 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
Apr 08, 2026Building world models with spatial consistency and real-time interactivity remains a fundamental challenge in computer vision. Current video generation paradigms often struggle with a lack of spatial persistence and insufficient visual realism, making it difficult to support seamless navigation in complex environments. To address these challenges, we propose INSPATIO-WORLD, a novel real-time framework capable of recovering and generating high-fidelity, dynamic interactive scenes from a single reference video. At the core of our approach is a Spatiotemporal Autoregressive (STAR) architecture, which enables consistent and controllable scene evolution through two tightly coupled components: Implicit Spatiotemporal Cache aggregates reference and historical observations into a latent world representation, ensuring global consistency during long-horizon navigation; Explicit Spatial Constraint Module enforces geometric structure and translates user interactions into precise and physically plausible camera trajectories. Furthermore, we introduce Joint Distribution Matching Distillation (JDMD). By using real-world data distributions as a regularizing guide, JDMD effectively overcomes the fidelity degradation typically caused by over-reliance on synthetic data. Extensive experiments demonstrate that INSPATIO-WORLD significantly outperforms existing state-of-the-art (SOTA) models in spatial consistency and interaction precision, ranking first among real-time interactive methods on the WorldScore-Dynamic benchmark, and establishing a practical pipeline for navigating 4D environments reconstructed from monocular videos.
InSpatio-WorldFM: An Open-Source Real-Time Generative Frame Model
Mar 12, 2026We present InSpatio-WorldFM, an open-source real-time frame model for spatial intelligence. Unlike video-based world models that rely on sequential frame generation and incur substantial latency due to window-level processing, InSpatio-WorldFM adopts a frame-based paradigm that generates each frame independently, enabling low-latency real-time spatial inference. By enforcing multi-view spatial consistency through explicit 3D anchors and implicit spatial memory, the model preserves global scene geometry while maintaining fine-grained visual details across viewpoint changes. We further introduce a progressive three-stage training pipeline that transforms a pretrained image diffusion model into a controllable frame model and finally into a real-time generator through few-step distillation. Experimental results show that InSpatio-WorldFM achieves strong multi-view consistency while supporting interactive exploration on consumer-grade GPUs, providing an efficient alternative to traditional video-based world models for real-time world simulation.
XR-VIO: High-precision Visual Inertial Odometry with Fast Initialization for XR Applications
Feb 03, 2025This paper presents a novel approach to Visual Inertial Odometry (VIO), focusing on the initialization and feature matching modules. Existing methods for initialization often suffer from either poor stability in visual Structure from Motion (SfM) or fragility in solving a huge number of parameters simultaneously. To address these challenges, we propose a new pipeline for visual inertial initialization that robustly handles various complex scenarios. By tightly coupling gyroscope measurements, we enhance the robustness and accuracy of visual SfM. Our method demonstrates stable performance even with only four image frames, yielding competitive results. In terms of feature matching, we introduce a hybrid method that combines optical flow and descriptor-based matching. By leveraging the robustness of continuous optical flow tracking and the accuracy of descriptor matching, our approach achieves efficient, accurate, and robust tracking results. Through evaluation on multiple benchmarks, our method demonstrates state-of-the-art performance in terms of accuracy and success rate. Additionally, a video demonstration on mobile devices showcases the practical applicability of our approach in the field of Augmented Reality/Virtual Reality (AR/VR).
StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation
Jan 10, 2025
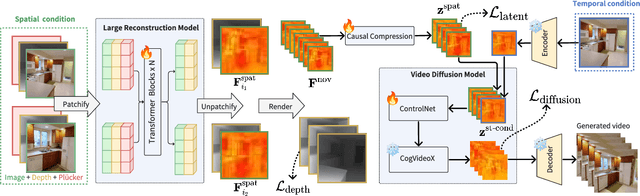


Recent advances in large reconstruction and generative models have significantly improved scene reconstruction and novel view generation. However, due to compute limitations, each inference with these large models is confined to a small area, making long-range consistent scene generation challenging. To address this, we propose StarGen, a novel framework that employs a pre-trained video diffusion model in an autoregressive manner for long-range scene generation. The generation of each video clip is conditioned on the 3D warping of spatially adjacent images and the temporally overlapping image from previously generated clips, improving spatiotemporal consistency in long-range scene generation with precise pose control. The spatiotemporal condition is compatible with various input conditions, facilitating diverse tasks, including sparse view interpolation, perpetual view generation, and layout-conditioned city generation. Quantitative and qualitative evaluations demonstrate StarGen's superior scalability, fidelity, and pose accuracy compared to state-of-the-art methods.
