 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEGAM: Extended Graph Attention Model for Solving Routing Problems
Jan 29, 2026Neural combinatorial optimization (NCO) solvers, implemented with graph neural networks (GNNs), have introduced new approaches for solving routing problems. Trained with reinforcement learning (RL), the state-of-the-art graph attention model (GAM) achieves near-optimal solutions without requiring expert knowledge or labeled data. In this work, we generalize the existing graph attention mechanism and propose the extended graph attention model (EGAM). Our model utilizes multi-head dot-product attention to update both node and edge embeddings, addressing the limitations of the conventional GAM, which considers only node features. We employ an autoregressive encoder-decoder architecture and train it with policy gradient algorithms that incorporate a specially designed baseline. Experiments show that EGAM matches or outperforms existing methods across various routing problems. Notably, the proposed model demonstrates exceptional performance on highly constrained problems, highlighting its efficiency in handling complex graph structures.
Multimodal Pre-training Based on Graph Attention Network for Document Understanding
Mar 25, 2022
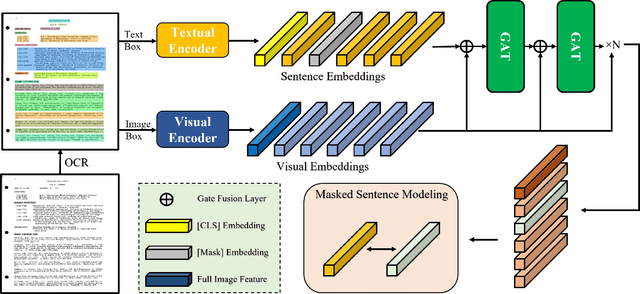
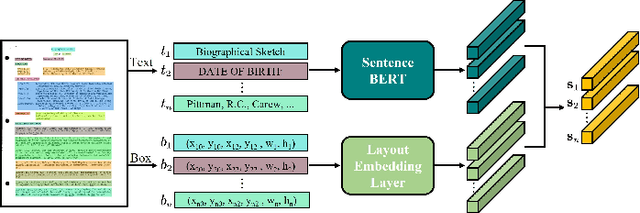
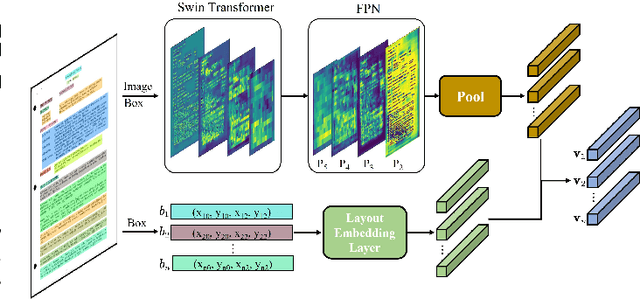
Document intelligence as a relatively new research topic supports many business applications. Its main task is to automatically read, understand, and analyze documents. However, due to the diversity of formats (invoices, reports, forms, etc.) and layouts in documents, it is difficult to make machines understand documents. In this paper, we present the GraphDoc, a multimodal graph attention-based model for various document understanding tasks. GraphDoc is pre-trained in a multimodal framework by utilizing text, layout, and image information simultaneously. In a document, a text block relies heavily on its surrounding contexts, so we inject the graph structure into the attention mechanism to form a graph attention layer so that each input node can only attend to its neighborhoods. The input nodes of each graph attention layer are composed of textual, visual, and positional features from semantically meaningful regions in a document image. We do the multimodal feature fusion of each node by the gate fusion layer. The contextualization between each node is modeled by the graph attention layer. GraphDoc learns a generic representation from only 320k unlabeled documents via the Masked Sentence Modeling task. Extensive experimental results on the publicly available datasets show that GraphDoc achieves state-of-the-art performance, which demonstrates the effectiveness of our proposed method.
