 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich to Match? Selecting Consistent GT-Proposal Assignment for Pedestrian Detection
Mar 18, 2021
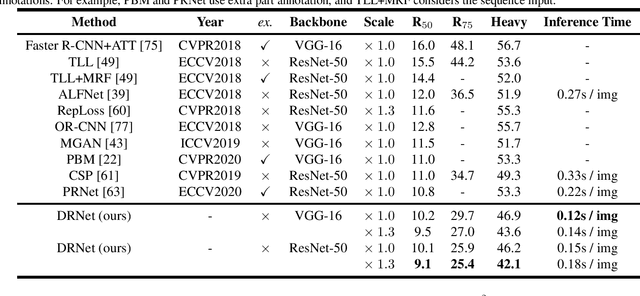
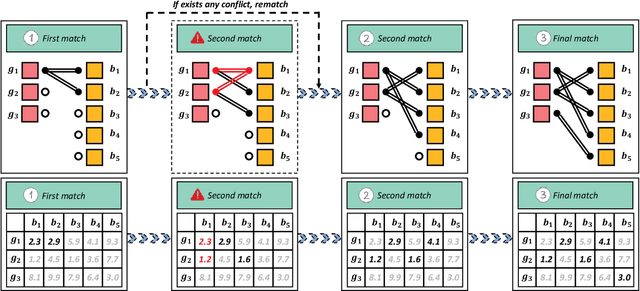

Accurate pedestrian classification and localization have received considerable attention due to their wide applications such as security monitoring, autonomous driving, etc. Although pedestrian detectors have made great progress in recent years, the fixed Intersection over Union (IoU) based assignment-regression manner still limits their performance. Two main factors are responsible for this: 1) the IoU threshold faces a dilemma that a lower one will result in more false positives, while a higher one will filter out the matched positives; 2) the IoU-based GT-Proposal assignment suffers from the inconsistent supervision problem that spatially adjacent proposals with similar features are assigned to different ground-truth boxes, which means some very similar proposals may be forced to regress towards different targets, and thus confuses the bounding-box regression when predicting the location results. In this paper, we first put forward the question that \textbf{Regression Direction} would affect the performance for pedestrian detection. Consequently, we address the weakness of IoU by introducing one geometric sensitive search algorithm as a new assignment and regression metric. Different from the previous IoU-based \textbf{one-to-one} assignment manner of one proposal to one ground-truth box, the proposed method attempts to seek a reasonable matching between the sets of proposals and ground-truth boxes. Specifically, we boost the MR-FPPI under R$_{75}$ by 8.8\% on Citypersons dataset. Furthermore, by incorporating this method as a metric into the state-of-the-art pedestrian detectors, we show a consistent improvement.
Where, What, Whether: Multi-modal Learning Meets Pedestrian Detection
Dec 20, 2020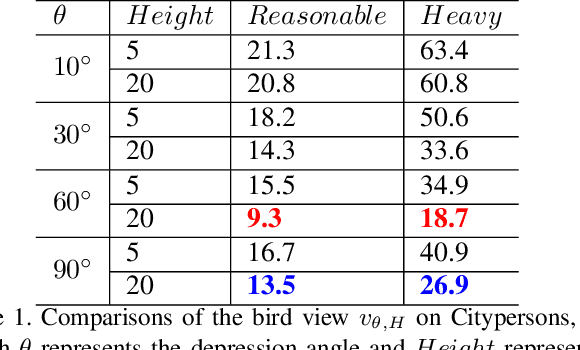
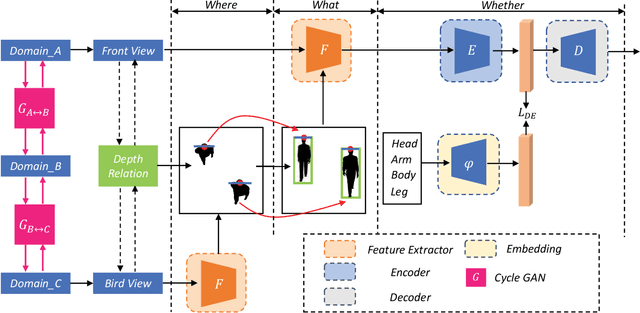
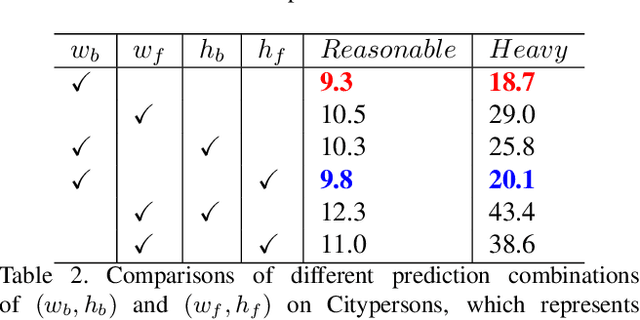
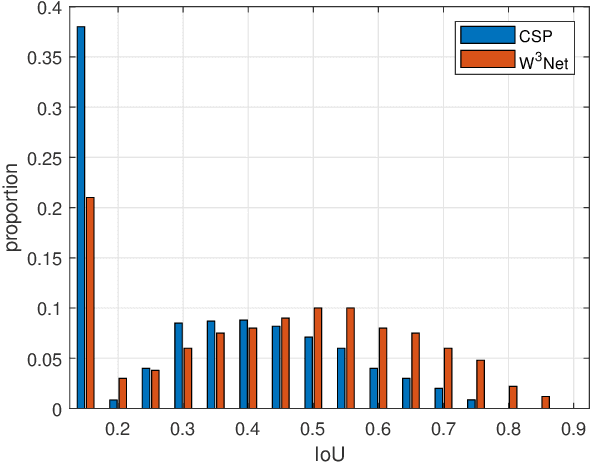