WeKnow-RAG: An Adaptive Approach for Retrieval-Augmented Generation Integrating Web Search and Knowledge Graphs
Aug 14, 2024



Large Language Models (LLMs) have greatly contributed to the development of adaptive intelligent agents and are positioned as an important way to achieve Artificial General Intelligence (AGI). However, LLMs are prone to produce factually incorrect information and often produce "phantom" content that undermines their reliability, which poses a serious challenge for their deployment in real-world scenarios. Enhancing LLMs by combining external databases and information retrieval mechanisms is an effective path. To address the above challenges, we propose a new approach called WeKnow-RAG, which integrates Web search and Knowledge Graphs into a "Retrieval-Augmented Generation (RAG)" system. First, the accuracy and reliability of LLM responses are improved by combining the structured representation of Knowledge Graphs with the flexibility of dense vector retrieval. WeKnow-RAG then utilizes domain-specific knowledge graphs to satisfy a variety of queries and domains, thereby improving performance on factual information and complex reasoning tasks by employing multi-stage web page retrieval techniques using both sparse and dense retrieval methods. Our approach effectively balances the efficiency and accuracy of information retrieval, thus improving the overall retrieval process. Finally, we also integrate a self-assessment mechanism for the LLM to evaluate the trustworthiness of the answers it generates. Our approach proves its outstanding effectiveness in a wide range of offline experiments and online submissions.
PGSR: Planar-based Gaussian Splatting for Efficient and High-Fidelity Surface Reconstruction
Jun 10, 2024



Recently, 3D Gaussian Splatting (3DGS) has attracted widespread attention due to its high-quality rendering, and ultra-fast training and rendering speed. However, due to the unstructured and irregular nature of Gaussian point clouds, it is difficult to guarantee geometric reconstruction accuracy and multi-view consistency simply by relying on image reconstruction loss. Although many studies on surface reconstruction based on 3DGS have emerged recently, the quality of their meshes is generally unsatisfactory. To address this problem, we propose a fast planar-based Gaussian splatting reconstruction representation (PGSR) to achieve high-fidelity surface reconstruction while ensuring high-quality rendering. Specifically, we first introduce an unbiased depth rendering method, which directly renders the distance from the camera origin to the Gaussian plane and the corresponding normal map based on the Gaussian distribution of the point cloud, and divides the two to obtain the unbiased depth. We then introduce single-view geometric, multi-view photometric, and geometric regularization to preserve global geometric accuracy. We also propose a camera exposure compensation model to cope with scenes with large illumination variations. Experiments on indoor and outdoor scenes show that our method achieves fast training and rendering while maintaining high-fidelity rendering and geometric reconstruction, outperforming 3DGS-based and NeRF-based methods.
