 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROGRESSLM: Towards Progress Reasoning in Vision-Language Models
Jan 21, 2026Estimating task progress requires reasoning over long-horizon dynamics rather than recognizing static visual content. While modern Vision-Language Models (VLMs) excel at describing what is visible, it remains unclear whether they can infer how far a task has progressed from partial observations. To this end, we introduce Progress-Bench, a benchmark for systematically evaluating progress reasoning in VLMs. Beyond benchmarking, we further explore a human-inspired two-stage progress reasoning paradigm through both training-free prompting and training-based approach based on curated dataset ProgressLM-45K. Experiments on 14 VLMs show that most models are not yet ready for task progress estimation, exhibiting sensitivity to demonstration modality and viewpoint changes, as well as poor handling of unanswerable cases. While training-free prompting that enforces structured progress reasoning yields limited and model-dependent gains, the training-based ProgressLM-3B achieves consistent improvements even at a small model scale, despite being trained on a task set fully disjoint from the evaluation tasks. Further analyses reveal characteristic error patterns and clarify when and why progress reasoning succeeds or fails.
Step Potential Advantage Estimation: Harnessing Intermediate Confidence and Correctness for Efficient Mathematical Reasoning
Jan 07, 2026Reinforcement Learning with Verifiable Rewards (RLVR) elicits long chain-of-thought reasoning in large language models (LLMs), but outcome-based rewards lead to coarse-grained advantage estimation. While existing approaches improve RLVR via token-level entropy or sequence-level length control, they lack a semantically grounded, step-level measure of reasoning progress. As a result, LLMs fail to distinguish necessary deduction from redundant verification: they may continue checking after reaching a correct solution and, in extreme cases, overturn a correct trajectory into an incorrect final answer. To remedy the lack of process supervision, we introduce a training-free probing mechanism that extracts intermediate confidence and correctness and combines them into a Step Potential signal that explicitly estimates the reasoning state at each step. Building on this signal, we propose Step Potential Advantage Estimation (SPAE), a fine-grained credit assignment method that amplifies potential gains, penalizes potential drops, and applies penalty after potential saturates to encourage timely termination. Experiments across multiple benchmarks show SPAE consistently improves accuracy while substantially reducing response length, outperforming strong RL baselines and recent efficient reasoning and token-level advantage estimation methods. The code is available at https://github.com/cii030/SPAE-RL.
Explore to Evolve: Scaling Evolved Aggregation Logic via Proactive Online Exploration for Deep Research Agents
Oct 16, 2025Deep research web agents not only retrieve information from diverse sources such as web environments, files, and multimodal inputs, but more importantly, they need to rigorously analyze and aggregate knowledge for insightful research. However, existing open-source deep research agents predominantly focus on enhancing information-seeking capabilities of web agents to locate specific information, while overlooking the essential need for information aggregation, which would limit their ability to support in-depth research. We propose an Explore to Evolve paradigm to scalably construct verifiable training data for web agents. Begins with proactive online exploration, an agent sources grounded information by exploring the real web. Using the collected evidence, the agent then self-evolves an aggregation program by selecting, composing, and refining operations from 12 high-level logical types to synthesize a verifiable QA pair. This evolution from high-level guidance to concrete operations allowed us to scalably produce WebAggregatorQA, a dataset of 10K samples across 50K websites and 11 domains. Based on an open-source agent framework, SmolAgents, we collect supervised fine-tuning trajectories to develop a series of foundation models, WebAggregator. WebAggregator-8B matches the performance of GPT-4.1, while the 32B variant surpasses GPT-4.1 by more than 10% on GAIA-text and closely approaches Claude-3.7-sonnet. Moreover, given the limited availability of benchmarks that evaluate web agents' information aggregation abilities, we construct a human-annotated evaluation split of WebAggregatorQA as a challenging test set. On this benchmark, Claude-3.7-sonnet only achieves 28%, and GPT-4.1 scores 25.8%. Even when agents manage to retrieve all references, they still struggle on WebAggregatorQA, highlighting the need to strengthen the information aggregation capabilities of web agent foundations.
