 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Diverse Temporal Grounding under Single Positive Labels
Mar 12, 2023Temporal grounding aims to retrieve moments of the described event within an untrimmed video by a language query. Typically, existing methods assume annotations are precise and unique, yet one query may describe multiple moments in many cases. Hence, simply taking it as a one-vs-one mapping task and striving to match single-label annotations will inevitably introduce false negatives during optimization. In this study, we reformulate this task as a one-vs-many optimization problem under the condition of single positive labels. The unlabeled moments are considered unobserved rather than negative, and we explore mining potential positive moments to assist in multiple moment retrieval. In this setting, we propose a novel Diverse Temporal Grounding framework, termed DTG-SPL, which mainly consists of a positive moment estimation (PME) module and a diverse moment regression (DMR) module. PME leverages semantic reconstruction information and an expected positive regularization to uncover potential positive moments in an online fashion. Under the supervision of these pseudo positives, DMR is able to localize diverse moments in parallel that meet different users. The entire framework allows for end-to-end optimization as well as fast inference. Extensive experiments on Charades-STA and ActivityNet Captions show that our method achieves superior performance in terms of both single-label and multi-label metrics.
RLM-Tracking: Online Multi-Pedestrian Tracking Supported by Relative Location Mapping
Oct 19, 2022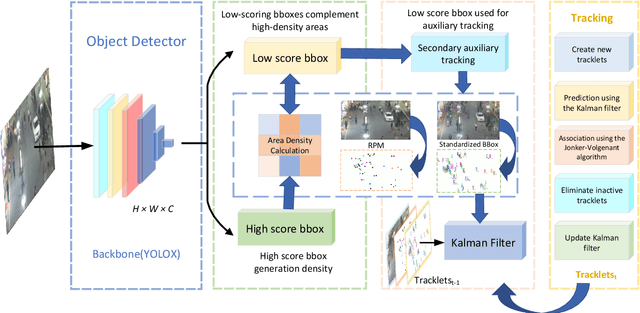

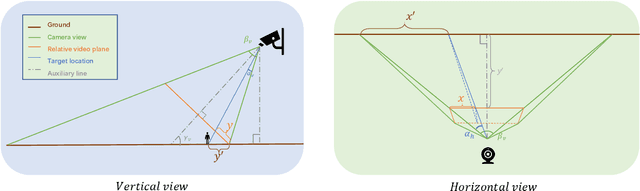
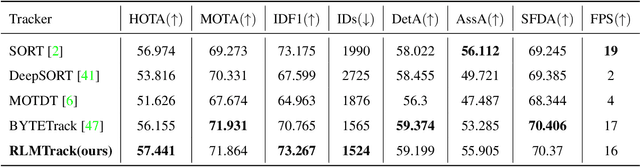
The problem of multi-object tracking is a fundamental computer vision research focus, widely used in public safety, transport, autonomous vehicles, robotics, and other regions involving artificial intelligence. Because of the complexity of natural scenes, object occlusion and semi-occlusion usually occur in fundamental tracking tasks. These can easily lead to ID switching, object loss, detect errors, and misaligned limitation boxes. These conditions have a significant impact on the precision of multi-object tracking. In this paper, we design a new multi-object tracker for the above issues that contains an object \textbf{Relative Location Mapping} (RLM) model and \textbf{Target Region Density} (TRD) model. The new tracker is more sensitive to the differences in position relationships between objects. It can introduce low-score detection frames into different regions in real-time according to the density of object regions in the video. This improves the accuracy of object tracking without consuming extensive arithmetic resources. Our study shows that the proposed model has considerably enhanced the HOTA and DF1 measurements on the MOT17 and MOT20 data sets when applied to the advanced MOT method.