Depth Completion with Multiple Balanced Bases and Confidence for Dense Monocular SLAM
Sep 20, 2023Dense SLAM based on monocular cameras does indeed have immense application value in the field of AR/VR, especially when it is performed on a mobile device. In this paper, we propose a novel method that integrates a light-weight depth completion network into a sparse SLAM system using a multi-basis depth representation, so that dense mapping can be performed online even on a mobile phone. Specifically, we present a specifically optimized multi-basis depth completion network, called BBC-Net, tailored to the characteristics of traditional sparse SLAM systems. BBC-Net can predict multiple balanced bases and a confidence map from a monocular image with sparse points generated by off-the-shelf keypoint-based SLAM systems. The final depth is a linear combination of predicted depth bases that can be optimized by tuning the corresponding weights. To seamlessly incorporate the weights into traditional SLAM optimization and ensure efficiency and robustness, we design a set of depth weight factors, which makes our network a versatile plug-in module, facilitating easy integration into various existing sparse SLAM systems and significantly enhancing global depth consistency through bundle adjustment. To verify the portability of our method, we integrate BBC-Net into two representative SLAM systems. The experimental results on various datasets show that the proposed method achieves better performance in monocular dense mapping than the state-of-the-art methods. We provide an online demo running on a mobile phone, which verifies the efficiency and mapping quality of the proposed method in real-world scenarios.
VIP-SLAM: An Efficient Tightly-Coupled RGB-D Visual Inertial Planar SLAM
Jul 04, 2022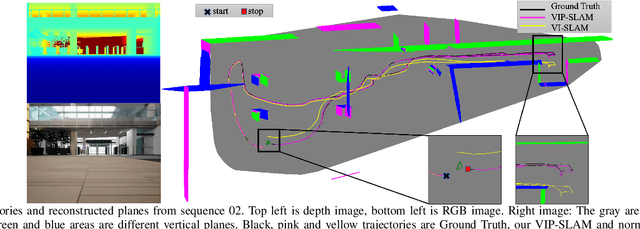
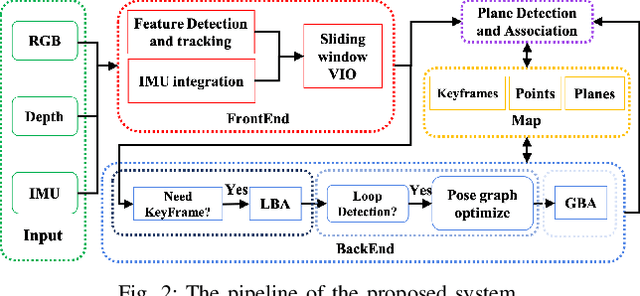
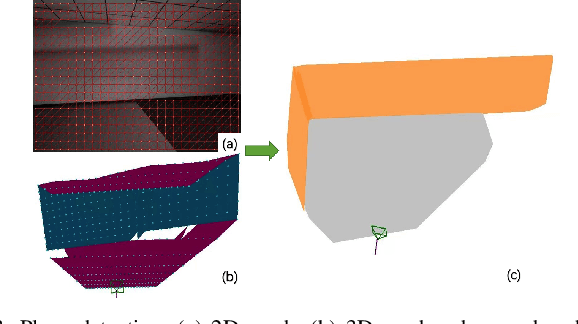
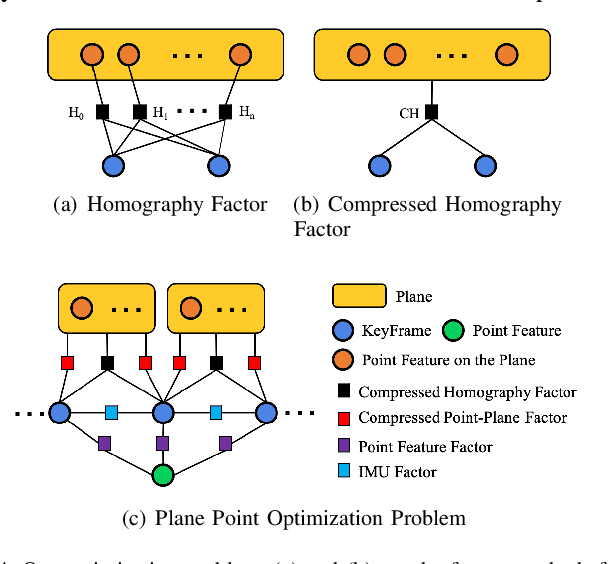
In this paper, we propose a tightly-coupled SLAM system fused with RGB, Depth, IMU and structured plane information. Traditional sparse points based SLAM systems always maintain a mass of map points to model the environment. Huge number of map points bring us a high computational complexity, making it difficult to be deployed on mobile devices. On the other hand, planes are common structures in man-made environment especially in indoor environments. We usually can use a small number of planes to represent a large scene. So the main purpose of this article is to decrease the high complexity of sparse points based SLAM. We build a lightweight back-end map which consists of a few planes and map points to achieve efficient bundle adjustment (BA) with an equal or better accuracy. We use homography constraints to eliminate the parameters of numerous plane points in the optimization and reduce the complexity of BA. We separate the parameters and measurements in homography and point-to-plane constraints and compress the measurements part to further effectively improve the speed of BA. We also integrate the plane information into the whole system to realize robust planar feature extraction, data association, and global consistent planar reconstruction. Finally, we perform an ablation study and compare our method with similar methods in simulation and real environment data. Our system achieves obvious advantages in accuracy and efficiency. Even if the plane parameters are involved in the optimization, we effectively simplify the back-end map by using planar structures. The global bundle adjustment is nearly 2 times faster than the sparse points based SLAM algorithm.
