 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Direct Simultaneous Translation Activation for Large Audio-Language Models
Sep 19, 2025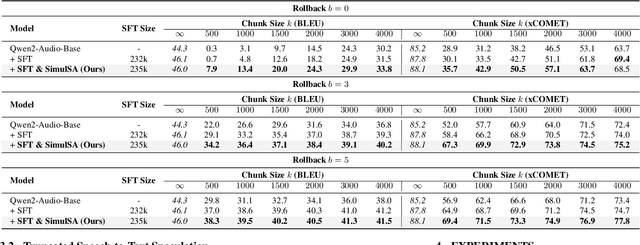
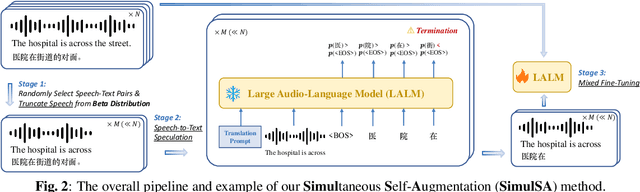

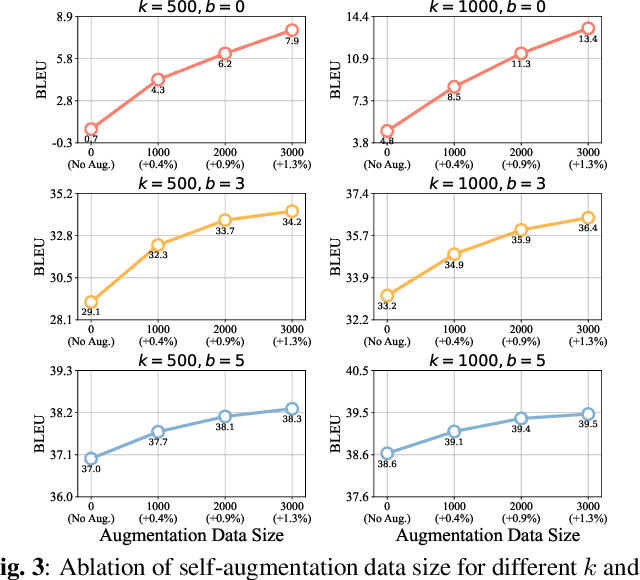
Simultaneous speech-to-text translation (Simul-S2TT) aims to translate speech into target text in real time, outputting translations while receiving source speech input, rather than waiting for the entire utterance to be spoken. Simul-S2TT research often modifies model architectures to implement read-write strategies. However, with the rise of large audio-language models (LALMs), a key challenge is how to directly activate Simul-S2TT capabilities in base models without additional architectural changes. In this paper, we introduce {\bf Simul}taneous {\bf S}elf-{\bf A}ugmentation ({\bf SimulSA}), a strategy that utilizes LALMs' inherent capabilities to obtain simultaneous data by randomly truncating speech and constructing partially aligned translation. By incorporating them into offline SFT data, SimulSA effectively bridges the distribution gap between offline translation during pretraining and simultaneous translation during inference. Experimental results demonstrate that augmenting only about {\bf 1\%} of the simultaneous data, compared to the full offline SFT data, can significantly activate LALMs' Simul-S2TT capabilities without modifications to model architecture or decoding strategy.
Tool Graph Retriever: Exploring Dependency Graph-based Tool Retrieval for Large Language Models
Aug 07, 2025With the remarkable advancement of AI agents, the number of their equipped tools is increasing rapidly. However, integrating all tool information into the limited model context becomes impractical, highlighting the need for efficient tool retrieval methods. In this regard, dominant methods primarily rely on semantic similarities between tool descriptions and user queries to retrieve relevant tools. However, they often consider each tool independently, overlooking dependencies between tools, which may lead to the omission of prerequisite tools for successful task execution. To deal with this defect, in this paper, we propose Tool Graph Retriever (TGR), which exploits the dependencies among tools to learn better tool representations for retrieval. First, we construct a dataset termed TDI300K to train a discriminator for identifying tool dependencies. Then, we represent all candidate tools as a tool dependency graph and use graph convolution to integrate the dependencies into their representations. Finally, these updated tool representations are employed for online retrieval. Experimental results on several commonly used datasets show that our TGR can bring a performance improvement to existing dominant methods, achieving SOTA performance. Moreover, in-depth analyses also verify the importance of tool dependencies and the effectiveness of our TGR.
