 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepAudio 2.5 Technical Report
May 22, 2026Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
Tackling Length Inflation Without Trade-offs: Group Relative Reward Rescaling for Reinforcement Learning
Mar 11, 2026Reinforcement learning significantly enhances LLM capabilities but suffers from a critical issue: length inflation, where models adopt verbosity or inefficient reasoning to maximize rewards. Prior approaches struggle to address this challenge in a general and lossless manner, primarily because additive penalties introduce a compensatory effect that creates optimization shortcuts, while heuristic gating strategies lack generality beyond binary feedback. To bridge this gap, we present Group Relative Reward Rescaling (GR$^3$), which reframes length control as a multiplicative rescaling paradigm, effectively establishing a generalized, continuous, and reward-dependent gating mechanism. To further ensure lossless optimization, we incorporate group-relative regularization and advantage-aware calibration, which dynamically adapt length budgets to instance difficulty and preserve the advantage signal of high-quality trajectories. Empirically, across both RLHF and RLVR settings, GR$^3$~maintains training dynamics and downstream performance comparable to standard GRPO while significantly mitigating length inflation, outperforming state-of-the-art length-regularized baselines.
VLM-Guided Iterative Refinement for Surgical Image Segmentation with Foundation Models
Feb 09, 2026Surgical image segmentation is essential for robot-assisted surgery and intraoperative guidance. However, existing methods are constrained to predefined categories, produce one-shot predictions without adaptive refinement, and lack mechanisms for clinician interaction. We propose IR-SIS, an iterative refinement system for surgical image segmentation that accepts natural language descriptions. IR-SIS leverages a fine-tuned SAM3 for initial segmentation, employs a Vision-Language Model to detect instruments and assess segmentation quality, and applies an agentic workflow that adaptively selects refinement strategies. The system supports clinician-in-the-loop interaction through natural language feedback. We also construct a multi-granularity language-annotated dataset from EndoVis2017 and EndoVis2018 benchmarks. Experiments demonstrate state-of-the-art performance on both in-domain and out-of-distribution data, with clinician interaction providing additional improvements. Our work establishes the first language-based surgical segmentation framework with adaptive self-refinement capabilities.
dots.llm1 Technical Report
Jun 06, 2025Mixture of Experts (MoE) models have emerged as a promising paradigm for scaling language models efficiently by activating only a subset of parameters for each input token. In this report, we present dots.llm1, a large-scale MoE model that activates 14B parameters out of a total of 142B parameters, delivering performance on par with state-of-the-art models while reducing training and inference costs. Leveraging our meticulously crafted and efficient data processing pipeline, dots.llm1 achieves performance comparable to Qwen2.5-72B after pretraining on 11.2T high-quality tokens and post-training to fully unlock its capabilities. Notably, no synthetic data is used during pretraining. To foster further research, we open-source intermediate training checkpoints at every one trillion tokens, providing valuable insights into the learning dynamics of large language models.
Collaborative Memory: Multi-User Memory Sharing in LLM Agents with Dynamic Access Control
May 23, 2025Complex tasks are increasingly delegated to ensembles of specialized LLM-based agents that reason, communicate, and coordinate actions-both among themselves and through interactions with external tools, APIs, and databases. While persistent memory has been shown to enhance single-agent performance, most approaches assume a monolithic, single-user context-overlooking the benefits and challenges of knowledge transfer across users under dynamic, asymmetric permissions. We introduce Collaborative Memory, a framework for multi-user, multi-agent environments with asymmetric, time-evolving access controls encoded as bipartite graphs linking users, agents, and resources. Our system maintains two memory tiers: (1) private memory-private fragments visible only to their originating user; and (2) shared memory-selectively shared fragments. Each fragment carries immutable provenance attributes (contributing agents, accessed resources, and timestamps) to support retrospective permission checks. Granular read policies enforce current user-agent-resource constraints and project existing memory fragments into filtered transformed views. Write policies determine fragment retention and sharing, applying context-aware transformations to update the memory. Both policies may be designed conditioned on system, agent, and user-level information. Our framework enables safe, efficient, and interpretable cross-user knowledge sharing, with provable adherence to asymmetric, time-varying policies and full auditability of memory operations.
