 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-RM: Execution-free Feedback For Software Engineering Agents
Dec 26, 2025
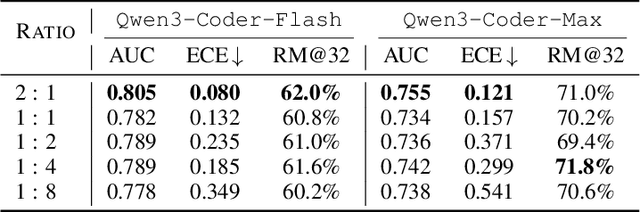

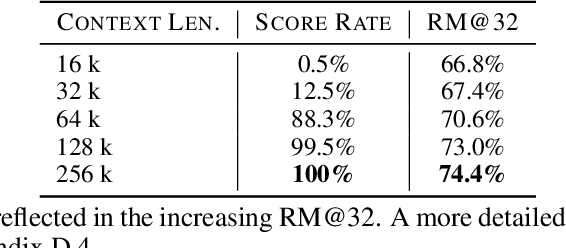
Execution-based feedback like unit testing is widely used in the development of coding agents through test-time scaling (TTS) and reinforcement learning (RL). This paradigm requires scalable and reliable collection of unit test cases to provide accurate feedback, and the resulting feedback is often sparse and cannot effectively distinguish between trajectories that are both successful or both unsuccessful. In contrast, execution-free feedback from reward models can provide more fine-grained signals without depending on unit test cases. Despite this potential, execution-free feedback for realistic software engineering (SWE) agents remains underexplored. Aiming to develop versatile reward models that are effective across TTS and RL, however, we observe that two verifiers with nearly identical TTS performance can nevertheless yield very different results in RL. Intuitively, TTS primarily reflects the model's ability to select the best trajectory, but this ability does not necessarily generalize to RL. To address this limitation, we identify two additional aspects that are crucial for RL training: classification accuracy and calibration. We then conduct comprehensive controlled experiments to investigate how to train a robust reward model that performs well across these metrics. In particular, we analyze the impact of various factors such as training data scale, policy mixtures, and data source composition. Guided by these investigations, we introduce SWE-RM, an accurate and robust reward model adopting a mixture-of-experts architecture with 30B total parameters and 3B activated during inference. SWE-RM substantially improves SWE agents on both TTS and RL performance. For example, it increases the accuracy of Qwen3-Coder-Flash from 51.6% to 62.0%, and Qwen3-Coder-Max from 67.0% to 74.6% on SWE-Bench Verified using TTS, achieving new state-of-the-art performance among open-source models.
FIRST: Teach A Reliable Large Language Model Through Efficient Trustworthy Distillation
Aug 22, 2024Large language models (LLMs) have become increasingly prevalent in our daily lives, leading to an expectation for LLMs to be trustworthy -- - both accurate and well-calibrated (the prediction confidence should align with its ground truth correctness likelihood). Nowadays, fine-tuning has become the most popular method for adapting a model to practical usage by significantly increasing accuracy on downstream tasks. Despite the great accuracy it achieves, we found fine-tuning is still far away from satisfactory trustworthiness due to "tuning-induced mis-calibration". In this paper, we delve deeply into why and how mis-calibration exists in fine-tuned models, and how distillation can alleviate the issue. Then we further propose a brand new method named Efficient Trustworthy Distillation (FIRST), which utilizes a small portion of teacher's knowledge to obtain a reliable language model in a cost-efficient way. Specifically, we identify the "concentrated knowledge" phenomenon during distillation, which can significantly reduce the computational burden. Then we apply a "trustworthy maximization" process to optimize the utilization of this small portion of concentrated knowledge before transferring it to the student. Experimental results demonstrate the effectiveness of our method, where better accuracy (+2.3%) and less mis-calibration (-10%) are achieved on average across both in-domain and out-of-domain scenarios, indicating better trustworthiness.
Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data
Feb 24, 2023



Chain-of-thought prompting (CoT) advances the reasoning abilities of large language models (LLMs) and achieves superior performance in arithmetic, commonsense, and symbolic reasoning tasks. However, most CoT studies rely on carefully designed human-annotated rational chains to prompt the language model, which poses challenges for real-world applications where labeled training data is available without human-annotated rational chains. This creates barriers to applications of CoT prompting to these general tasks. This paper proposes a new strategy, Automate-CoT (Automatic Prompt Augmentation and Selection with Chain-of-Thought), that can bypass human engineering of CoTs by automatically augmenting rational chains from a small labeled dataset, and then pruning low-quality chains to construct a candidate pool of machine-generated rationale chains based on the labels. Finally, it selects the optimal combination of several rationale chains from the pool for CoT prompting by employing a variance-reduced policy gradient strategy to estimate the significance of each example in a black-box language model. Automate-CoT enables a quick adaptation of the CoT technique to different tasks. Experimental results demonstrate the effectiveness of our method, where state-of-the-art results are achieved on arithmetic reasoning (+2.7\%), commonsense reasoning (+3.4\%), symbolic reasoning (+3.2\%), and non-reasoning tasks (+2.5\%). Our code will be available at https://github.com/shizhediao/automate-cot.