 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildScenes: A Benchmark for 2D and 3D Semantic Segmentation in Large-scale Natural Environments
Dec 23, 2023



Recent progress in semantic scene understanding has primarily been enabled by the availability of semantically annotated bi-modal (camera and lidar) datasets in urban environments. However, such annotated datasets are also needed for natural, unstructured environments to enable semantic perception for applications, including conservation, search and rescue, environment monitoring, and agricultural automation. Therefore, we introduce WildScenes, a bi-modal benchmark dataset consisting of multiple large-scale traversals in natural environments, including semantic annotations in high-resolution 2D images and dense 3D lidar point clouds, and accurate 6-DoF pose information. The data is (1) trajectory-centric with accurate localization and globally aligned point clouds, (2) calibrated and synchronized to support bi-modal inference, and (3) containing different natural environments over 6 months to support research on domain adaptation. Our 3D semantic labels are obtained via an efficient automated process that transfers the human-annotated 2D labels from multiple views into 3D point clouds, thus circumventing the need for expensive and time-consuming human annotation in 3D. We introduce benchmarks on 2D and 3D semantic segmentation and evaluate a variety of recent deep-learning techniques to demonstrate the challenges in semantic segmentation in natural environments. We propose train-val-test splits for standard benchmarks as well as domain adaptation benchmarks and utilize an automated split generation technique to ensure the balance of class label distributions. The data, evaluation scripts and pretrained models will be released upon acceptance at https://csiro-robotics.github.io/WildScenes.
Multi-Body Neural Scene Flow
Oct 16, 2023



The test-time optimization of scene flow - using a coordinate network as a neural prior - has gained popularity due to its simplicity, lack of dataset bias, and state-of-the-art performance. We observe, however, that although coordinate networks capture general motions by implicitly regularizing the scene flow predictions to be spatially smooth, the neural prior by itself is unable to identify the underlying multi-body rigid motions present in real-world data. To address this, we show that multi-body rigidity can be achieved without the cumbersome and brittle strategy of constraining the $SE(3)$ parameters of each rigid body as done in previous works. This is achieved by regularizing the scene flow optimization to encourage isometry in flow predictions for rigid bodies. This strategy enables multi-body rigidity in scene flow while maintaining a continuous flow field, hence allowing dense long-term scene flow integration across a sequence of point clouds. We conduct extensive experiments on real-world datasets and demonstrate that our approach outperforms the state-of-the-art in 3D scene flow and long-term point-wise 4D trajectory prediction. The code is available at: \href{https://github.com/kavisha725/MBNSF}{https://github.com/kavisha725/MBNSF}.
Wild-Places: A Large-Scale Dataset for Lidar Place Recognition in Unstructured Natural Environments
Nov 29, 2022Many existing datasets for lidar place recognition are solely representative of structured urban environments, and have recently been saturated in performance by deep learning based approaches. Natural and unstructured environments present many additional challenges for the tasks of long-term localisation but these environments are not represented in currently available datasets. To address this we introduce Wild-Places, a challenging large-scale dataset for lidar place recognition in unstructured, natural environments. Wild-Places contains eight lidar sequences collected with a handheld sensor payload over the course of fourteen months, containing a total of 67K undistorted lidar submaps along with accurate 6DoF ground truth. Our dataset contains multiple revisits both within and between sequences, allowing for both intra-sequence (i.e. loop closure detection) and inter-sequence (i.e. re-localisation) place recognition. We also benchmark several state-of-the-art approaches to demonstrate the challenges that this dataset introduces, particularly the case of long-term place recognition due to natural environments changing over time. Our dataset and code will be available at https://csiro-robotics.github.io/Wild-Places.
