 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Facet Counterfactual Learning for Content Quality Evaluation
Oct 10, 2024
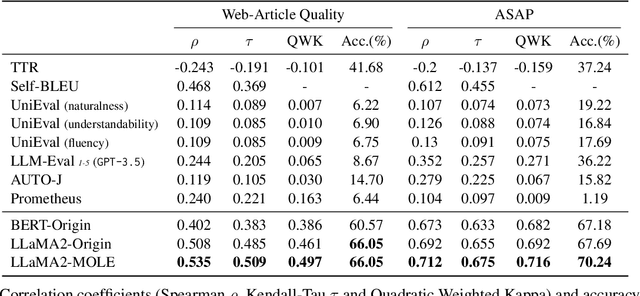

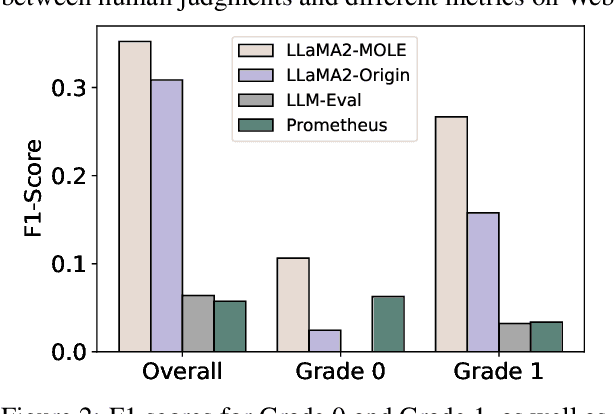
Evaluating the quality of documents is essential for filtering valuable content from the current massive amount of information. Conventional approaches typically rely on a single score as a supervision signal for training content quality evaluators, which is inadequate to differentiate documents with quality variations across multiple facets. In this paper, we propose Multi-facet cOunterfactual LEarning (MOLE), a framework for efficiently constructing evaluators that perceive multiple facets of content quality evaluation. Given a specific scenario, we prompt large language models to generate counterfactual content that exhibits variations in critical quality facets compared to the original document. Furthermore, we leverage a joint training strategy based on contrastive learning and supervised learning to enable the evaluator to distinguish between different quality facets, resulting in more accurate predictions of content quality scores. Experimental results on 2 datasets across different scenarios demonstrate that our proposed MOLE framework effectively improves the correlation of document content quality evaluations with human judgments, which serve as a valuable toolkit for effective information acquisition.
Seg2Act: Global Context-aware Action Generation for Document Logical Structuring
Oct 09, 2024



Document logical structuring aims to extract the underlying hierarchical structure of documents, which is crucial for document intelligence. Traditional approaches often fall short in handling the complexity and the variability of lengthy documents. To address these issues, we introduce Seg2Act, an end-to-end, generation-based method for document logical structuring, revisiting logical structure extraction as an action generation task. Specifically, given the text segments of a document, Seg2Act iteratively generates the action sequence via a global context-aware generative model, and simultaneously updates its global context and current logical structure based on the generated actions. Experiments on ChCatExt and HierDoc datasets demonstrate the superior performance of Seg2Act in both supervised and transfer learning settings.
ECO v1: Towards Event-Centric Opinion Mining
Mar 23, 2022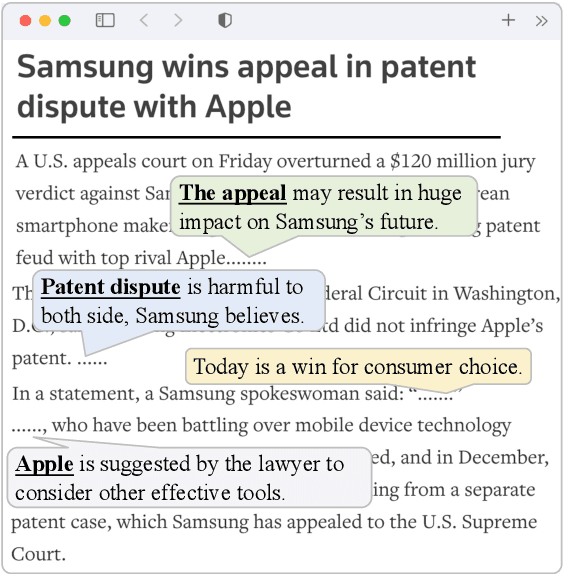

