 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIlov3Splat: Instance-Level Open-Vocabulary 3D Scene Understanding in Gaussian Splatting
May 06, 2026We introduce Ilov3Splat, a novel framework for instance-level open-vocabulary 3D scene understanding built on 3D Gaussian Splatting (3D-GS). Most prior work depends on 2D rendering-based matching or point-level semantic association, which undermines cross-view consistency, lacks coherent instance-level reasoning, and limits precision in downstream 3D tasks. To address these limitations, our method jointly optimizes scene geometry and semantic representations by augmenting Gaussian splats with view-consistent feature fields. Specifically, we leverage multi-resolution hash embedding to efficiently encode language-aligned CLIP features, enabling dense and coherent language grounding in 3D space. We further train an instance feature field using contrastive loss over SAM masks, supporting fine-grained object distinction across views. At inference time, CLIP-encoded queries are matched against the learned features, followed by two-stage 3D clustering to retrieve relevant Gaussian groups. This enables our framework to identify arbitrary objects in 3D scenes based on natural language descriptions, without requiring category supervision or manual annotations. Experiments on standard benchmarks demonstrate that Ilov3Splat outperforms prior open-vocabulary 3D-GS methods in both object selection and instance segmentation, offering a flexible and accurate solution for language-driven 3D scene understanding. Project page: https://csiro-robotics.github.io/Ilov3Splat.
DIS2: Disentanglement Meets Distillation with Classwise Attention for Robust Remote Sensing Segmentation under Missing Modalities
Jan 20, 2026The efficacy of multimodal learning in remote sensing (RS) is severely undermined by missing modalities. The challenge is exacerbated by the RS highly heterogeneous data and huge scale variation. Consequently, paradigms proven effective in other domains often fail when confronted with these unique data characteristics. Conventional disentanglement learning, which relies on significant feature overlap between modalities (modality-invariant), is insufficient for this heterogeneity. Similarly, knowledge distillation becomes an ill-posed mimicry task where a student fails to focus on the necessary compensatory knowledge, leaving the semantic gap unaddressed. Our work is therefore built upon three pillars uniquely designed for RS: (1) principled missing information compensation, (2) class-specific modality contribution, and (3) multi-resolution feature importance. We propose a novel method DIS2, a new paradigm shifting from modality-shared feature dependence and untargeted imitation to active, guided missing features compensation. Its core novelty lies in a reformulated synergy between disentanglement learning and knowledge distillation, termed DLKD. Compensatory features are explicitly captured which, when fused with the features of the available modality, approximate the ideal fused representation of the full-modality case. To address the class-specific challenge, our Classwise Feature Learning Module (CFLM) adaptively learn discriminative evidence for each target depending on signal availability. Both DLKD and CFLM are supported by a hierarchical hybrid fusion (HF) structure using features across resolutions to strengthen prediction. Extensive experiments validate that our proposed approach significantly outperforms state-of-the-art methods across benchmarks.
DeepForgeSeal: Latent Space-Driven Semi-Fragile Watermarking for Deepfake Detection Using Multi-Agent Adversarial Reinforcement Learning
Nov 07, 2025Rapid advances in generative AI have led to increasingly realistic deepfakes, posing growing challenges for law enforcement and public trust. Existing passive deepfake detectors struggle to keep pace, largely due to their dependence on specific forgery artifacts, which limits their ability to generalize to new deepfake types. Proactive deepfake detection using watermarks has emerged to address the challenge of identifying high-quality synthetic media. However, these methods often struggle to balance robustness against benign distortions with sensitivity to malicious tampering. This paper introduces a novel deep learning framework that harnesses high-dimensional latent space representations and the Multi-Agent Adversarial Reinforcement Learning (MAARL) paradigm to develop a robust and adaptive watermarking approach. Specifically, we develop a learnable watermark embedder that operates in the latent space, capturing high-level image semantics, while offering precise control over message encoding and extraction. The MAARL paradigm empowers the learnable watermarking agent to pursue an optimal balance between robustness and fragility by interacting with a dynamic curriculum of benign and malicious image manipulations simulated by an adversarial attacker agent. Comprehensive evaluations on the CelebA and CelebA-HQ benchmarks reveal that our method consistently outperforms state-of-the-art approaches, achieving improvements of over 4.5% on CelebA and more than 5.3% on CelebA-HQ under challenging manipulation scenarios.
