 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinHarness: An Inline Lifecycle Safety Harness for Finance LLM Agents
May 26, 2026Finance LLM agents must simultaneously block prompt-induced unauthorized actions and approve legitimate multi-step business workflows. However, boundary filters often miss irreversible mid-trajectory tool calls, while post-hoc LLM judges perform auditing only after termination -- too late for intervention and at a computational cost that scales linearly with trace length. We present FinHarness, an inline safety harness that wraps a finance agent end-to-end with three components: a Query Monitor that fuses single-turn intent with cross-turn drift, a Tool Monitor that evaluates each prospective tool call, and a Cascade module that integrates per-step risk and adaptively routes verification between a lightweight and an advanced-tier LLM judge. Fired risk factors are re-injected into the agent input as ex-ante evidence, enabling the agent to refuse, re-plan, or approve on its own. On FinVault, routed FinHarness cuts ASR from 38.3% to 15.0% while largely preserving benign approval ($41.1\% \to 39.3\%$), and uses $4.7\times$ fewer advanced-judge calls than an always-advanced ablation.
Beyond Binary: Reframing GUI Critique as Continuous Semantic Alignment
May 14, 2026Test-Time Scaling (TTS), which samples multiple candidate actions and ranks them via a Critic Model, has emerged as a promising paradigm for generalist GUI agents. Its efficacy thus hinges on the critic's fine-grained ranking ability. However, existing GUI critic models uniformly adopt binary classification. Our motivational analysis of these models exposes a severe entanglement: scores for valid actions and plausible-but-invalid distractors become indistinguishable. We attribute this failure to two structural defects: Affordance Collapse--the hierarchical affordance space is compressed into 0/1 labels; and Noise Sensitivity--binary objectives overfit to noisy decision boundaries. To resolve this, we introduce BBCritic (Beyond-Binary Critic), a paradigm shift grounded in the Functional Equivalence Hypothesis. Through two-stage contrastive learning, BBCritic aligns instructions and actions in a shared Affordance Space, recovering the hierarchical structure that binary supervision flattens. We also present BBBench (Beyond-Binary Bench), the first GUI critic benchmark that pairs a dense action space with a hierarchical four-level taxonomy, enabling fine-grained ranking evaluation. Experimental results show that BBCritic-3B, trained without any extra annotation, outperforms 7B-parameter SOTA binary models. It demonstrates strong zero-shot transferability across platforms and tasks, supporting our methodological view: GUI critique is fundamentally a metric-learning problem, not a classification one.
MMR-AD: A Large-Scale Multimodal Dataset for Benchmarking General Anomaly Detection with Multimodal Large Language Models
Apr 13, 2026In the progress of industrial anomaly detection, general anomaly detection (GAD) is an emerging trend and also the ultimate goal. Unlike the conventional single- and multi-class AD, general AD aims to train a general AD model that can directly detect anomalies in diverse novel classes without any retraining or fine-tuning on the target data. Recently, Multimodal Large Language Models (MLLMs) have shown great promise in achieving general anomaly detection due to their revolutionary visual understanding and language reasoning capabilities. However, MLLM's general AD ability remains underexplored due to: (1) MLLMs are pretrained on amounts of data sourced from the Web, these data still have significant gaps with the data in AD scenarios. Moreover, the image-text pairs during pretraining are also not specifically for AD tasks. (2) The current mainstream AD datasets are image-based and not yet suitable for post-training MLLMs. To facilitate MLLM-based general AD research, we present MMR-AD, which is a comprehensive benchmark for both training and evaluating MLLM-based AD models. With MMR-AD, we reveal that the AD performance of current SOTA generalist MLLMs still falls far behind the industrial requirements. Based on MMR-AD, we also propose a baseline model, Anomaly-R1, which is a reasoning-based AD model that learns from the CoT data in MMR-AD and is further enhanced by reinforcement learning. Extensive experiments show that our Anomaly-R1 achieves remarkable improvements over generalist MLLMs in both anomaly detection and localization.
