 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Comprehensive Stage-wise Benchmarking of Large Language Models in Fact-Checking
Jan 06, 2026Large Language Models (LLMs) are increasingly deployed in real-world fact-checking systems, yet existing evaluations focus predominantly on claim verification and overlook the broader fact-checking workflow, including claim extraction and evidence retrieval. This narrow focus prevents current benchmarks from revealing systematic reasoning failures, factual blind spots, and robustness limitations of modern LLMs. To bridge this gap, we present FactArena, a fully automated arena-style evaluation framework that conducts comprehensive, stage-wise benchmarking of LLMs across the complete fact-checking pipeline. FactArena integrates three key components: (i) an LLM-driven fact-checking process that standardizes claim decomposition, evidence retrieval via tool-augmented interactions, and justification-based verdict prediction; (ii) an arena-styled judgment mechanism guided by consolidated reference guidelines to ensure unbiased and consistent pairwise comparisons across heterogeneous judge agents; and (iii) an arena-driven claim-evolution module that adaptively generates more challenging and semantically controlled claims to probe LLMs' factual robustness beyond fixed seed data. Across 16 state-of-the-art LLMs spanning seven model families, FactArena produces stable and interpretable rankings. Our analyses further reveal significant discrepancies between static claim-verification accuracy and end-to-end fact-checking competence, highlighting the necessity of holistic evaluation. The proposed framework offers a scalable and trustworthy paradigm for diagnosing LLMs' factual reasoning, guiding future model development, and advancing the reliable deployment of LLMs in safety-critical fact-checking applications.
VizDefender: Unmasking Visualization Tampering through Proactive Localization and Intent Inference
Dec 21, 2025
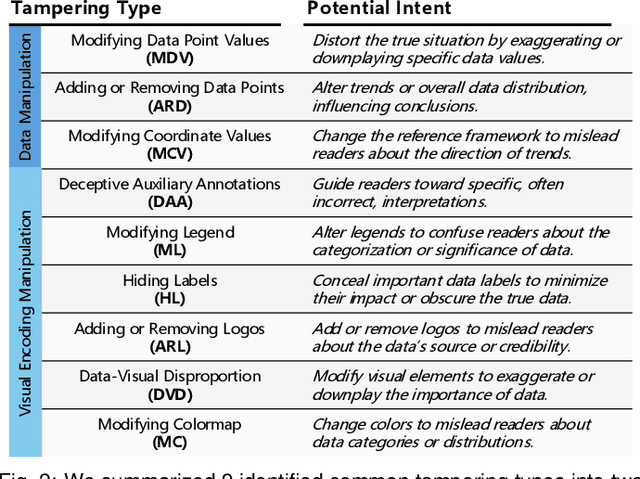
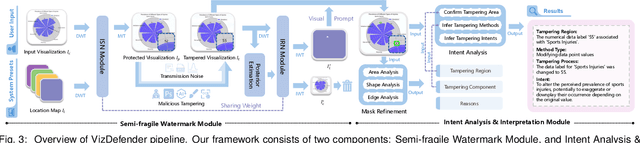
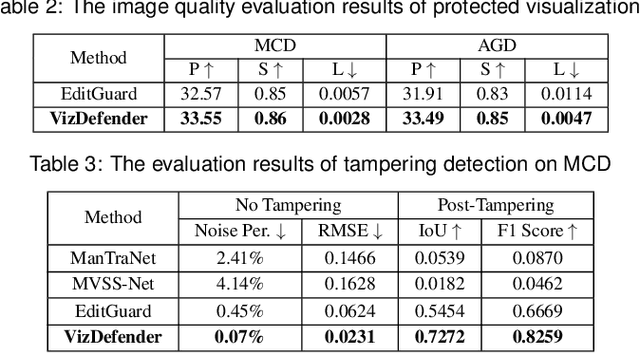
The integrity of data visualizations is increasingly threatened by image editing techniques that enable subtle yet deceptive tampering. Through a formative study, we define this challenge and categorize tampering techniques into two primary types: data manipulation and visual encoding manipulation. To address this, we present VizDefender, a framework for tampering detection and analysis. The framework integrates two core components: 1) a semi-fragile watermark module that protects the visualization by embedding a location map to images, which allows for the precise localization of tampered regions while preserving visual quality, and 2) an intent analysis module that leverages Multimodal Large Language Models (MLLMs) to interpret manipulation, inferring the attacker's intent and misleading effects. Extensive evaluations and user studies demonstrate the effectiveness of our methods.