Procedural Text Understanding via Scene-Wise Evolution
Mar 15, 2022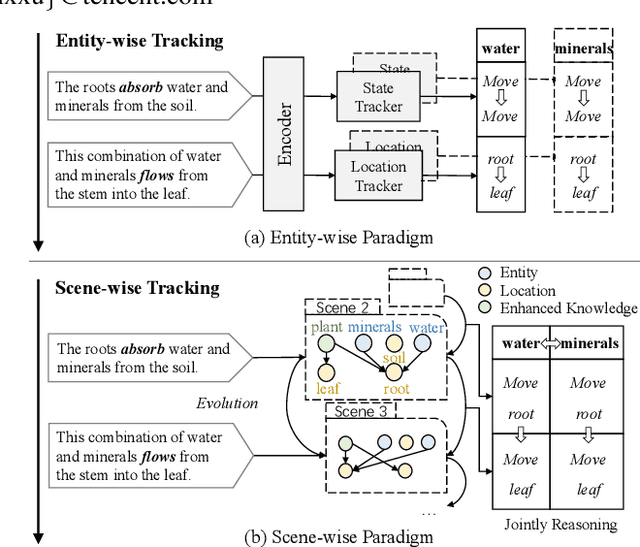

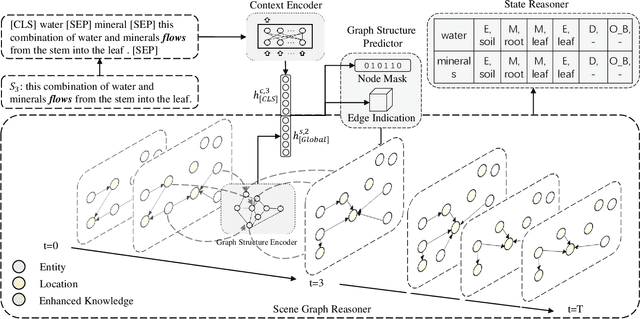
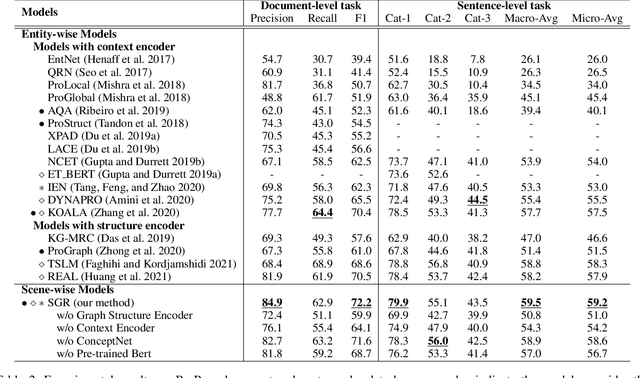
Procedural text understanding requires machines to reason about entity states within the dynamical narratives. Current procedural text understanding approaches are commonly \textbf{entity-wise}, which separately track each entity and independently predict different states of each entity. Such an entity-wise paradigm does not consider the interaction between entities and their states. In this paper, we propose a new \textbf{scene-wise} paradigm for procedural text understanding, which jointly tracks states of all entities in a scene-by-scene manner. Based on this paradigm, we propose \textbf{S}cene \textbf{G}raph \textbf{R}easoner (\textbf{SGR}), which introduces a series of dynamically evolving scene graphs to jointly formulate the evolution of entities, states and their associations throughout the narrative. In this way, the deep interactions between all entities and states can be jointly captured and simultaneously derived from scene graphs. Experiments show that SGR not only achieves the new state-of-the-art performance but also significantly accelerates the speed of reasoning.