ADPretrain: Advancing Industrial Anomaly Detection via Anomaly Representation Pretraining
Nov 07, 2025The current mainstream and state-of-the-art anomaly detection (AD) methods are substantially established on pretrained feature networks yielded by ImageNet pretraining. However, regardless of supervised or self-supervised pretraining, the pretraining process on ImageNet does not match the goal of anomaly detection (i.e., pretraining in natural images doesn't aim to distinguish between normal and abnormal). Moreover, natural images and industrial image data in AD scenarios typically have the distribution shift. The two issues can cause ImageNet-pretrained features to be suboptimal for AD tasks. To further promote the development of the AD field, pretrained representations specially for AD tasks are eager and very valuable. To this end, we propose a novel AD representation learning framework specially designed for learning robust and discriminative pretrained representations for industrial anomaly detection. Specifically, closely surrounding the goal of anomaly detection (i.e., focus on discrepancies between normals and anomalies), we propose angle- and norm-oriented contrastive losses to maximize the angle size and norm difference between normal and abnormal features simultaneously. To avoid the distribution shift from natural images to AD images, our pretraining is performed on a large-scale AD dataset, RealIAD. To further alleviate the potential shift between pretraining data and downstream AD datasets, we learn the pretrained AD representations based on the class-generalizable representation, residual features. For evaluation, based on five embedding-based AD methods, we simply replace their original features with our pretrained representations. Extensive experiments on five AD datasets and five backbones consistently show the superiority of our pretrained features. The code is available at https://github.com/xcyao00/ADPretrain.
ResAD: A Simple Framework for Class Generalizable Anomaly Detection
Oct 26, 2024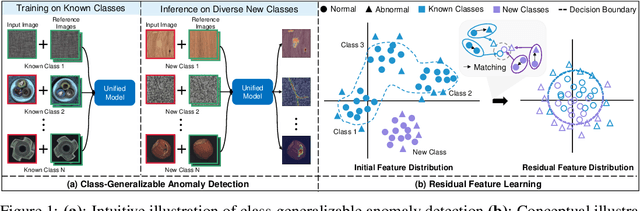
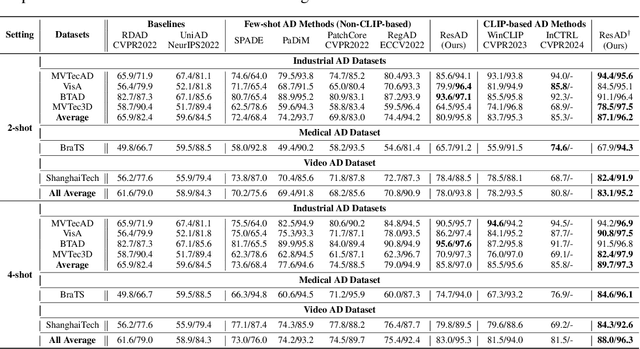
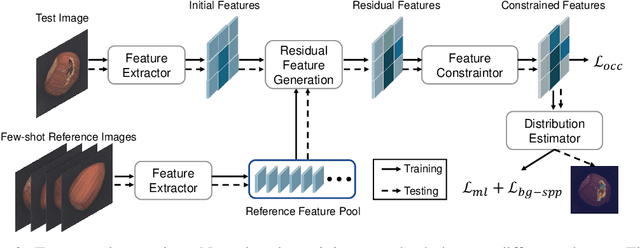
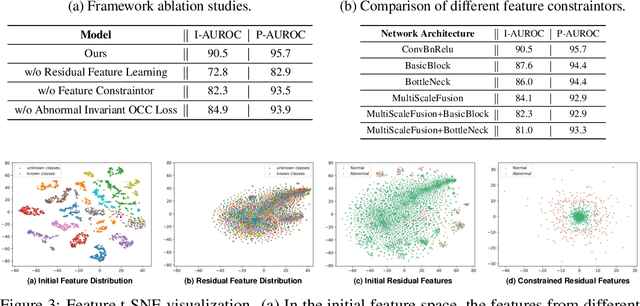
This paper explores the problem of class-generalizable anomaly detection, where the objective is to train one unified AD model that can generalize to detect anomalies in diverse classes from different domains without any retraining or fine-tuning on the target data. Because normal feature representations vary significantly across classes, this will cause the widely studied one-for-one AD models to be poorly classgeneralizable (i.e., performance drops dramatically when used for new classes). In this work, we propose a simple but effective framework (called ResAD) that can be directly applied to detect anomalies in new classes. Our main insight is to learn the residual feature distribution rather than the initial feature distribution. In this way, we can significantly reduce feature variations. Even in new classes, the distribution of normal residual features would not remarkably shift from the learned distribution. Therefore, the learned model can be directly adapted to new classes. ResAD consists of three components: (1) a Feature Converter that converts initial features into residual features; (2) a simple and shallow Feature Constraintor that constrains normal residual features into a spatial hypersphere for further reducing feature variations and maintaining consistency in feature scales among different classes; (3) a Feature Distribution Estimator that estimates the normal residual feature distribution, anomalies can be recognized as out-of-distribution. Despite the simplicity, ResAD can achieve remarkable anomaly detection results when directly used in new classes. The code is available at https://github.com/xcyao00/ResAD.
