 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecureGBM: Secure Multi-Party Gradient Boosting
Nov 27, 2019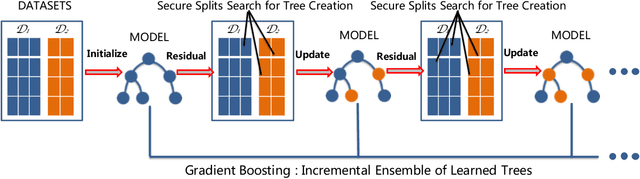

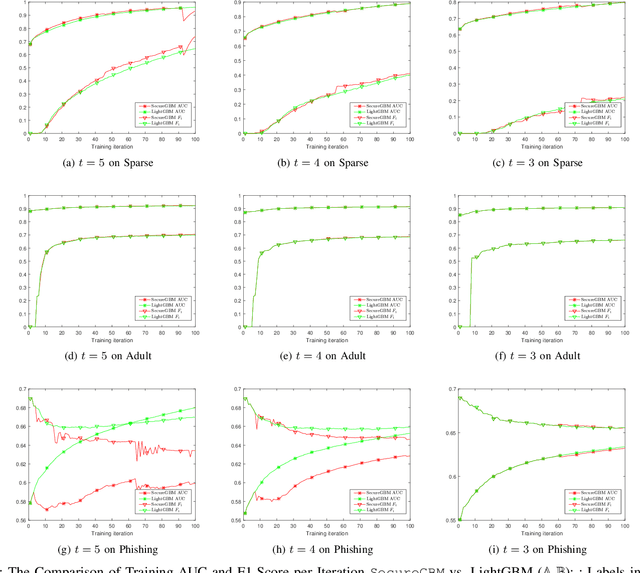
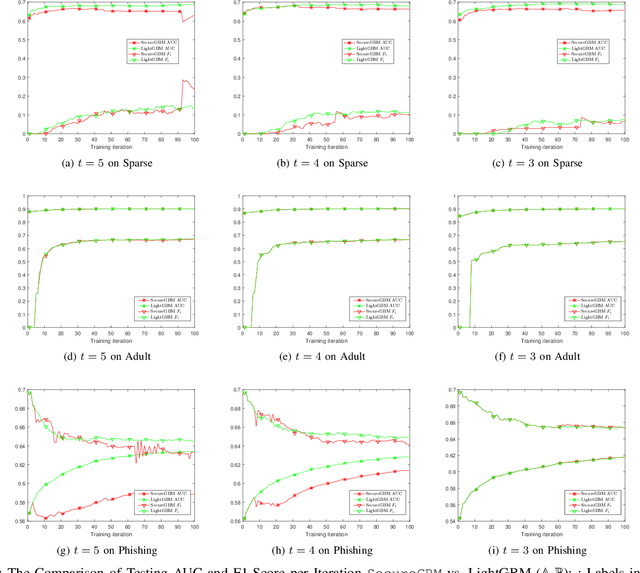
Federated machine learning systems have been widely used to facilitate the joint data analytics across the distributed datasets owned by the different parties that do not trust each others. In this paper, we proposed a novel Gradient Boosting Machines (GBM) framework SecureGBM built-up with a multi-party computation model based on semi-homomorphic encryption, where every involved party can jointly obtain a shared Gradient Boosting machines model while protecting their own data from the potential privacy leakage and inferential identification. More specific, our work focused on a specific "dual--party" secure learning scenario based on two parties -- both party own an unique view (i.e., attributes or features) to the sample group of samples while only one party owns the labels. In such scenario, feature and label data are not allowed to share with others. To achieve the above goal, we firstly extent -- LightGBM -- a well known implementation of tree-based GBM through covering its key operations for training and inference with SEAL homomorphic encryption schemes. However, the performance of such re-implementation is significantly bottle-necked by the explosive inflation of the communication payloads, based on ciphertexts subject to the increasing length of plaintexts. In this way, we then proposed to use stochastic approximation techniques to reduced the communication payloads while accelerating the overall training procedure in a statistical manner. Our experiments using the real-world data showed that SecureGBM can well secure the communication and computation of LightGBM training and inference procedures for the both parties while only losing less than 3% AUC, using the same number of iterations for gradient boosting, on a wide range of benchmark datasets.