Translationese-index: Using Likelihood Ratios for Graded and Generalizable Measurement of Translationese
Jul 16, 2025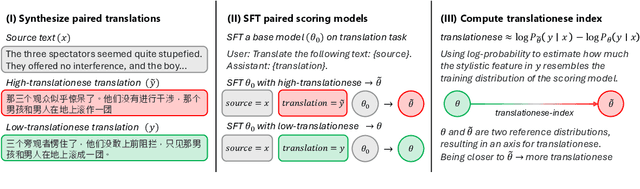
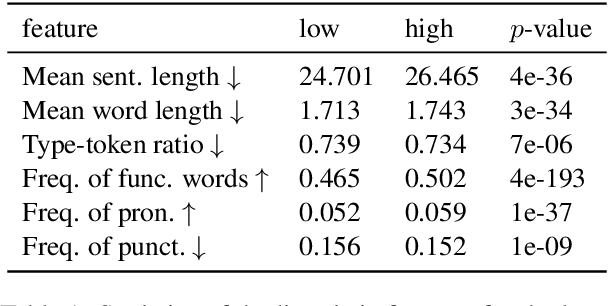
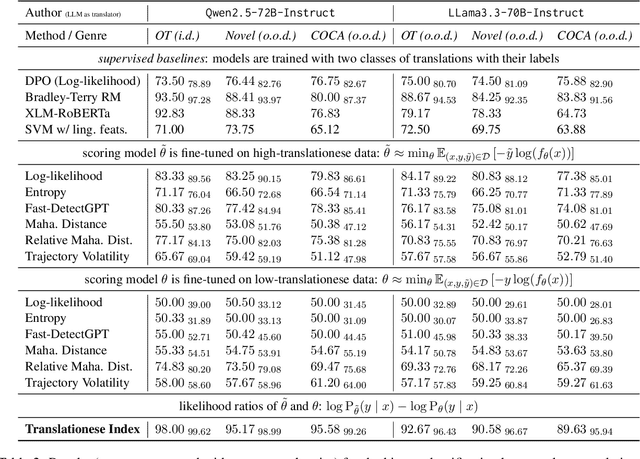
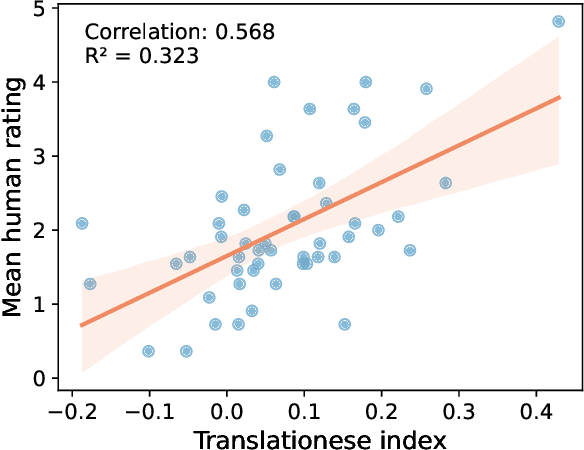
In this paper, we propose the first quantitative measure for translationese -- the translationese-index (T-index) for graded and generalizable measurement of translationese, computed from the likelihood ratios of two contrastively fine-tuned language models (LMs). We use a synthesized dataset and a dataset with translations in the wild to evaluate T-index's generalizability in cross-domain settings and its validity against human judgments. Our results show that T-index is both robust and efficient. T-index scored by two 0.5B LMs fine-tuned on only 1-5k pairs of synthetic data can well capture translationese in the wild. We find that the relative differences in T-indices between translations can well predict pairwise translationese annotations obtained from human annotators; and the absolute values of T-indices correlate well with human ratings of degrees of translationese (Pearson's $r = 0.568$). Additionally, the correlation between T-index and existing machine translation (MT) quality estimation (QE) metrics such as BLEU and COMET is low, suggesting that T-index is not covered by these metrics and can serve as a complementary metric in MT QE.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
PolyMath: Evaluating Mathematical Reasoning in Multilingual Contexts
Apr 30, 2025In this paper, we introduce PolyMath, a multilingual mathematical reasoning benchmark covering 18 languages and 4 easy-to-hard difficulty levels. Our benchmark ensures difficulty comprehensiveness, language diversity, and high-quality translation, making it a highly discriminative multilingual mathematical benchmark in the era of reasoning LLMs. We conduct a comprehensive evaluation for advanced LLMs and find that even Qwen-3-235B-A22B-Thinking and Gemini-2.5-pro, achieve only 54.6 and 52.2 benchmark scores, with about 