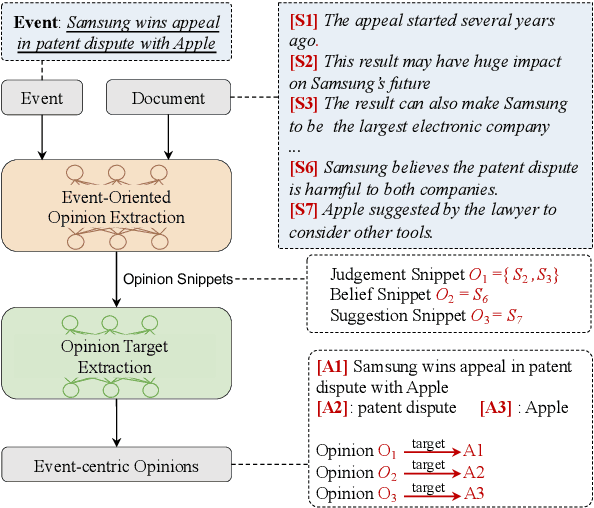
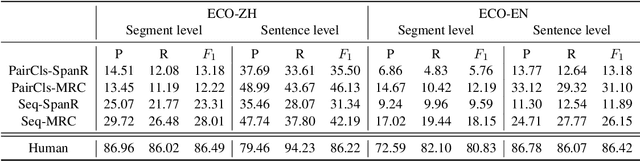
Events are considered as the fundamental building blocks of the world. Mining event-centric opinions can benefit decision making, people communication, and social good. Unfortunately, there is little literature addressing event-centric opinion mining, although which significantly diverges from the well-studied entity-centric opinion mining in connotation, structure, and expression. In this paper, we propose and formulate the task of event-centric opinion mining based on event-argument structure and expression categorizing theory. We also benchmark this task by constructing a pioneer corpus and designing a two-step benchmark framework. Experiment results show that event-centric opinion mining is feasible and challenging, and the proposed task, dataset, and baselines are beneficial for future studies.
Procedural Text Understanding via Scene-Wise Evolution
Mar 15, 2022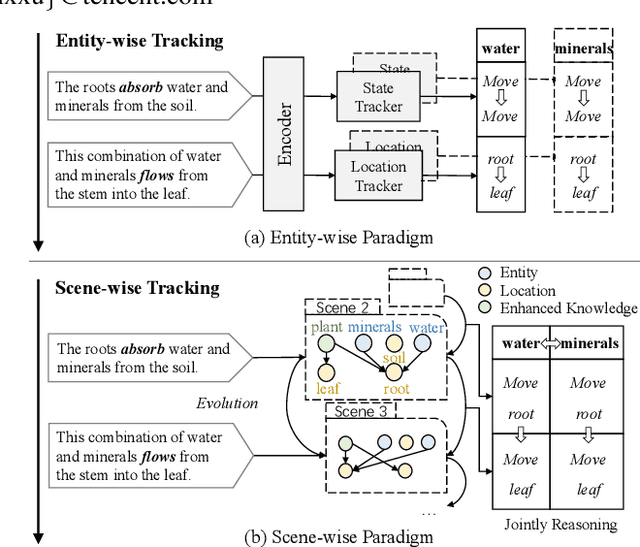

