluation metrics that prioritize robust visual grounding and multi-modal understanding. Additionally, we highlight the potential of leveraging VLMs' awareness of corruptions to enhance their reliability, offering a roadmap for developing more trustworthy and interpretable decision-making systems in real-world autonomous driving contexts. The benchmark toolkit is publicly accessible.
Revisiting Physical-World Adversarial Attack on Traffic Sign Recognition: A Commercial Systems Perspective
Sep 15, 2024Traffic Sign Recognition (TSR) is crucial for safe and correct driving automation. Recent works revealed a general vulnerability of TSR models to physical-world adversarial attacks, which can be low-cost, highly deployable, and capable of causing severe attack effects such as hiding a critical traffic sign or spoofing a fake one. However, so far existing works generally only considered evaluating the attack effects on academic TSR models, leaving the impacts of such attacks on real-world commercial TSR systems largely unclear. In this paper, we conduct the first large-scale measurement of physical-world adversarial attacks against commercial TSR systems. Our testing results reveal that it is possible for existing attack works from academia to have highly reliable (100\%) attack success against certain commercial TSR system functionality, but such attack capabilities are not generalizable, leading to much lower-than-expected attack success rates overall. We find that one potential major factor is a spatial memorization design that commonly exists in today's commercial TSR systems. We design new attack success metrics that can mathematically model the impacts of such design on the TSR system-level attack success, and use them to revisit existing attacks. Through these efforts, we uncover 7 novel observations, some of which directly challenge the observations or claims in prior works due to the introduction of the new metrics.
Benchmarking and Improving Bird's Eye View Perception Robustness in Autonomous Driving
May 27, 2024
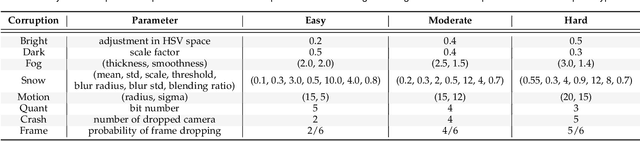


Recent advancements in bird's eye view (BEV) representations have shown remarkable promise for in-vehicle 3D perception. However, while these methods have achieved impressive results on standard benchmarks, their robustness in varied conditions remains insufficiently assessed. In this study, we present RoboBEV, an extensive benchmark suite designed to evaluate the resilience of BEV algorithms. This suite incorporates a diverse set of camera corruption types, each examined over three severity levels. Our benchmarks also consider the impact of complete sensor failures that occur when using multi-modal models. Through RoboBEV, we assess 33 state-of-the-art BEV-based perception models spanning tasks like detection, map segmentation, depth estimation, and occupancy prediction. Our analyses reveal a noticeable correlation between the model's performance on in-distribution datasets and its resilience to out-of-distribution challenges. Our experimental results also underline the efficacy of strategies like pre-training and depth-free BEV transformations in enhancing robustness against out-of-distribution data. Furthermore, we observe that leveraging extensive temporal information significantly improves the model's robustness. Based on our observations, we design an effective robustness enhancement strategy based on the CLIP model. The insights from this study pave the way for the development of future BEV models that seamlessly combine accuracy with real-world robustness.
Exploring Backdoor Attacks against Large Language Model-based Decision Making
May 27, 2024



Large Language Models (LLMs) have shown significant promise in decision-making tasks when fine-tuned on specific applications, leveraging their inherent common sense and reasoning abilities learned from vast amounts of data. However, these systems are exposed to substantial safety and security risks during the fine-tuning phase. In this work, we propose the first comprehensive framework for Backdoor Attacks against LLM-enabled Decision-making systems (BALD), systematically exploring how such attacks can be introduced during the fine-tuning phase across various channels. Specifically, we propose three attack mechanisms and corresponding backdoor optimization methods to attack different components in the LLM-based decision-making pipeline: word injection, scenario manipulation, and knowledge injection. Word injection embeds trigger words directly into the query prompt. Scenario manipulation occurs in the physical environment, where a high-level backdoor semantic scenario triggers the attack. Knowledge injection conducts backdoor attacks on retrieval augmented generation (RAG)-based LLM systems, strategically injecting word triggers into poisoned knowledge while ensuring the information remains factually accurate for stealthiness. We conduct extensive experiments with three popular LLMs (GPT-3.5, LLaMA2, PaLM2), using two datasets (HighwayEnv, nuScenes), and demonstrate the effectiveness and stealthiness of our backdoor triggers and mechanisms. Finally, we critically assess the strengths and weaknesses of our proposed approaches, highlight the inherent vulnerabilities of LLMs in decision-making tasks, and evaluate potential defenses to safeguard LLM-based decision making systems.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024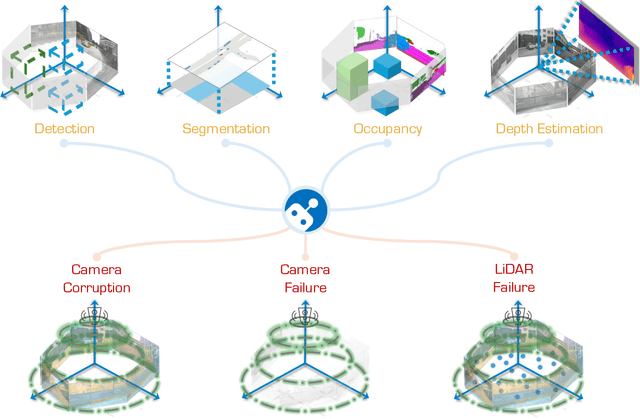


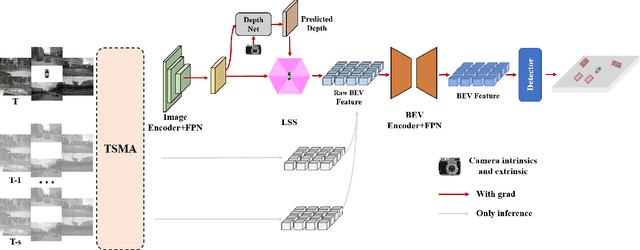
In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
RoboDepth: Robust Out-of-Distribution Depth Estimation under Corruptions
Oct 23, 2023Depth estimation from monocular images is pivotal for real-world visual perception systems. While current learning-based depth estimation models train and test on meticulously curated data, they often overlook out-of-distribution (OoD) situations. Yet, in practical settings -- especially safety-critical ones like autonomous driving -- common corruptions can arise. Addressing this oversight, we introduce a comprehensive robustness test suite, RoboDepth, encompassing 18 corruptions spanning three categories: i) weather and lighting conditions; ii) sensor failures and movement; and iii) data processing anomalies. We subsequently benchmark 42 depth estimation models across indoor and outdoor scenes to assess their resilience to these corruptions. Our findings underscore that, in the absence of a dedicated robustness evaluation framework, many leading depth estimation models may be susceptible to typical corruptions. We delve into design considerations for crafting more robust depth estimation models, touching upon pre-training, augmentation, modality, model capacity, and learning paradigms. We anticipate our benchmark will establish a foundational platform for advancing robust OoD depth estimation.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.