Embracing Uncertainty: Decoupling and De-bias for Robust Temporal Grounding
Mar 31, 2021
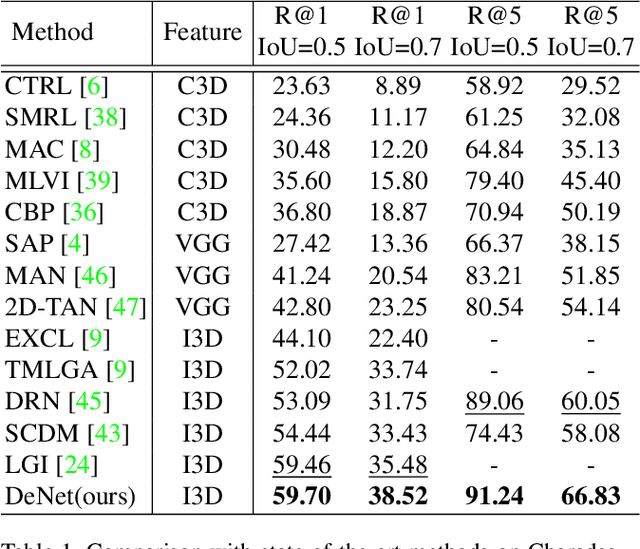
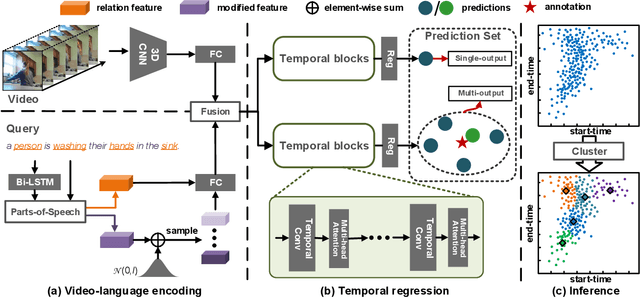
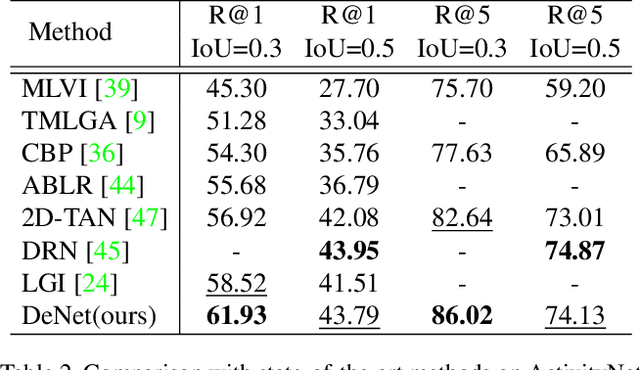
Temporal grounding aims to localize temporal boundaries within untrimmed videos by language queries, but it faces the challenge of two types of inevitable human uncertainties: query uncertainty and label uncertainty. The two uncertainties stem from human subjectivity, leading to limited generalization ability of temporal grounding. In this work, we propose a novel DeNet (Decoupling and De-bias) to embrace human uncertainty: Decoupling - We explicitly disentangle each query into a relation feature and a modified feature. The relation feature, which is mainly based on skeleton-like words (including nouns and verbs), aims to extract basic and consistent information in the presence of query uncertainty. Meanwhile, modified feature assigned with style-like words (including adjectives, adverbs, etc) represents the subjective information, and thus brings personalized predictions; De-bias - We propose a de-bias mechanism to generate diverse predictions, aim to alleviate the bias caused by single-style annotations in the presence of label uncertainty. Moreover, we put forward new multi-label metrics to diversify the performance evaluation. Extensive experiments show that our approach is more effective and robust than state-of-the-arts on Charades-STA and ActivityNet Captions datasets.
Visual Relationship Detection with Relative Location Mining
Nov 02, 2019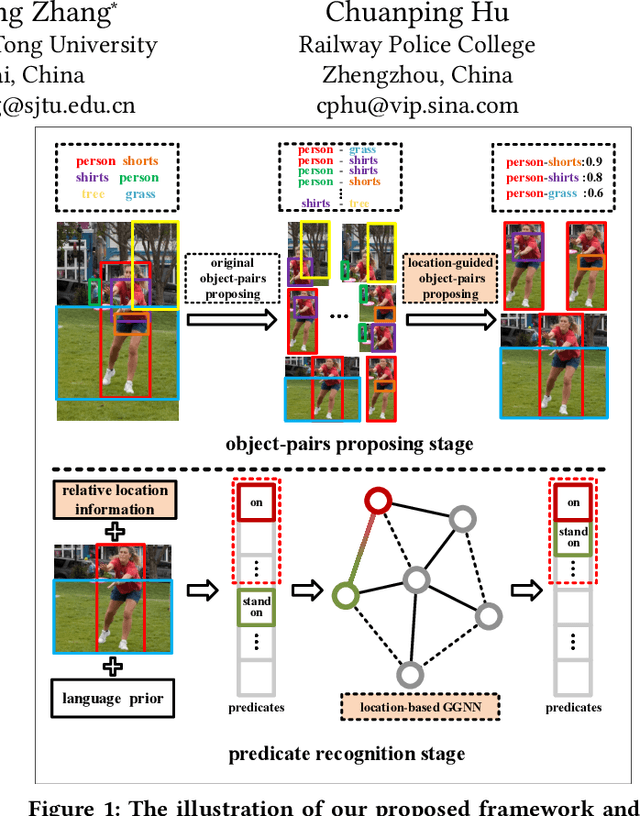
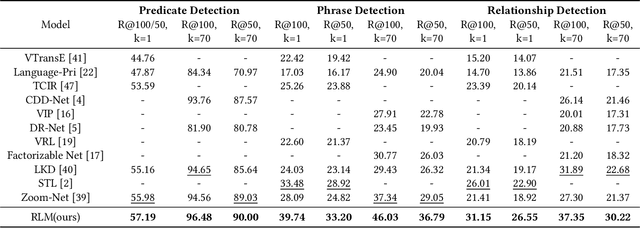

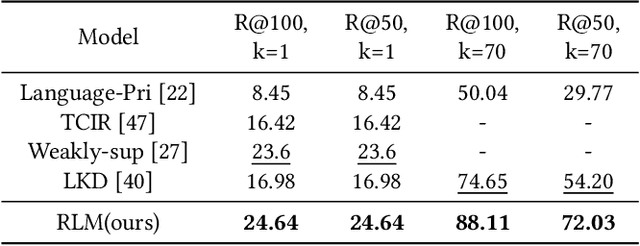
Visual relationship detection, as a challenging task used to find and distinguish the interactions between object pairs in one image, has received much attention recently. In this work, we propose a novel visual relationship detection framework by deeply mining and utilizing relative location of object-pair in every stage of the procedure. In both the stages, relative location information of each object-pair is abstracted and encoded as auxiliary feature to improve the distinguishing capability of object-pairs proposing and predicate recognition, respectively; Moreover, one Gated Graph Neural Network(GGNN) is introduced to mine and measure the relevance of predicates using relative location. With the location-based GGNN, those non-exclusive predicates with similar spatial position can be clustered firstly and then be smoothed with close classification scores, thus the accuracy of top $n$ recall can be increased further. Experiments on two widely used datasets VRD and VG show that, with the deeply mining and exploiting of relative location information, our proposed model significantly outperforms the current state-of-the-art.