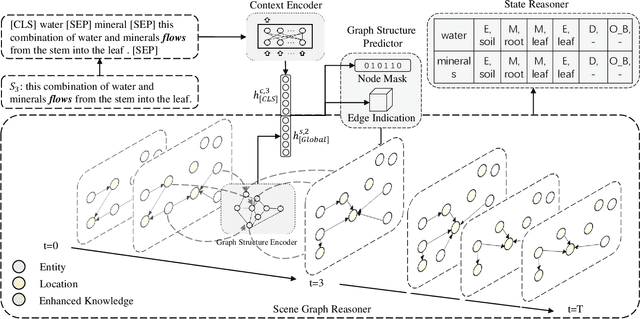
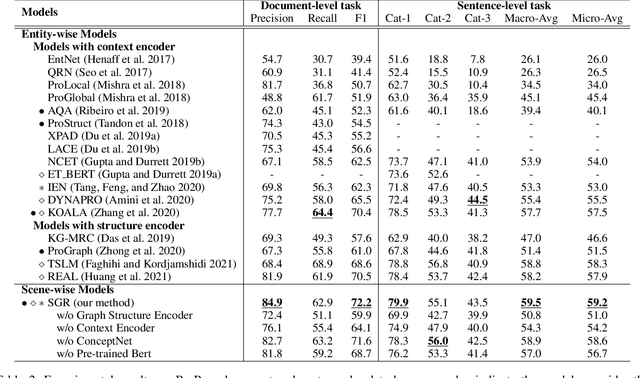
Procedural text understanding requires machines to reason about entity states within the dynamical narratives. Current procedural text understanding approaches are commonly \textbf{entity-wise}, which separately track each entity and independently predict different states of each entity. Such an entity-wise paradigm does not consider the interaction between entities and their states. In this paper, we propose a new \textbf{scene-wise} paradigm for procedural text understanding, which jointly tracks states of all entities in a scene-by-scene manner. Based on this paradigm, we propose \textbf{S}cene \textbf{G}raph \textbf{R}easoner (\textbf{SGR}), which introduces a series of dynamically evolving scene graphs to jointly formulate the evolution of entities, states and their associations throughout the narrative. In this way, the deep interactions between all entities and states can be jointly captured and simultaneously derived from scene graphs. Experiments show that SGR not only achieves the new state-of-the-art performance but also significantly accelerates the speed of reasoning.
* 9 pages, 2 figures
Text2Event: Controllable Sequence-to-Structure Generation for End-to-end Event Extraction
Jun 17, 2021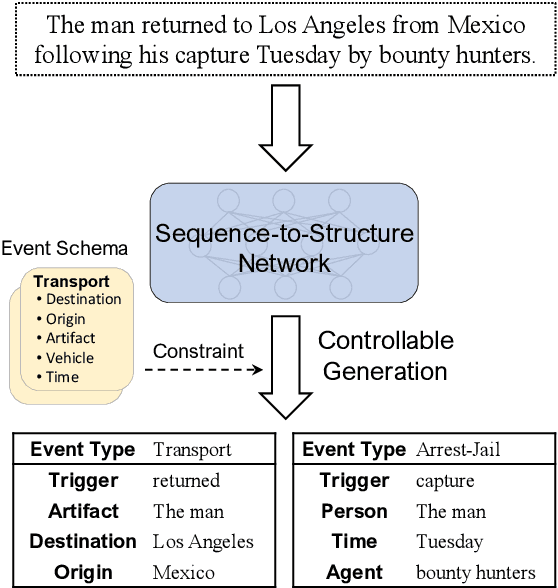
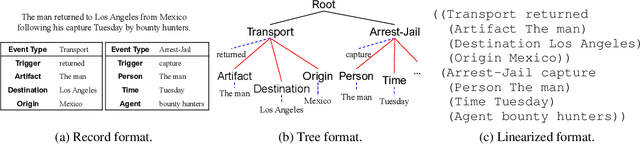

Event extraction is challenging due to the complex structure of event records and the semantic gap between text and event. Traditional methods usually extract event records by decomposing the complex structure prediction task into multiple subtasks. In this paper, we propose Text2Event, a sequence-to-structure generation paradigm that can directly extract events from the text in an end-to-end manner. Specifically, we design a sequence-to-structure network for unified event extraction, a constrained decoding algorithm for event knowledge injection during inference, and a curriculum learning algorithm for efficient model learning. Experimental results show that, by uniformly modeling all tasks in a single model and universally predicting different labels, our method can achieve competitive performance using only record-level annotations in both supervised learning and transfer learning settings.
Knowledgeable or Educated Guess? Revisiting Language Models as Knowledge Bases
Jun 17, 2021