The Devil Is in the Details: Tackling Unimodal Spurious Correlations for Generalizable Multimodal Reward Models
Mar 05, 2025Multimodal Reward Models (MM-RMs) are crucial for aligning Large Language Models (LLMs) with human preferences, particularly as LLMs increasingly interact with multimodal data. However, we find that MM-RMs trained on existing datasets often struggle to generalize to out-of-distribution data due to their reliance on unimodal spurious correlations, primarily text-only shortcuts within the training distribution, which prevents them from leveraging true multimodal reward functions. To address this, we introduce a Shortcut-aware MM-RM learning algorithm that mitigates this issue by dynamically reweighting training samples, shifting the distribution toward better multimodal understanding, and reducing dependence on unimodal spurious correlations. Our experiments demonstrate significant improvements in generalization, downstream task performance, and scalability, establishing a more robust framework for multimodal reward modeling.
Cheems: A Practical Guidance for Building and Evaluating Chinese Reward Models from Scratch
Feb 24, 2025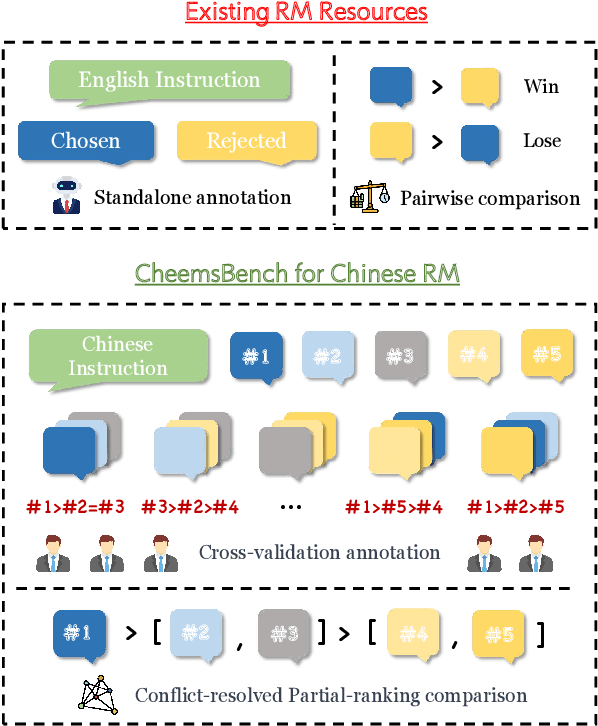
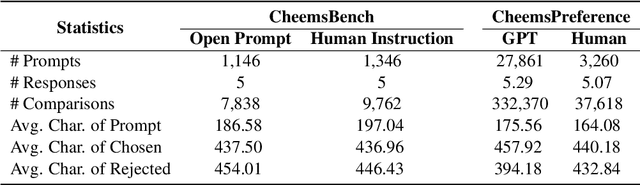
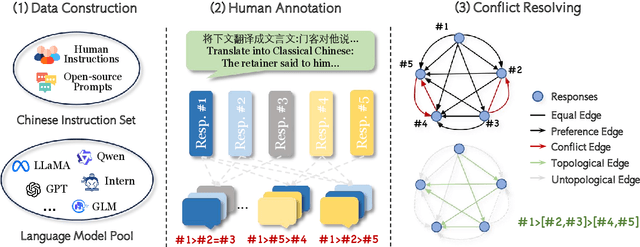
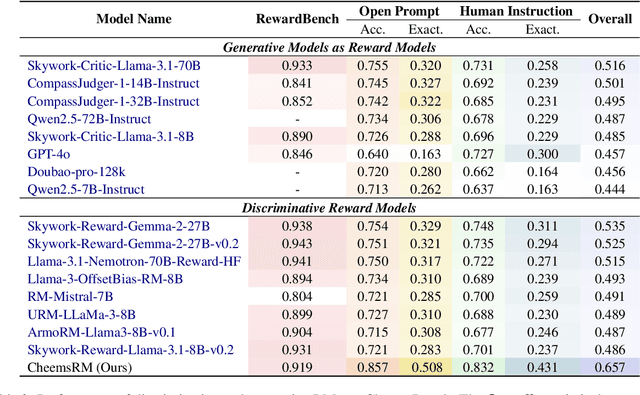
Reward models (RMs) are crucial for aligning large language models (LLMs) with human preferences. However, most RM research is centered on English and relies heavily on synthetic resources, which leads to limited and less reliable datasets and benchmarks for Chinese. To address this gap, we introduce CheemsBench, a fully human-annotated RM evaluation benchmark within Chinese contexts, and CheemsPreference, a large-scale and diverse preference dataset annotated through human-machine collaboration to support Chinese RM training. We systematically evaluate open-source discriminative and generative RMs on CheemsBench and observe significant limitations in their ability to capture human preferences in Chinese scenarios. Additionally, based on CheemsPreference, we construct an RM that achieves state-of-the-art performance on CheemsBench, demonstrating the necessity of human supervision in RM training. Our findings reveal that scaled AI-generated data struggles to fully capture human preferences, emphasizing the importance of high-quality human supervision in RM development.
ReTreever: Tree-based Coarse-to-Fine Representations for Retrieval