Parallel Distributed Logistic Regression for Vertical Federated Learning without Third-Party Coordinator
Nov 22, 2019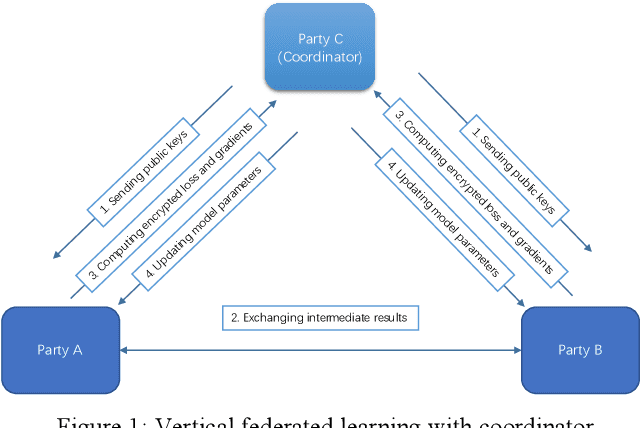
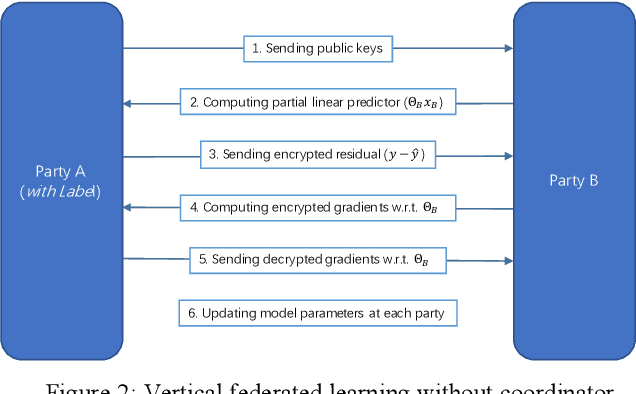


Federated Learning is a new distributed learning mechanism which allows model training on a large corpus of decentralized data owned by different data providers, without sharing or leakage of raw data. According to the characteristics of data dis-tribution, it could be usually classified into three categories: horizontal federated learning, vertical federated learning, and federated transfer learning. In this paper we present a solution for parallel dis-tributed logistic regression for vertical federated learning. As compared with existing works, the role of third-party coordinator is removed in our proposed solution. The system is built on the pa-rameter server architecture and aims to speed up the model training via utilizing a cluster of servers in case of large volume of training data. We also evaluate the performance of the parallel distributed model training and the experimental results show the great scalability of the system.
Multi-task Sentence Encoding Model for Semantic Retrieval in Question Answering Systems
Nov 18, 2019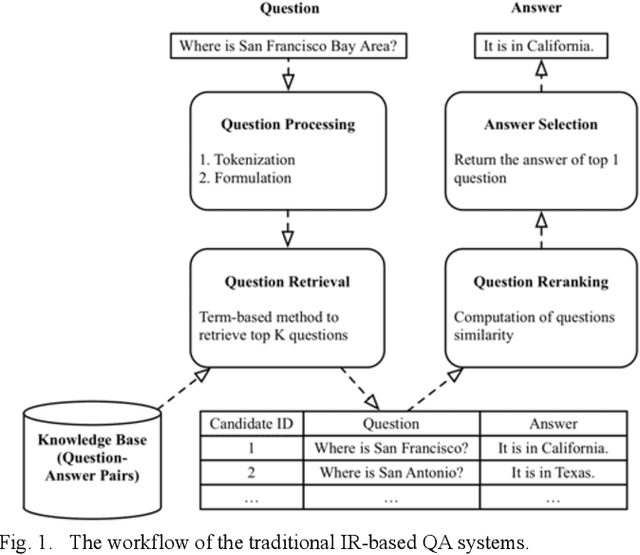
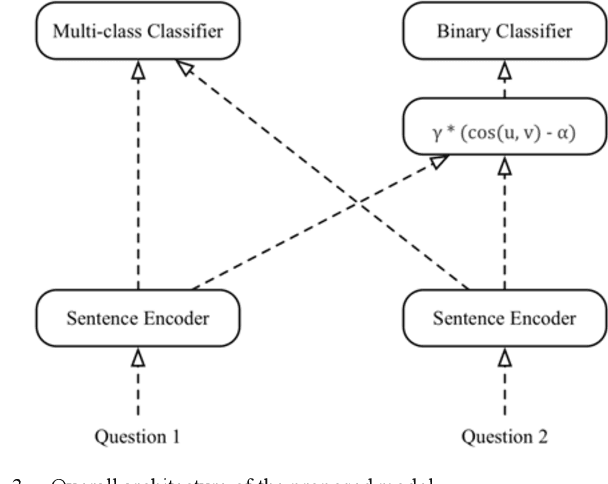
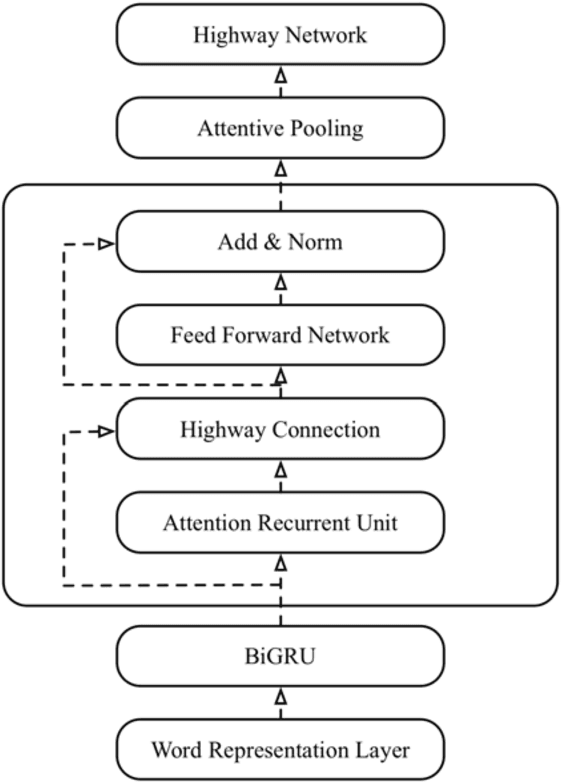
Question Answering (QA) systems are used to provide proper responses to users' questions automatically. Sentence matching is an essential task in the QA systems and is usually reformulated as a Paraphrase Identification (PI) problem. Given a question, the aim of the task is to find the most similar question from a QA knowledge base. In this paper, we propose a Multi-task Sentence Encoding Model (MSEM) for the PI problem, wherein a