Pedestrian detection benefits greatly from deep convolutional neural networks (CNNs). However, it is inherently hard for CNNs to handle situations in the presence of occlusion and scale variation. In this paper, we propose W$^3$Net, which attempts to address above challenges by decomposing the pedestrian detection task into \textbf{\textit{W}}here, \textbf{\textit{W}}hat and \textbf{\textit{W}}hether problem directing against pedestrian localization, scale prediction and classification correspondingly. Specifically, for a pedestrian instance, we formulate its feature by three steps. i) We generate a bird view map, which is naturally free from occlusion issues, and scan all points on it to look for suitable locations for each pedestrian instance. ii) Instead of utilizing pre-fixed anchors, we model the interdependency between depth and scale aiming at generating depth-guided scales at different locations for better matching instances of different sizes. iii) We learn a latent vector shared by both visual and corpus space, by which false positives with similar vertical structure but lacking human partial features would be filtered out. We achieve state-of-the-art results on widely used datasets (Citypersons and Caltech). In particular. when evaluating on heavy occlusion subset, our results reduce MR$^{-2}$ from 49.3$\%$ to 18.7$\%$ on Citypersons, and from 45.18$\%$ to 28.33$\%$ on Caltech.
Locus: LiDAR-based Place Recognition using Spatiotemporal Higher-Order Pooling
Nov 30, 2020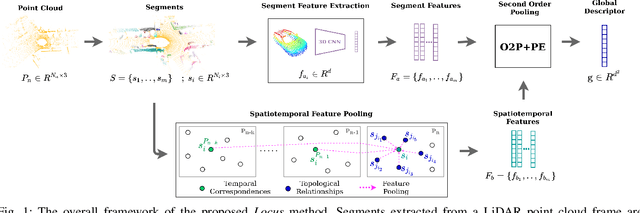
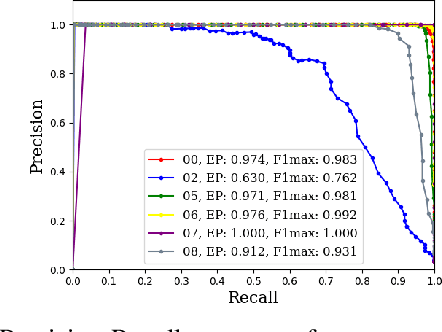
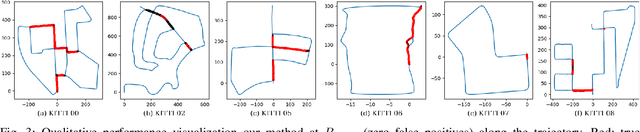
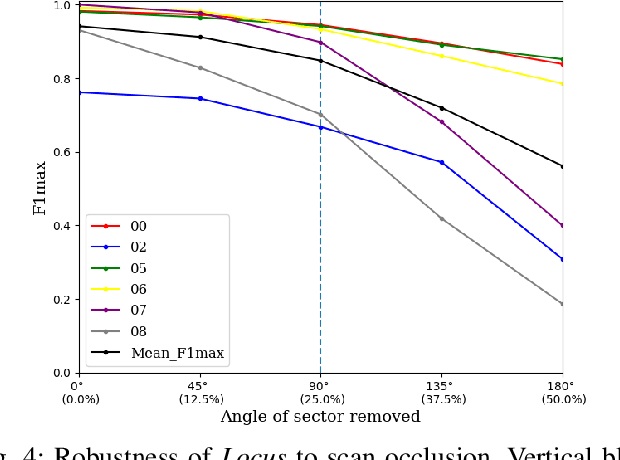
Place Recognition (PR) enables the estimation of a globally consistent map and trajectory by providing non-local constraints in Simultaneous Localisation and Mapping (SLAM). This paper presents Locus, a novel place recognition method using 3D LiDAR point clouds in large-scale environments. We propose a novel method for extracting and encoding topological and temporal information related to components in a scene and demonstrate how the inclusion of this auxiliary information in place description leads to more robust and discriminative scene representations. Second-order pooling along with a non-linear transform is used to aggregate these multi-level features to generate a fixed-length global descriptor, which is invariant to the permutation of input features. The proposed method outperforms state-of-the-art methods on the KITTI dataset. Furthermore, Locus is demonstrated to be robust across several challenging situations such as occlusions and viewpoint changes.