* 9 pages, 2 figures
From Discourse to Narrative: Knowledge Projection for Event Relation Extraction
Jun 16, 2021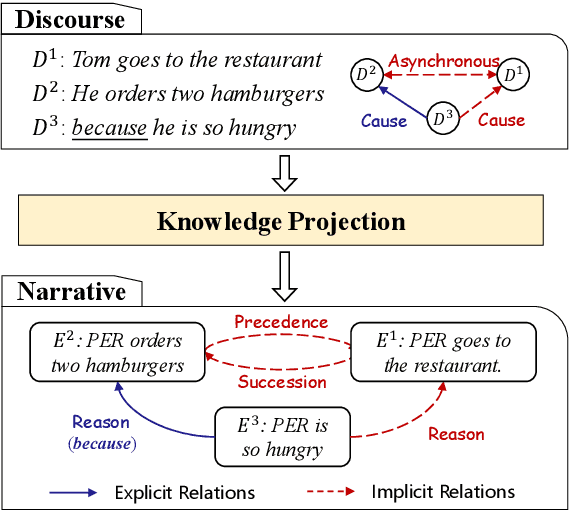
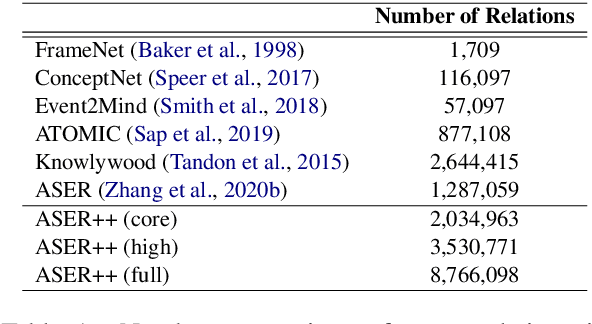

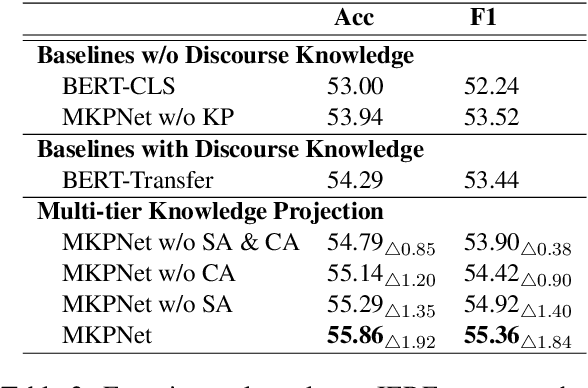
Current event-centric knowledge graphs highly rely on explicit connectives to mine relations between events. Unfortunately, due to the sparsity of connectives, these methods severely undermine the coverage of EventKGs. The lack of high-quality labelled corpora further exacerbates that problem. In this paper, we propose a knowledge projection paradigm for event relation extraction: projecting discourse knowledge to narratives by exploiting the commonalities between them. Specifically, we propose Multi-tier Knowledge Projection Network (MKPNet), which can leverage multi-tier discourse knowledge effectively for event relation extraction. In this way, the labelled data requirement is significantly reduced, and implicit event relations can be effectively extracted. Intrinsic experimental results show that MKPNet achieves the new state-of-the-art performance, and extrinsic experimental results verify the value of the extracted event relations.
* 11 pages