connected graph is employed to depict the relation between sentences, and a multi-task learning model is applied to address both the sentence matching and sentence intent classification problem. In addition, we implement a general semantic retrieval framework that combines our proposed model and the Approximate Nearest Neighbor (ANN) technology, which enables us to find the most similar question from all available candidates very quickly during online serving. The experiments show the superiority of our proposed method as compared with the existing sentence matching models.
Deep Sequence Learning with Auxiliary Information for Traffic Prediction
Jun 13, 2018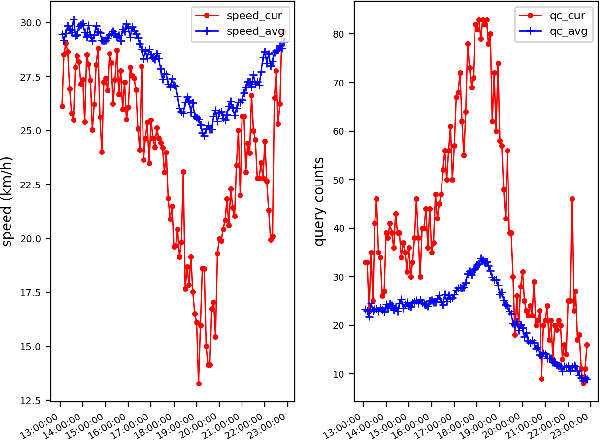

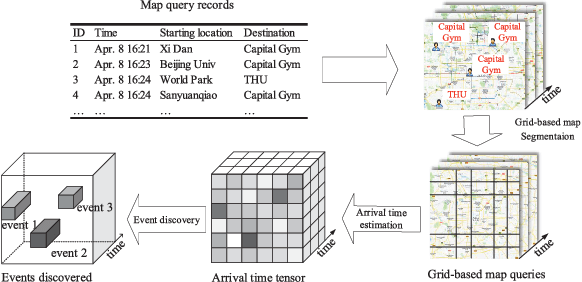
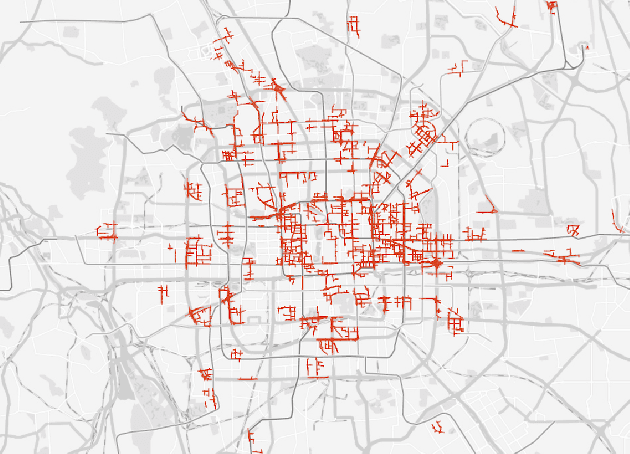
Predicting traffic conditions from online route queries is a challenging task as there are many complicated interactions over the roads and crowds involved. In this paper, we intend to improve traffic prediction by appropriate integration of three kinds of implicit but essential factors encoded in auxiliary information. We do this within an encoder-decoder sequence learning framework that integrates the following data: 1) offline geographical and social attributes. For example, the geographical structure of roads or public social events such as national celebrations; 2) road intersection information. In general, traffic congestion occurs at major junctions; 3) online crowd queries. For example, when many online queries issued for the same destination due to a public performance, the traffic around the destination will potentially become heavier at this location after a while. Qualitative and quantitative experiments on a real-world dataset from Baidu have demonstrated the effectiveness of our framework.