 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildScenes: A Benchmark for 2D and 3D Semantic Segmentation in Large-scale Natural Environments
Dec 23, 2023



Recent progress in semantic scene understanding has primarily been enabled by the availability of semantically annotated bi-modal (camera and lidar) datasets in urban environments. However, such annotated datasets are also needed for natural, unstructured environments to enable semantic perception for applications, including conservation, search and rescue, environment monitoring, and agricultural automation. Therefore, we introduce WildScenes, a bi-modal benchmark dataset consisting of multiple large-scale traversals in natural environments, including semantic annotations in high-resolution 2D images and dense 3D lidar point clouds, and accurate 6-DoF pose information. The data is (1) trajectory-centric with accurate localization and globally aligned point clouds, (2) calibrated and synchronized to support bi-modal inference, and (3) containing different natural environments over 6 months to support research on domain adaptation. Our 3D semantic labels are obtained via an efficient automated process that transfers the human-annotated 2D labels from multiple views into 3D point clouds, thus circumventing the need for expensive and time-consuming human annotation in 3D. We introduce benchmarks on 2D and 3D semantic segmentation and evaluate a variety of recent deep-learning techniques to demonstrate the challenges in semantic segmentation in natural environments. We propose train-val-test splits for standard benchmarks as well as domain adaptation benchmarks and utilize an automated split generation technique to ensure the balance of class label distributions. The data, evaluation scripts and pretrained models will be released upon acceptance at https://csiro-robotics.github.io/WildScenes.
Conifer Seedling Detection in UAV-Imagery with RGB-Depth Information
Nov 22, 2021
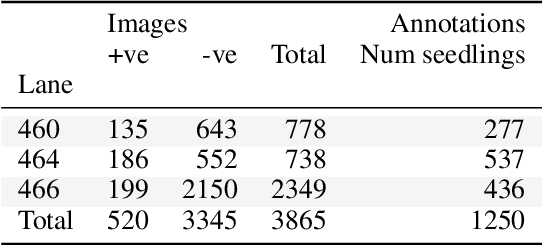
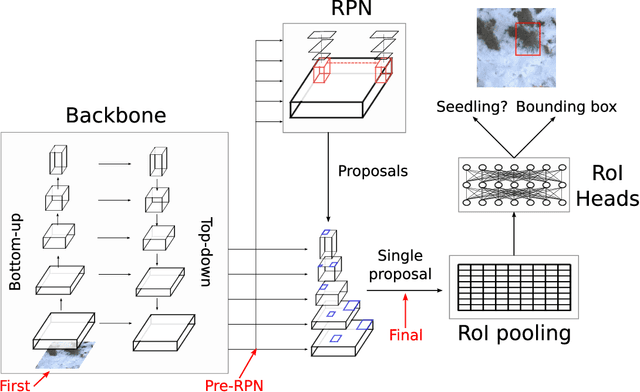
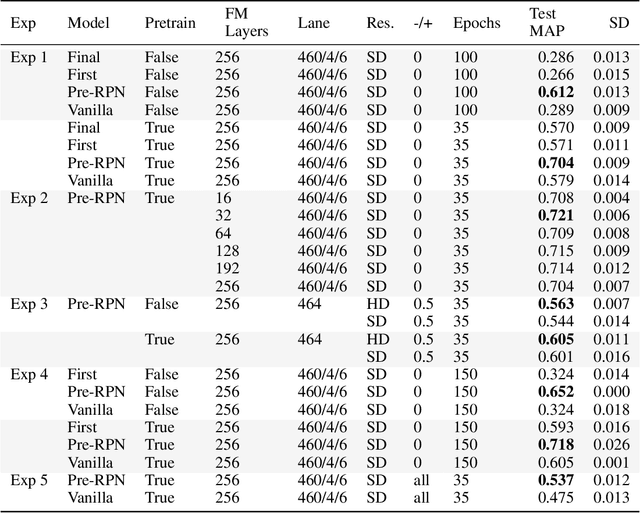
Monitoring of reforestation is currently being considerably streamlined through the use of drones and image recognition algorithms, which have already proven to be effective on colour imagery. In addition to colour imagery, elevation data is often also available. The primary aim of this work was to improve the performance of the faster-RCNN object detection algorithm by integrating this height information, which showed itself to notably improve performance. Interestingly, the structure of the network played a key role, with direct addition of the height information as a fourth image channel showing no improvement, while integration after the backbone network and before the region proposal network led to marked improvements. This effect persisted with very long training regimes. Increasing the resolution of this height information also showed little effect.