Hierarchical Gaussian Mixture Normalizing Flow Modeling for Unified Anomaly Detection
Mar 20, 2024Unified anomaly detection (AD) is one of the most challenges for anomaly detection, where one unified model is trained with normal samples from multiple classes with the objective to detect anomalies in these classes. For such a challenging task, popular normalizing flow (NF) based AD methods may fall into a "homogeneous mapping" issue,where the NF-based AD models are biased to generate similar latent representations for both normal and abnormal features, and thereby lead to a high missing rate of anomalies. In this paper, we propose a novel Hierarchical Gaussian mixture normalizing flow modeling method for accomplishing unified Anomaly Detection, which we call HGAD. Our HGAD consists of two key components: inter-class Gaussian mixture modeling and intra-class mixed class centers learning. Compared to the previous NF-based AD methods, the hierarchical Gaussian mixture modeling approach can bring stronger representation capability to the latent space of normalizing flows, so that even complex multi-class distribution can be well represented and learned in the latent space. In this way, we can avoid mapping different class distributions into the same single Gaussian prior, thus effectively avoiding or mitigating the "homogeneous mapping" issue. We further indicate that the more distinguishable different class centers, the more conducive to avoiding the bias issue. Thus, we further propose a mutual information maximization loss for better structuring the latent feature space. We evaluate our method on four real-world AD benchmarks, where we can significantly improve the previous NF-based AD methods and also outperform the SOTA unified AD methods.
Focus the Discrepancy: Intra- and Inter-Correlation Learning for Image Anomaly Detection
Aug 06, 2023



Humans recognize anomalies through two aspects: larger patch-wise representation discrepancies and weaker patch-to-normal-patch correlations. However, the previous AD methods didn't sufficiently combine the two complementary aspects to design AD models. To this end, we find that Transformer can ideally satisfy the two aspects as its great power in the unified modeling of patch-wise representations and patch-to-patch correlations. In this paper, we propose a novel AD framework: FOcus-the-Discrepancy (FOD), which can simultaneously spot the patch-wise, intra- and inter-discrepancies of anomalies. The major characteristic of our method is that we renovate the self-attention maps in transformers to Intra-Inter-Correlation (I2Correlation). The I2Correlation contains a two-branch structure to first explicitly establish intra- and inter-image correlations, and then fuses the features of two-branch to spotlight the abnormal patterns. To learn the intra- and inter-correlations adaptively, we propose the RBF-kernel-based target-correlations as learning targets for self-supervised learning. Besides, we introduce an entropy constraint strategy to solve the mode collapse issue in optimization and further amplify the normal-abnormal distinguishability. Extensive experiments on three unsupervised real-world AD benchmarks show the superior performance of our approach. Code will be available at https://github.com/xcyao00/FOD.