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025



LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
Evo-MARL: Co-Evolutionary Multi-Agent Reinforcement Learning for Internalized Safety
Aug 05, 2025


Multi-agent systems (MAS) built on multimodal large language models exhibit strong collaboration and performance. However, their growing openness and interaction complexity pose serious risks, notably jailbreak and adversarial attacks. Existing defenses typically rely on external guard modules, such as dedicated safety agents, to handle unsafe behaviors. Unfortunately, this paradigm faces two challenges: (1) standalone agents offer limited protection, and (2) their independence leads to single-point failure-if compromised, system-wide safety collapses. Naively increasing the number of guard agents further raises cost and complexity. To address these challenges, we propose Evo-MARL, a novel multi-agent reinforcement learning (MARL) framework that enables all task agents to jointly acquire defensive capabilities. Rather than relying on external safety modules, Evo-MARL trains each agent to simultaneously perform its primary function and resist adversarial threats, ensuring robustness without increasing system overhead or single-node failure. Furthermore, Evo-MARL integrates evolutionary search with parameter-sharing reinforcement learning to co-evolve attackers and defenders. This adversarial training paradigm internalizes safety mechanisms and continually enhances MAS performance under co-evolving threats. Experiments show that Evo-MARL reduces attack success rates by up to 22% while boosting accuracy by up to 5% on reasoning tasks-demonstrating that safety and utility can be jointly improved.
Spatial Mental Modeling from Limited Views
Jun 26, 2025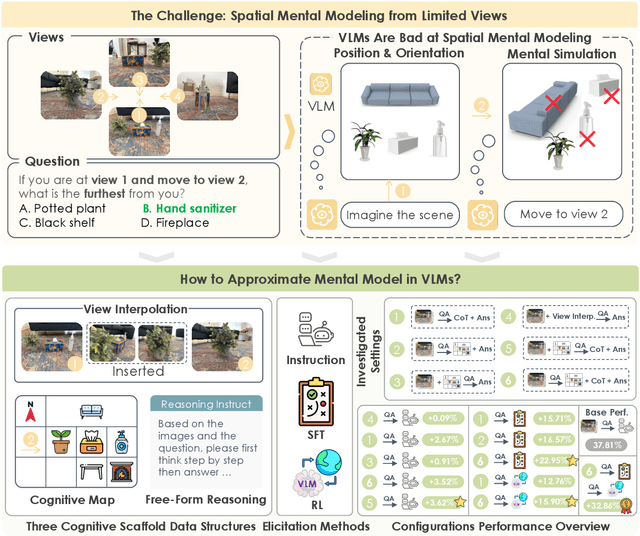

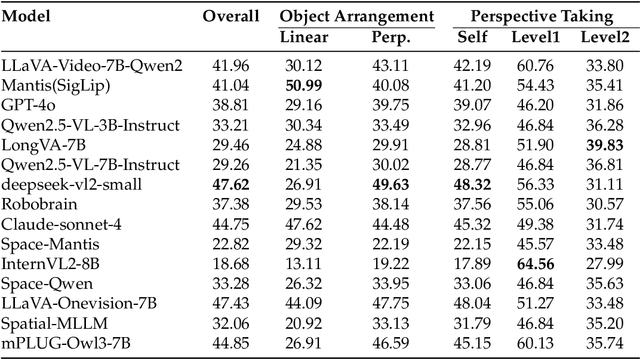
Can Vision Language Models (VLMs) imagine the full scene from just a few views, like humans do? Humans form spatial mental models, internal representations of unseen space, to reason about layout, perspective, and motion. Our new MindCube benchmark with 21,154 questions across 3,268 images exposes this critical gap, where existing VLMs exhibit near-random performance. Using MindCube, we systematically evaluate how well VLMs build robust spatial mental models through representing positions (cognitive mapping), orientations (perspective-taking), and dynamics (mental simulation for "what-if" movements). We then explore three approaches to help VLMs approximate spatial mental models, including unseen intermediate views, natural language reasoning chains, and cognitive maps. The significant improvement comes from a synergistic approach, "map-then-reason", that jointly trains the model to first generate a cognitive map and then reason upon it. By training models to reason over these internal maps, we boosted accuracy from 37.8% to 60.8% (+23.0%). Adding reinforcement learning pushed performance even further to 70.7% (+32.9%). Our key insight is that such scaffolding of spatial mental models, actively constructing and utilizing internal structured spatial representations with flexible reasoning processes, significantly improves understanding of unobservable space.