40% accuracy under the highest level From a language perspective, our benchmark reveals several key challenges of LLMs in multilingual reasoning: (1) Reasoning performance varies widely across languages for current LLMs; (2) Input-output language consistency is low in reasoning LLMs and may be correlated with performance; (3) The thinking length differs significantly by language for current LLMs. Additionally, we demonstrate that controlling the output language in the instructions has the potential to affect reasoning performance, especially for some low-resource languages, suggesting a promising direction for improving multilingual capabilities in LLMs.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
ZhoBLiMP: a Systematic Assessment of Language Models with Linguistic Minimal Pairs in Chinese
Nov 09, 2024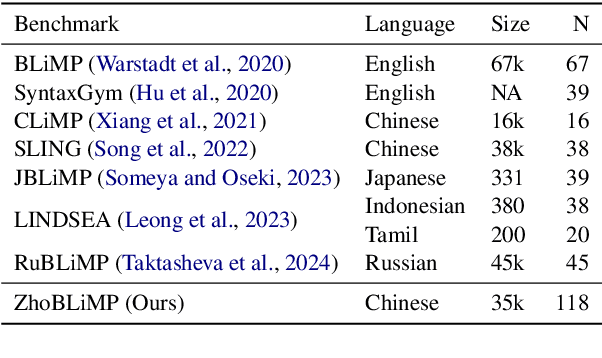

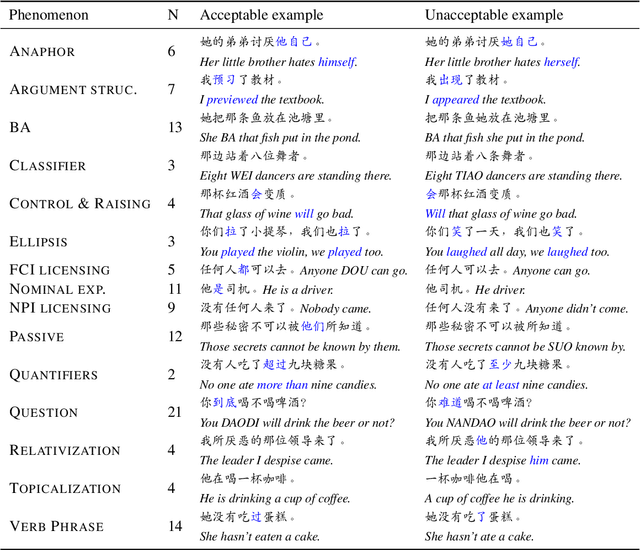
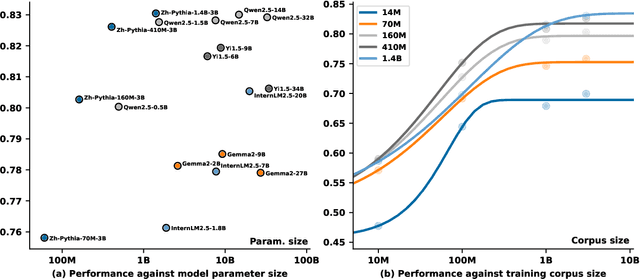
Whether and how language models (LMs) acquire the syntax of natural languages has been widely evaluated under the minimal pair paradigm. However, a lack of wide-coverage benchmarks in languages other than English has constrained systematic investigations into the issue. Addressing it, we first introduce ZhoBLiMP, the most comprehensive benchmark of linguistic minimal pairs for Chinese to date, with 118 paradigms, covering 15 linguistic phenomena. We then train 20 LMs of different sizes (14M to 1.4B) on Chinese corpora of various volumes (100M to 3B tokens) and evaluate them along with 14 off-the-shelf LLMs on ZhoBLiMP. The overall results indicate that Chinese grammar can be mostly learned by models with around 500M parameters, trained on 1B tokens with one epoch, showing limited benefits for further scaling. Most (N=95) linguistic paradigms are of easy or medium difficulty for LMs, while there are still 13 paradigms that remain challenging even for models with up to 32B parameters. In regard to how LMs acquire Chinese grammar, we observe a U-shaped learning pattern in several phenomena, similar to those observed in child language acquisition.