Previous literatures show that pre-trained masked language models (MLMs) such as BERT can achieve competitive factual knowledge extraction performance on some datasets, indicating that MLMs can potentially be a reliable knowledge source. In this paper, we conduct a rigorous study to explore the underlying predicting mechanisms of MLMs over different extraction paradigms. By investigating the behaviors of MLMs, we find that previous decent performance mainly owes to the biased prompts which overfit dataset artifacts. Furthermore, incorporating illustrative cases and external contexts improve knowledge prediction mainly due to entity type guidance and golden answer leakage. Our findings shed light on the underlying predicting mechanisms of MLMs, and strongly question the previous conclusion that current MLMs can potentially serve as reliable factual knowledge bases.
From Discourse to Narrative: Knowledge Projection for Event Relation Extraction
Jun 16, 2021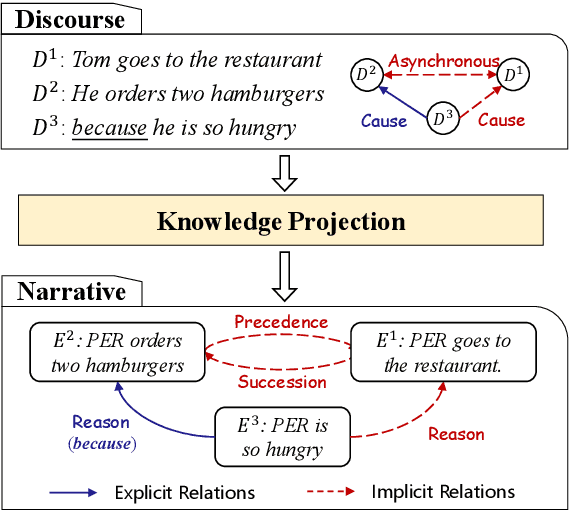
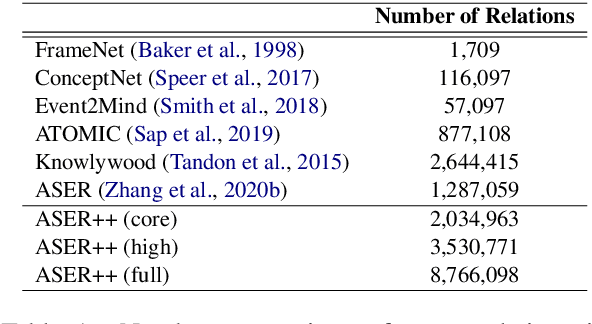

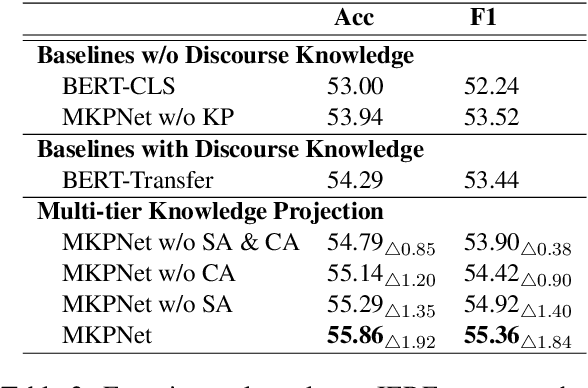
Current event-centric knowledge graphs highly rely on explicit connectives to mine relations between events. Unfortunately, due to the sparsity of connectives, these methods severely undermine the coverage of EventKGs. The lack of high-quality labelled corpora further exacerbates that problem. In this paper, we propose a knowledge projection paradigm for event relation extraction: projecting discourse knowledge to narratives by exploiting the commonalities between them. Specifically, we propose Multi-tier Knowledge Projection Network (MKPNet), which can leverage multi-tier discourse knowledge effectively for event relation extraction. In this way, the labelled data requirement is significantly reduced, and implicit event relations can be effectively extracted. Intrinsic experimental results show that MKPNet achieves the new state-of-the-art performance, and extrinsic experimental results verify the value of the extracted event relations.
* 11 pages