Towards Locally Consistent Object Counting with Constrained Multi-stage Convolutional Neural Networks
Apr 06, 2019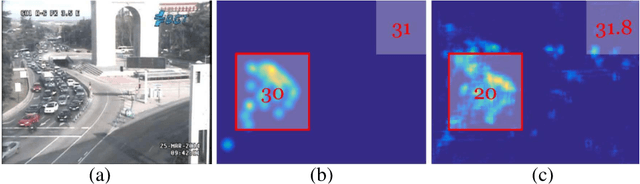
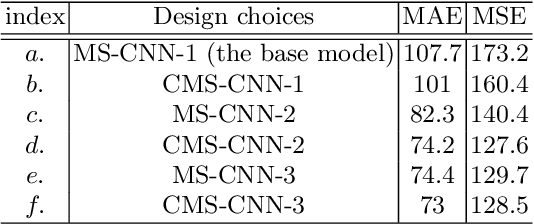
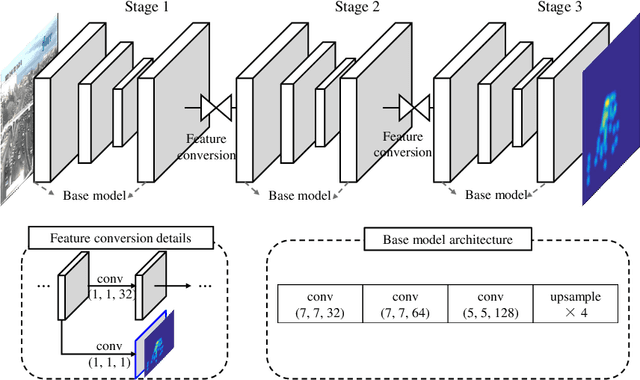
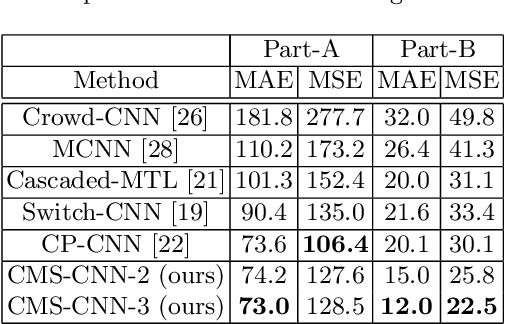
High-density object counting in surveillance scenes is challenging mainly due to the drastic variation of object scales. The prevalence of deep learning has largely boosted the object counting accuracy on several benchmark datasets. However, does the global counts really count? Armed with this question we dive into the predicted density map whose summation over the whole regions reports the global counts for more in-depth analysis. We observe that the object density map generated by most existing methods usually lacks of local consistency, i.e., counting errors in local regions exist unexpectedly even though the global count seems to well match with the ground-truth. Towards this problem, in this paper we propose a constrained multi-stage Convolutional Neural Networks (CNNs) to jointly pursue locally consistent density map from two aspects. Different from most existing methods that mainly rely on the multi-column architectures of plain CNNs, we exploit a stacking formulation of plain CNNs. Benefited from the internal multi-stage learning process, the feature map could be repeatedly refined, allowing the density map to approach the ground-truth density distribution. For further refinement of the density map, we also propose a grid loss function. With finer local-region-based supervisions, the underlying model is constrained to generate locally consistent density values to minimize the training errors considering both the global and local counts accuracy. Experiments on two widely-tested object counting benchmarks with overall significant results compared with state-of-the-art methods demonstrate the effectiveness of our approach.