MemeArena: Automating Context-Aware Unbiased Evaluation of Harmfulness Understanding for Multimodal Large Language Models
Oct 31, 2025The proliferation of memes on social media necessitates the capabilities of multimodal Large Language Models (mLLMs) to effectively understand multimodal harmfulness. Existing evaluation approaches predominantly focus on mLLMs' detection accuracy for binary classification tasks, which often fail to reflect the in-depth interpretive nuance of harmfulness across diverse contexts. In this paper, we propose MemeArena, an agent-based arena-style evaluation framework that provides a context-aware and unbiased assessment for mLLMs' understanding of multimodal harmfulness. Specifically, MemeArena simulates diverse interpretive contexts to formulate evaluation tasks that elicit perspective-specific analyses from mLLMs. By integrating varied viewpoints and reaching consensus among evaluators, it enables fair and unbiased comparisons of mLLMs' abilities to interpret multimodal harmfulness. Extensive experiments demonstrate that our framework effectively reduces the evaluation biases of judge agents, with judgment results closely aligning with human preferences, offering valuable insights into reliable and comprehensive mLLM evaluations in multimodal harmfulness understanding. Our code and data are publicly available at https://github.com/Lbotirx/MemeArena.
AdamMeme: Adaptively Probe the Reasoning Capacity of Multimodal Large Language Models on Harmfulness
Jul 02, 2025The proliferation of multimodal memes in the social media era demands that multimodal Large Language Models (mLLMs) effectively understand meme harmfulness. Existing benchmarks for assessing mLLMs on harmful meme understanding rely on accuracy-based, model-agnostic evaluations using static datasets. These benchmarks are limited in their ability to provide up-to-date and thorough assessments, as online memes evolve dynamically. To address this, we propose AdamMeme, a flexible, agent-based evaluation framework that adaptively probes the reasoning capabilities of mLLMs in deciphering meme harmfulness. Through multi-agent collaboration, AdamMeme provides comprehensive evaluations by iteratively updating the meme data with challenging samples, thereby exposing specific limitations in how mLLMs interpret harmfulness. Extensive experiments show that our framework systematically reveals the varying performance of different target mLLMs, offering in-depth, fine-grained analyses of model-specific weaknesses. Our code is available at https://github.com/Lbotirx/AdamMeme.
ResAD: A Simple Framework for Class Generalizable Anomaly Detection
Oct 26, 2024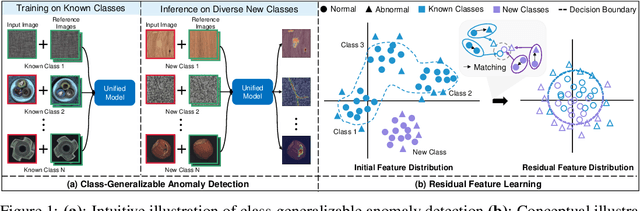
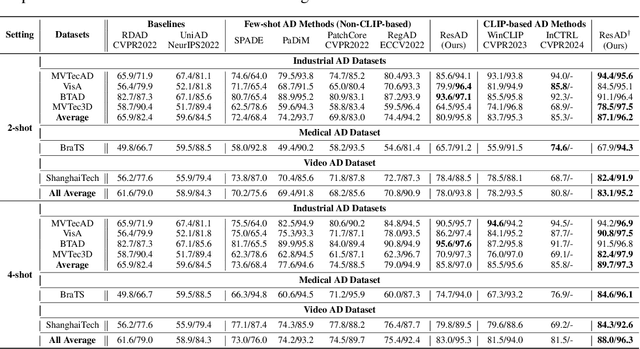
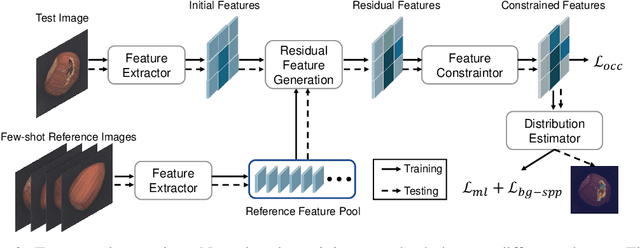
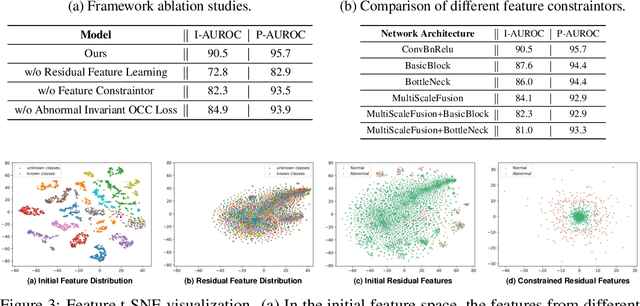
This paper explores the problem of class-generalizable anomaly detection, where the objective is to train one unified AD model that can generalize to detect anomalies in diverse classes from different domains without any retraining or fine-tuning on the target data. Because normal feature representations vary significantly across classes, this will cause the widely studied one-for-one AD models to be poorly classgeneralizable (i.e., performance drops dramatically when used for new classes). In this work, we propose a simple but effective framework (called ResAD) that can be directly applied to detect anomalies in new classes. Our main insight is to learn the residual feature distribution rather than the initial feature distribution. In this way, we can significantly reduce feature variations. Even in new classes, the distribution of normal residual features would not remarkably shift from the learned distribution. Therefore, the learned model can be directly adapted to new classes. ResAD consists of three components: (1) a Feature Converter that converts initial features into residual features; (2) a simple and shallow Feature Constraintor that constrains normal residual features into a spatial hypersphere for further reducing feature variations and maintaining consistency in feature scales among different classes; (3) a Feature Distribution Estimator that estimates the normal residual feature distribution, anomalies can be recognized as out-of-distribution. Despite the simplicity, ResAD can achieve remarkable anomaly detection results when directly used in new classes. The code is available at https://github.com/xcyao00/ResAD.
FIRST: Teach A Reliable Large Language Model Through Efficient Trustworthy Distillation
Aug 22, 2024Large language models (LLMs) have become increasingly prevalent in our daily lives, leading to an expectation for LLMs to be trustworthy -- - both accurate and well-calibrated (the prediction confidence should align with its ground truth correctness likelihood). Nowadays, fine-tuning has become the most popular method for adapting a model to practical usage by significantly increasing accuracy on downstream tasks. Despite the great accuracy it achieves, we found fine-tuning is still far away from satisfactory trustworthiness due to "tuning-induced mis-calibration". In this paper, we delve deeply into why and how mis-calibration exists in fine-tuned models, and how distillation can alleviate the issue. Then we further propose a brand new method named Efficient Trustworthy Distillation (FIRST), which utilizes a small portion of teacher's knowledge to obtain a reliable language model in a cost-efficient way. Specifically, we identify the "concentrated knowledge" phenomenon during distillation, which can significantly reduce the computational burden. Then we apply a "trustworthy maximization" process to optimize the utilization of this small portion of concentrated knowledge before transferring it to the student. Experimental results demonstrate the effectiveness of our method, where better accuracy (+2.3%) and less mis-calibration (-10%) are achieved on average across both in-domain and out-of-domain scenarios, indicating better trustworthiness.
StuGPTViz: A Visual Analytics Approach to Understand Student-ChatGPT Interactions
Jul 17, 2024



The integration of Large Language Models (LLMs), especially ChatGPT, into education is poised to revolutionize students' learning experiences by introducing innovative conversational learning methodologies. To empower students to fully leverage the capabilities of ChatGPT in educational scenarios, understanding students' interaction patterns with ChatGPT is crucial for instructors. However, this endeavor is challenging due to the absence of datasets focused on student-ChatGPT conversations and the complexities in identifying and analyzing the evolutional interaction patterns within conversations. To address these challenges, we collected conversational data from 48 students interacting with ChatGPT in a master's level data visualization course over one semester. We then developed a coding scheme, grounded in the literature on cognitive levels and thematic analysis, to categorize students' interaction patterns with ChatGPT. Furthermore, we present a visual analytics system, StuGPTViz, that tracks and compares temporal patterns in student prompts and the quality of ChatGPT's responses at multiple scales, revealing significant pedagogical insights for instructors. We validated the system's effectiveness through expert interviews with six data visualization instructors and three case studies. The results confirmed StuGPTViz's capacity to enhance educators' insights into the pedagogical value of ChatGPT. We also discussed the potential research opportunities of applying visual analytics in education and developing AI-driven personalized learning solutions.