Not All Languages are Equal: Insights into Multilingual Retrieval-Augmented Generation
Oct 29, 2024



RALMs (Retrieval-Augmented Language Models) broaden their knowledge scope by incorporating external textual resources. However, the multilingual nature of global knowledge necessitates RALMs to handle diverse languages, a topic that has received limited research focus. In this work, we propose \textit{Futurepedia}, a carefully crafted benchmark containing parallel texts across eight representative languages. We evaluate six multilingual RALMs using our benchmark to explore the challenges of multilingual RALMs. Experimental results reveal linguistic inequalities: 1) high-resource languages stand out in Monolingual Knowledge Extraction; 2) Indo-European languages lead RALMs to provide answers directly from documents, alleviating the challenge of expressing answers across languages; 3) English benefits from RALMs' selection bias and speaks louder in multilingual knowledge selection. Based on these findings, we offer advice for improving multilingual Retrieval Augmented Generation. For monolingual knowledge extraction, careful attention must be paid to cascading errors from translating low-resource languages into high-resource ones. In cross-lingual knowledge transfer, encouraging RALMs to provide answers within documents in different languages can improve transfer performance. For multilingual knowledge selection, incorporating more non-English documents and repositioning English documents can help mitigate RALMs' selection bias. Through comprehensive experiments, we underscore the complexities inherent in multilingual RALMs and offer valuable insights for future research.
mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval
Jul 29, 2024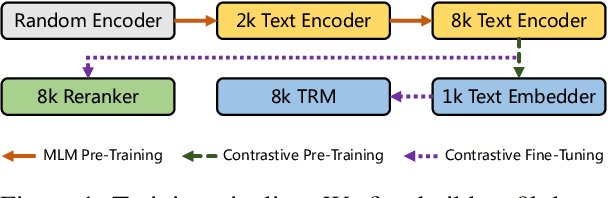

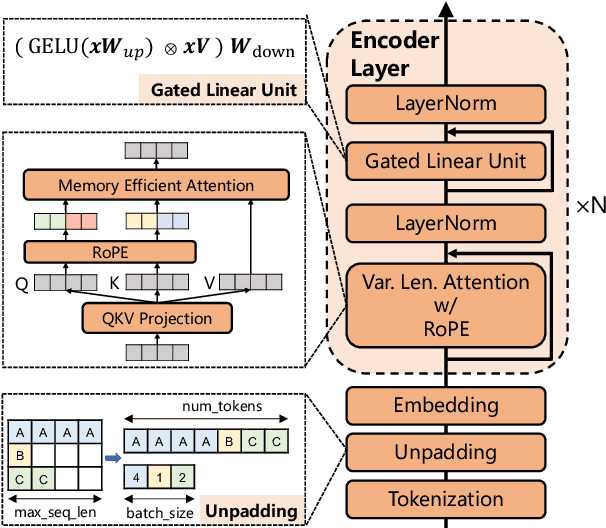
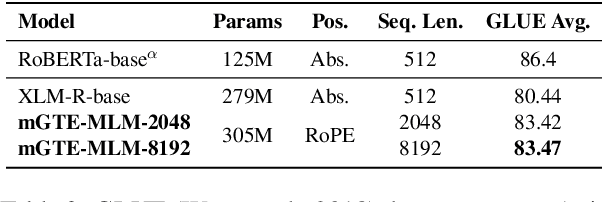
We present systematic efforts in building long-context multilingual text representation model (TRM) and reranker from scratch for text retrieval. We first introduce a text encoder (base size) enhanced with RoPE and unpadding, pre-trained in a native 8192-token context (longer than 512 of previous multilingual encoders). Then we construct a hybrid TRM and a cross-encoder reranker by contrastive learning. Evaluations show that our text encoder outperforms the same-sized previous state-of-the-art XLM-R. Meanwhile, our TRM and reranker match the performance of large-sized state-of-the-art BGE-M3 models and achieve better results on long-context retrieval benchmarks. Further analysis demonstrate that our proposed models exhibit higher efficiency during both training and inference. We believe their efficiency and effectiveness could benefit various researches and industrial applications.