WebCoT: Enhancing Web Agent Reasoning by Reconstructing Chain-of-Thought in Reflection, Branching, and Rollback
May 26, 2025Web agents powered by Large Language Models (LLMs) show promise for next-generation AI, but their limited reasoning in uncertain, dynamic web environments hinders robust deployment. In this paper, we identify key reasoning skills essential for effective web agents, i.e., reflection & lookahead, branching, and rollback, and curate trajectory data that exemplifies these abilities by reconstructing the agent's (inference-time) reasoning algorithms into chain-of-thought rationales. We conduct experiments in the agent self-improving benchmark, OpenWebVoyager, and demonstrate that distilling salient reasoning patterns into the backbone LLM via simple fine-tuning can substantially enhance its performance. Our approach yields significant improvements across multiple benchmarks, including WebVoyager, Mind2web-live, and SimpleQA (web search), highlighting the potential of targeted reasoning skill enhancement for web agents.
EquivPruner: Boosting Efficiency and Quality in LLM-Based Search via Action Pruning
May 22, 2025Large Language Models (LLMs) excel at complex reasoning through search algorithms, yet current strategies often suffer from massive token consumption due to redundant exploration of semantically equivalent steps. Existing semantic similarity methods struggle to accurately identify such equivalence in domain-specific contexts like mathematical reasoning. To address this, we propose EquivPruner, a simple yet effective approach that identifies and prunes semantically equivalent actions during LLM reasoning search. We also introduce MathEquiv, the first dataset we created for mathematical statement equivalence, which enables the training of a lightweight equivalence detector. Extensive experiments across various models and tasks demonstrate that EquivPruner significantly reduces token consumption, improving searching efficiency and often bolstering reasoning accuracy. For instance, when applied to Qwen2.5-Math-7B-Instruct on GSM8K, EquivPruner reduced token consumption by 48.1\% while also improving accuracy. Our code is available at https://github.com/Lolo1222/EquivPruner.
Enhancing the Geometric Problem-Solving Ability of Multimodal LLMs via Symbolic-Neural Integration
Apr 17, 2025Recent advances in Multimodal Large Language Models (MLLMs) have achieved remarkable progress in general domains and demonstrated promise in multimodal mathematical reasoning. However, applying MLLMs to geometry problem solving (GPS) remains challenging due to lack of accurate step-by-step solution data and severe hallucinations during reasoning. In this paper, we propose GeoGen, a pipeline that can automatically generates step-wise reasoning paths for geometry diagrams. By leveraging the precise symbolic reasoning, \textbf{GeoGen} produces large-scale, high-quality question-answer pairs. To further enhance the logical reasoning ability of MLLMs, we train \textbf{GeoLogic}, a Large Language Model (LLM) using synthetic data generated by GeoGen. Serving as a bridge between natural language and symbolic systems, GeoLogic enables symbolic tools to help verifying MLLM outputs, making the reasoning process more rigorous and alleviating hallucinations. Experimental results show that our approach consistently improves the performance of MLLMs, achieving remarkable results on benchmarks for geometric reasoning tasks. This improvement stems from our integration of the strengths of LLMs and symbolic systems, which enables a more reliable and interpretable approach for the GPS task. Codes are available at https://github.com/ycpNotFound/GeoGen.
VLM$^2$-Bench: A Closer Look at How Well VLMs Implicitly Link Explicit Matching Visual Cues
Feb 17, 2025



Visually linking matching cues is a crucial ability in daily life, such as identifying the same person in multiple photos based on their cues, even without knowing who they are. Despite the extensive knowledge that vision-language models (VLMs) possess, it remains largely unexplored whether they are capable of performing this fundamental task. To address this, we introduce VLM$^2$-Bench, a benchmark designed to assess whether VLMs can Visually Link Matching cues, with 9 subtasks and over 3,000 test cases. Comprehensive evaluation across eight open-source VLMs and GPT-4o, along with further analysis of various language-side and vision-side prompting methods, leads to a total of eight key findings. We identify critical challenges in models' ability to link visual cues, highlighting a significant performance gap where even GPT-4o lags 34.80% behind humans. Based on these insights, we advocate for (i) enhancing core visual capabilities to improve adaptability and reduce reliance on prior knowledge, (ii) establishing clearer principles for integrating language-based reasoning in vision-centric tasks to prevent unnecessary biases, and (iii) shifting vision-text training paradigms toward fostering models' ability to independently structure and infer relationships among visual cues.