CofiPara: A Coarse-to-fine Paradigm for Multimodal Sarcasm Target Identification with Large Multimodal Models
May 01, 2024



Social media abounds with multimodal sarcasm, and identifying sarcasm targets is particularly challenging due to the implicit incongruity not directly evident in the text and image modalities. Current methods for Multimodal Sarcasm Target Identification (MSTI) predominantly focus on superficial indicators in an end-to-end manner, overlooking the nuanced understanding of multimodal sarcasm conveyed through both the text and image. This paper proposes a versatile MSTI framework with a coarse-to-fine paradigm, by augmenting sarcasm explainability with reasoning and pre-training knowledge. Inspired by the powerful capacity of Large Multimodal Models (LMMs) on multimodal reasoning, we first engage LMMs to generate competing rationales for coarser-grained pre-training of a small language model on multimodal sarcasm detection. We then propose fine-tuning the model for finer-grained sarcasm target identification. Our framework is thus empowered to adeptly unveil the intricate targets within multimodal sarcasm and mitigate the negative impact posed by potential noise inherently in LMMs. Experimental results demonstrate that our model far outperforms state-of-the-art MSTI methods, and markedly exhibits explainability in deciphering sarcasm as well.
Weaver: Foundation Models for Creative Writing
Jan 30, 2024

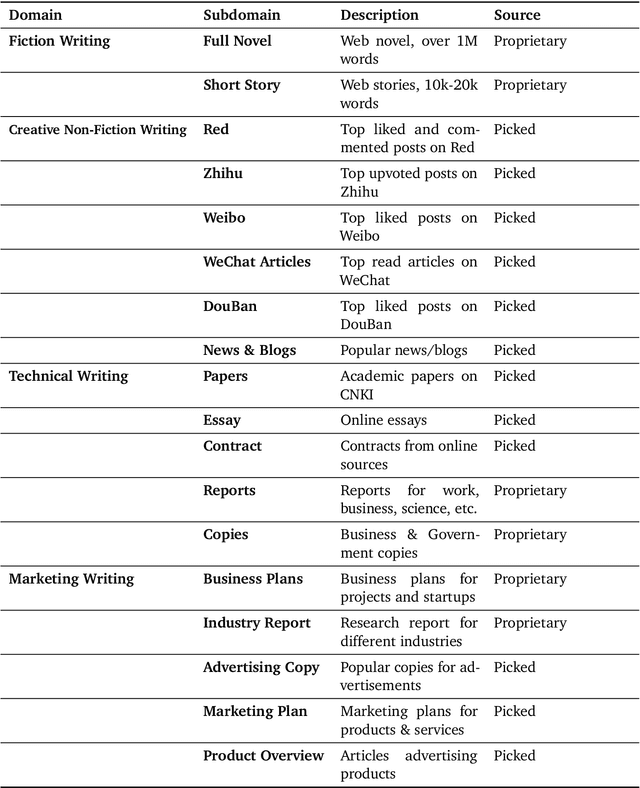

This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
VideoPro: A Visual Analytics Approach for Interactive Video Programming
Aug 01, 2023


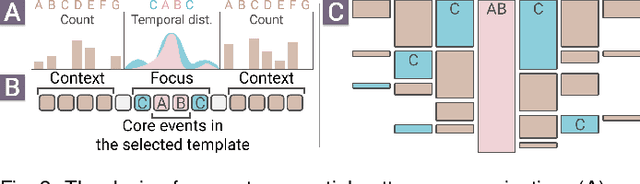
Constructing supervised machine learning models for real-world video analysis require substantial labeled data, which is costly to acquire due to scarce domain expertise and laborious manual inspection. While data programming shows promise in generating labeled data at scale with user-defined labeling functions, the high dimensional and complex temporal information in videos poses additional challenges for effectively composing and evaluating labeling functions. In this paper, we propose VideoPro, a visual analytics approach to support flexible and scalable video data programming for model steering with reduced human effort. We first extract human-understandable events from videos using computer vision techniques and treat them as atomic components of labeling functions. We further propose a two-stage template mining algorithm that characterizes the sequential patterns of these events to serve as labeling function templates for efficient data labeling. The visual interface of VideoPro facilitates multifaceted exploration, examination, and application of the labeling templates, allowing for effective programming of video data at scale. Moreover, users can monitor the impact of programming on model performance and make informed adjustments during the iterative programming process. We demonstrate the efficiency and effectiveness of our approach with two case studies and expert interviews.