Towards Diverse Temporal Grounding under Single Positive Labels
Mar 12, 2023Temporal grounding aims to retrieve moments of the described event within an untrimmed video by a language query. Typically, existing methods assume annotations are precise and unique, yet one query may describe multiple moments in many cases. Hence, simply taking it as a one-vs-one mapping task and striving to match single-label annotations will inevitably introduce false negatives during optimization. In this study, we reformulate this task as a one-vs-many optimization problem under the condition of single positive labels. The unlabeled moments are considered unobserved rather than negative, and we explore mining potential positive moments to assist in multiple moment retrieval. In this setting, we propose a novel Diverse Temporal Grounding framework, termed DTG-SPL, which mainly consists of a positive moment estimation (PME) module and a diverse moment regression (DMR) module. PME leverages semantic reconstruction information and an expected positive regularization to uncover potential positive moments in an online fashion. Under the supervision of these pseudo positives, DMR is able to localize diverse moments in parallel that meet different users. The entire framework allows for end-to-end optimization as well as fast inference. Extensive experiments on Charades-STA and ActivityNet Captions show that our method achieves superior performance in terms of both single-label and multi-label metrics.
Explicit Boundary Guided Semi-Push-Pull Contrastive Learning for Better Anomaly Detection
Jul 04, 2022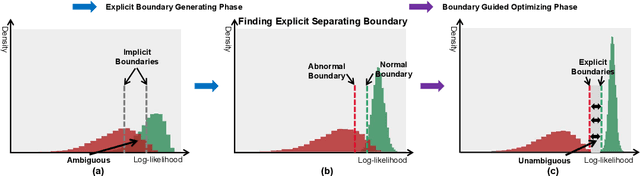
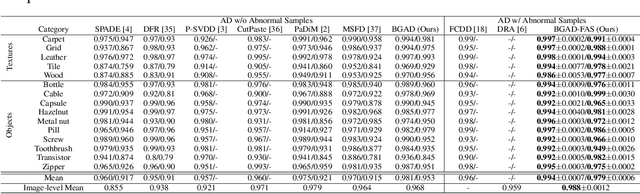


Most of anomaly detection algorithms are mainly focused on modeling the distribution of normal samples and treating anomalies as outliers. However, the discriminative performance of the model may be insufficient due to the lack of knowledge about anomalies. Thus, anomalies should be exploited as possible. However, utilizing a few known anomalies during training may cause another issue that model may be biased by those known anomalies and fail to generalize to unseen anomalies. In this paper, we aim to exploit a few existing anomalies with a carefully designed explicit boundary guided semi-push-pull learning strategy, which can enhance discriminability while mitigating bias problem caused by insufficient known anomalies. Our model is based on two core designs: First, finding one explicit separating boundary as the guidance for further contrastive learning. Specifically, we employ normalizing flow to learn normal feature distribution, then find an explicit separating boundary close to the distribution edge. The obtained explicit and compact separating boundary only relies on the normal feature distribution, thus the bias problem caused by a few known anomalies can be mitigated. Second, learning more discriminative features under the guidance of the explicit separating boundary. A boundary guided semi-push-pull loss is developed to only pull the normal features together while pushing the abnormal features apart from the separating boundary beyond a certain margin region. In this way, our model can form a more explicit and discriminative decision boundary to achieve better results for known and also unseen anomalies, while also maintaining high training efficiency. Extensive experiments on the widely-used MVTecAD benchmark show that the proposed method achieves new state-of-the-art results, with the performance of 98.8% image-level AUROC and 99.4% pixel-level AUROC.