Feb 11, 2025Document retrieval is a core component of question-answering systems, as it enables conditioning answer generation on new and large-scale corpora. While effective, the standard practice of encoding documents into high-dimensional embeddings for similarity search entails large memory and compute footprints, and also makes it hard to inspect the inner workings of the system. In this paper, we propose a tree-based method for organizing and representing reference documents at various granular levels, which offers the flexibility to balance cost and utility, and eases the inspection of the corpus content and retrieval operations. Our method, called ReTreever, jointly learns a routing function per internal node of a binary tree such that query and reference documents are assigned to similar tree branches, hence directly optimizing for retrieval performance. Our evaluations show that ReTreever generally preserves full representation accuracy. Its hierarchical structure further provides strong coarse representations and enhances transparency by indirectly learning meaningful semantic groupings. Among hierarchical retrieval methods, ReTreever achieves the best retrieval accuracy at the lowest latency, proving that this family of techniques can be viable in practical applications.
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
From Isolated Conversations to Hierarchical Schemas: Dynamic Tree Memory Representation for LLMs
Oct 17, 2024

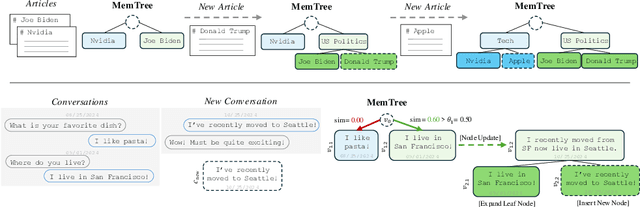

Recent advancements in large language models have significantly improved their context windows, yet challenges in effective long-term memory management remain. We introduce MemTree, an algorithm that leverages a dynamic, tree-structured memory representation to optimize the organization, retrieval, and integration of information, akin to human cognitive schemas. MemTree organizes memory hierarchically, with each node encapsulating aggregated textual content, corresponding semantic embeddings, and varying abstraction levels across the tree's depths. Our algorithm dynamically adapts this memory structure by computing and comparing semantic embeddings of new and existing information to enrich the model's context-awareness. This approach allows MemTree to handle complex reasoning and extended interactions more effectively than traditional memory augmentation methods, which often rely on flat lookup tables. Evaluations on benchmarks for multi-turn dialogue understanding and document question answering show that MemTree significantly enhances performance in scenarios that demand structured memory management.