SecureGBM: Secure Multi-Party Gradient Boosting
Nov 27, 2019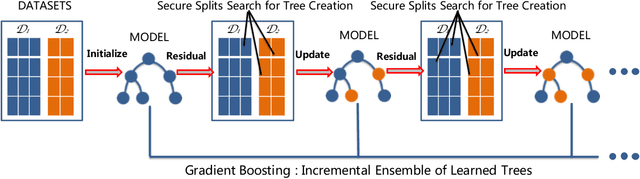

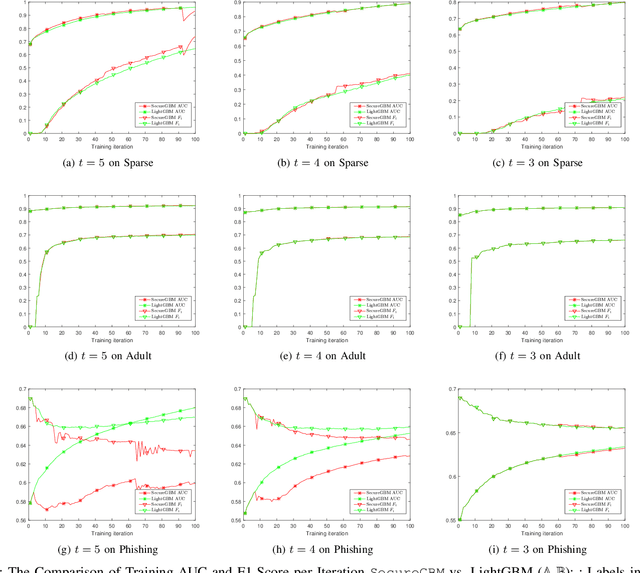
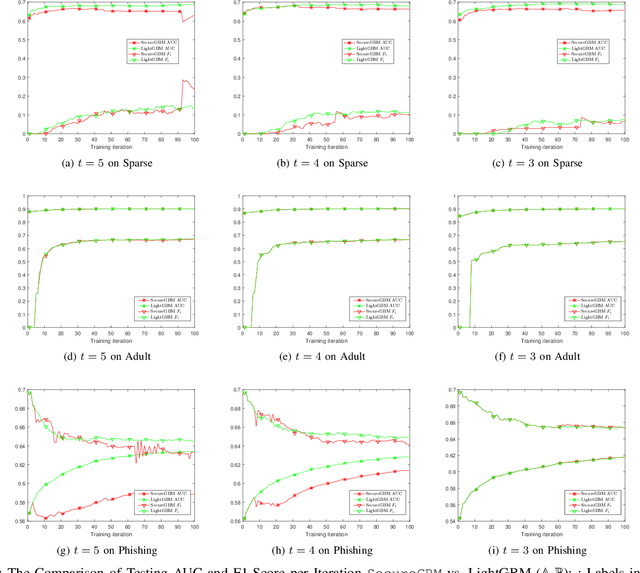
Federated machine learning systems have been widely used to facilitate the joint data analytics across the distributed datasets owned by the different parties that do not trust each others. In this paper, we proposed a novel Gradient Boosting Machines (GBM) framework SecureGBM built-up with a multi-party computation model based on semi-homomorphic encryption, where every involved party can jointly obtain a shared Gradient Boosting machines model while protecting their own data from the potential privacy leakage and inferential identification. More specific, our work focused on a specific "dual--party" secure learning scenario based on two parties -- both party own an unique view (i.e., attributes or features) to the sample group of samples while only one party owns the labels. In such scenario, feature and label data are not allowed to share with others. To achieve the above goal, we firstly extent -- LightGBM -- a well known implementation of tree-based GBM through covering its key operations for training and inference with SEAL homomorphic encryption schemes. However, the performance of such re-implementation is significantly bottle-necked by the explosive inflation of the communication payloads, based on ciphertexts subject to the increasing length of plaintexts. In this way, we then proposed to use stochastic approximation techniques to reduced the communication payloads while accelerating the overall training procedure in a statistical manner. Our experiments using the real-world data showed that SecureGBM can well secure the communication and computation of LightGBM training and inference procedures for the both parties while only losing less than 3% AUC, using the same number of iterations for gradient boosting, on a wide range of benchmark datasets.