Embracing Uncertainty: Decoupling and De-bias for Robust Temporal Grounding
Mar 31, 2021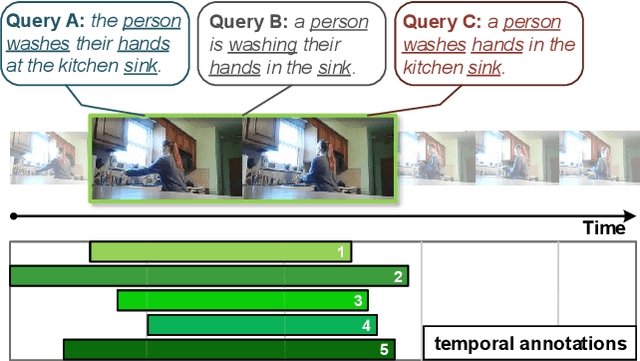
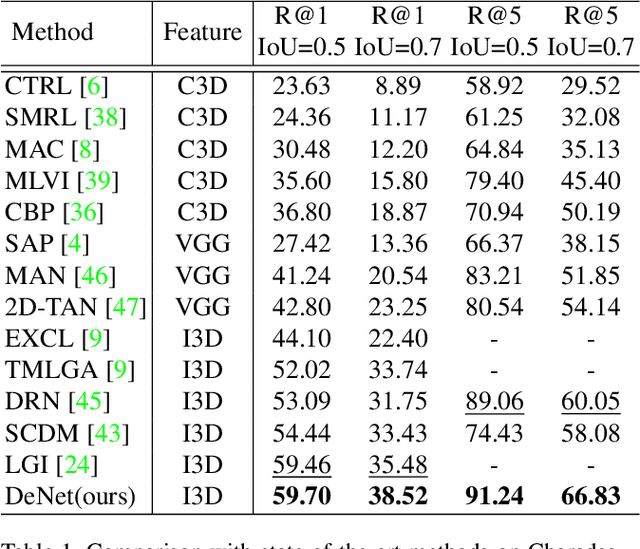
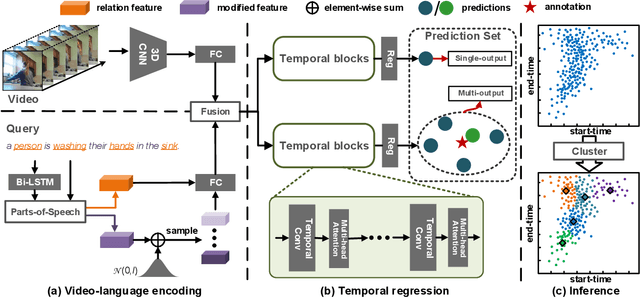
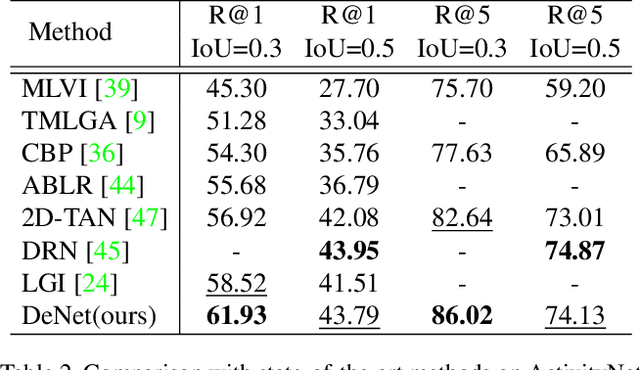
Temporal grounding aims to localize temporal boundaries within untrimmed videos by language queries, but it faces the challenge of two types of inevitable human uncertainties: query uncertainty and label uncertainty. The two uncertainties stem from human subjectivity, leading to limited generalization ability of temporal grounding. In this work, we propose a novel DeNet (Decoupling and De-bias) to embrace human uncertainty: Decoupling - We explicitly disentangle each query into a relation feature and a modified feature. The relation feature, which is mainly based on skeleton-like words (including nouns and verbs), aims to extract basic and consistent information in the presence of query uncertainty. Meanwhile, modified feature assigned with style-like words (including adjectives, adverbs, etc) represents the subjective information, and thus brings personalized predictions; De-bias - We propose a de-bias mechanism to generate diverse predictions, aim to alleviate the bias caused by single-style annotations in the presence of label uncertainty. Moreover, we put forward new multi-label metrics to diversify the performance evaluation. Extensive experiments show that our approach is more effective and robust than state-of-the-arts on Charades-STA and ActivityNet Captions datasets.