Spectral Geometric Verification: Re-Ranking Point Cloud Retrieval for Metric Localization
Oct 10, 2022
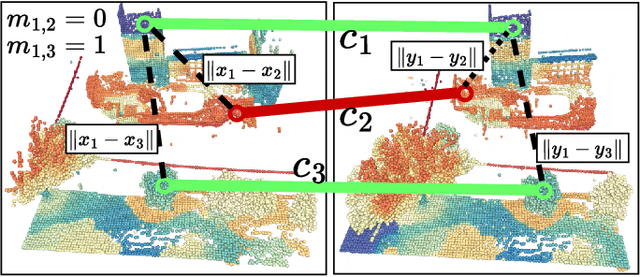
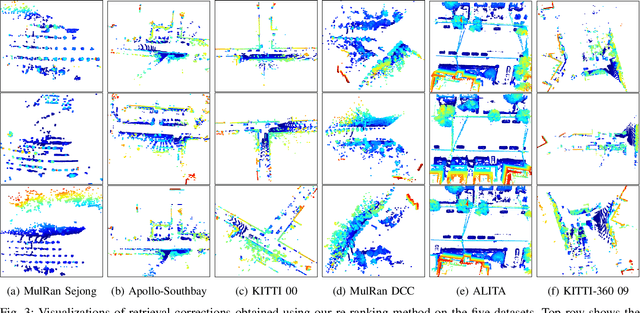
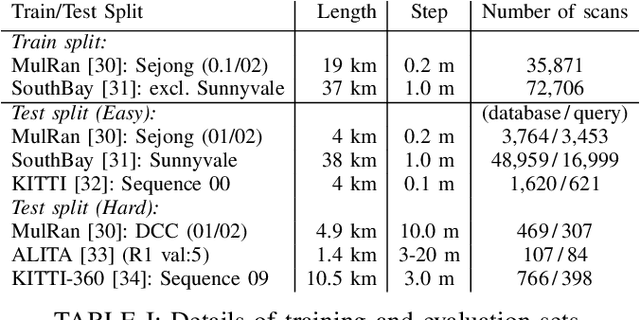
Although re-ranking methods are widely used in many retrieval tasks to improve performance, they haven't been studied in the context of point cloud retrieval for metric localization. In this letter, we introduce Spectral Geometric Verification (SpectralGV), for the re-ranking of retrieved point clouds. We demonstrate how the optimal inter-cluster score of the correspondence compatibility graph of two point clouds can be used as a robust fitness score representing their geometric compatibility, hence allowing geometric verification without registration. Compared to the baseline geometric verification based re-ranking methods which first register all retrieved point clouds with the query and then sort retrievals based on the inlier-ratio after registration, our method is considerably more efficient and provides a deterministic re-ranking solution while remaining robust to outliers. We demonstrate how our method boosts the performance of several correspondence-based architectures across 5 different large-scale point cloud datasets. We also achieve state-of-the-art results for both place recognition and metric-localization on these datasets. To the best of our knowledge, this letter is also the first to explore re-ranking in the point cloud retrieval domain for the task of metric localization. The open-source implementation will be made available at: https://github.com/csiro-robotics/SpectralGV.
LoGG3D-Net: Locally Guided Global Descriptor Learning for 3D Place Recognition
Sep 22, 2021
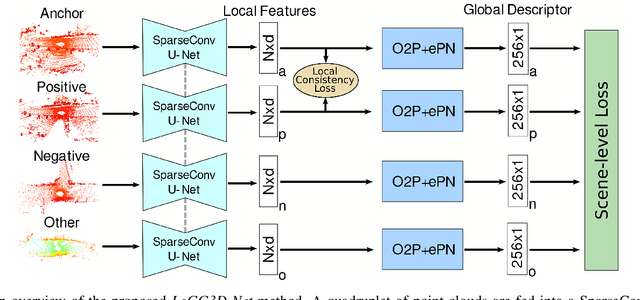
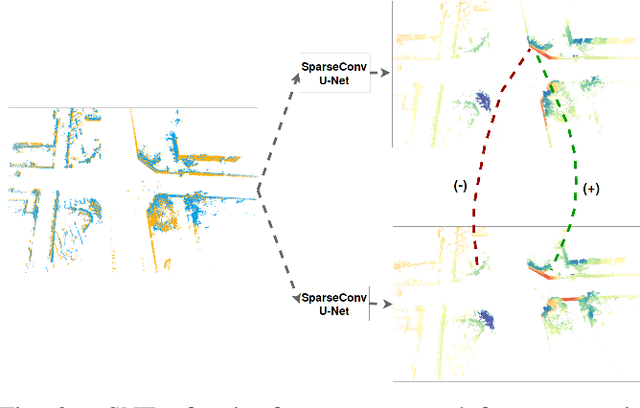
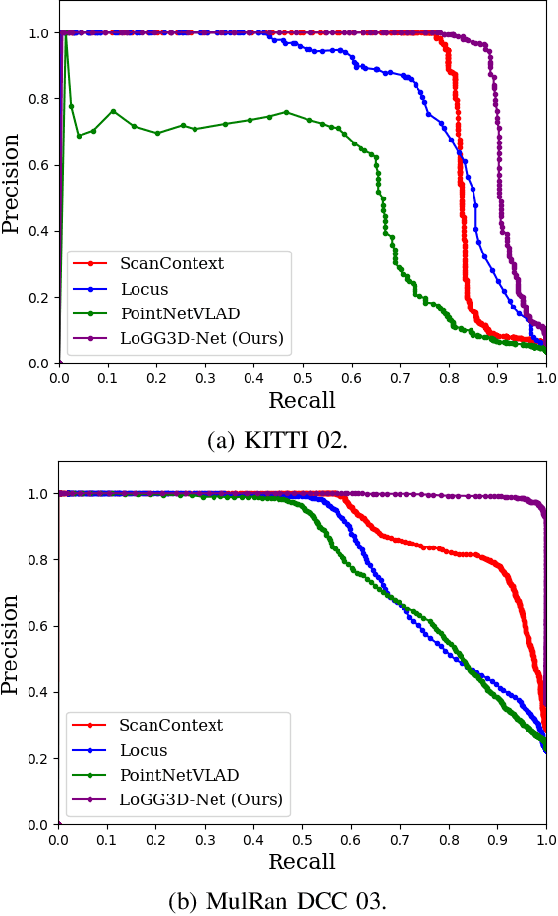
Retrieval-based place recognition is an efficient and effective solution for enabling re-localization within a pre-built map or global data association for Simultaneous Localization and Mapping (SLAM). The accuracy of such an approach is heavily dependent on the quality of the extracted scene-level representation. While end-to-end solutions, which learn a global descriptor from input point clouds, have demonstrated promising results, such approaches are limited in their ability to enforce desirable properties at the local feature level. In this paper, we demonstrate that the inclusion of an additional training signal (local consistency loss) can guide the network to learning local features which are consistent across revisits, hence leading to more repeatable global descriptors resulting in an overall improvement in place recognition performance. We formulate our approach in an end-to-end trainable architecture called LoGG3D-Net. Experiments on two large-scale public benchmarks (KITTI and MulRan) show that our method achieves mean $F1_{max}$ scores of $0.939$ and $0.968$ on KITTI and MulRan, respectively while operating in near real-time.
Locus: LiDAR-based Place Recognition using Spatiotemporal Higher-Order Pooling
Nov 30, 2020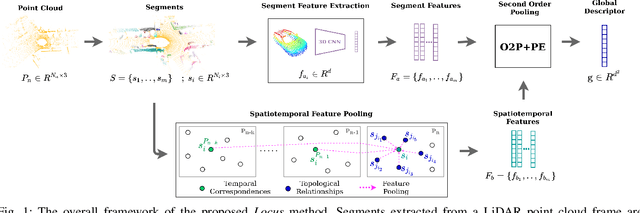
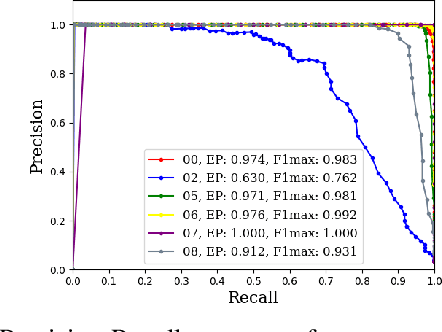
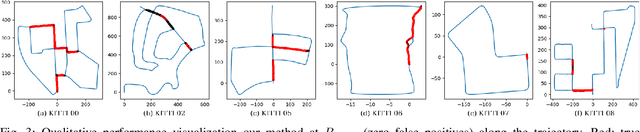
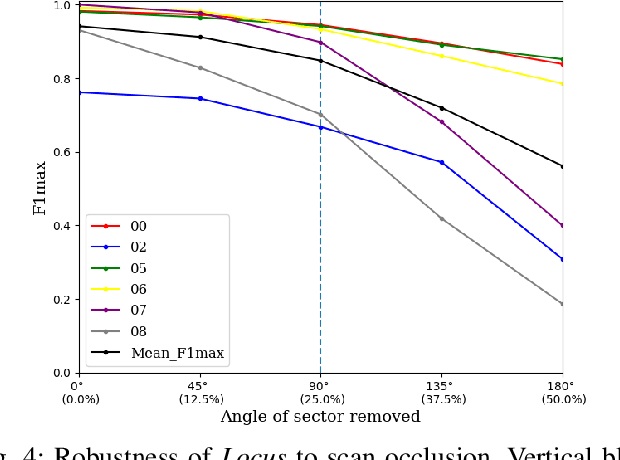
Place Recognition (PR) enables the estimation of a globally consistent map and trajectory by providing non-local constraints in Simultaneous Localisation and Mapping (SLAM). This paper presents Locus, a novel place recognition method using 3D LiDAR point clouds in large-scale environments. We propose a novel method for extracting and encoding topological and temporal information related to components in a scene and demonstrate how the inclusion of this auxiliary information in place description leads to more robust and discriminative scene representations. Second-order pooling along with a non-linear transform is used to aggregate these multi-level features to generate a fixed-length global descriptor, which is invariant to the permutation of input features. The proposed method outperforms state-of-the-art methods on the KITTI dataset. Furthermore, Locus is demonstrated to be robust across several challenging situations such as occlusions and viewpoint changes.