AG-VPReID.VIR: Bridging Aerial and Ground Platforms for Video-based Visible-Infrared Person Re-ID
Jul 24, 2025Person re-identification (Re-ID) across visible and infrared modalities is crucial for 24-hour surveillance systems, but existing datasets primarily focus on ground-level perspectives. While ground-based IR systems offer nighttime capabilities, they suffer from occlusions, limited coverage, and vulnerability to obstructions--problems that aerial perspectives uniquely solve. To address these limitations, we introduce AG-VPReID.VIR, the first aerial-ground cross-modality video-based person Re-ID dataset. This dataset captures 1,837 identities across 4,861 tracklets (124,855 frames) using both UAV-mounted and fixed CCTV cameras in RGB and infrared modalities. AG-VPReID.VIR presents unique challenges including cross-viewpoint variations, modality discrepancies, and temporal dynamics. Additionally, we propose TCC-VPReID, a novel three-stream architecture designed to address the joint challenges of cross-platform and cross-modality person Re-ID. Our approach bridges the domain gaps between aerial-ground perspectives and RGB-IR modalities, through style-robust feature learning, memory-based cross-view adaptation, and intermediary-guided temporal modeling. Experiments show that AG-VPReID.VIR presents distinctive challenges compared to existing datasets, with our TCC-VPReID framework achieving significant performance gains across multiple evaluation protocols. Dataset and code are available at https://github.com/agvpreid25/AG-VPReID.VIR.
Cross-Branch Orthogonality for Improved Generalization in Face Deepfake Detection
May 08, 2025



Remarkable advancements in generative AI technology have given rise to a spectrum of novel deepfake categories with unprecedented leaps in their realism, and deepfakes are increasingly becoming a nuisance to law enforcement authorities and the general public. In particular, we observe alarming levels of confusion, deception, and loss of faith regarding multimedia content within society caused by face deepfakes, and existing deepfake detectors are struggling to keep up with the pace of improvements in deepfake generation. This is primarily due to their reliance on specific forgery artifacts, which limits their ability to generalise and detect novel deepfake types. To combat the spread of malicious face deepfakes, this paper proposes a new strategy that leverages coarse-to-fine spatial information, semantic information, and their interactions while ensuring feature distinctiveness and reducing the redundancy of the modelled features. A novel feature orthogonality-based disentanglement strategy is introduced to ensure branch-level and cross-branch feature disentanglement, which allows us to integrate multiple feature vectors without adding complexity to the feature space or compromising generalisation. Comprehensive experiments on three public benchmarks: FaceForensics++, Celeb-DF, and the Deepfake Detection Challenge (DFDC) show that these design choices enable the proposed approach to outperform current state-of-the-art methods by 5% on the Celeb-DF dataset and 7% on the DFDC dataset in a cross-dataset evaluation setting.
Dual-Domain Masked Image Modeling: A Self-Supervised Pretraining Strategy Using Spatial and Frequency Domain Masking for Hyperspectral Data
May 06, 2025

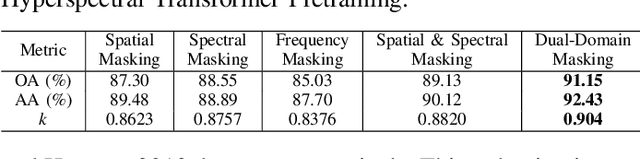
Hyperspectral images (HSIs) capture rich spectral signatures that reveal vital material properties, offering broad applicability across various domains. However, the scarcity of labeled HSI data limits the full potential of deep learning, especially for transformer-based architectures that require large-scale training. To address this constraint, we propose Spatial-Frequency Masked Image Modeling (SFMIM), a self-supervised pretraining strategy for hyperspectral data that utilizes the large portion of unlabeled data. Our method introduces a novel dual-domain masking mechanism that operates in both spatial and frequency domains. The input HSI cube is initially divided into non-overlapping patches along the spatial dimension, with each patch comprising the entire spectrum of its corresponding spatial location. In spatial masking, we randomly mask selected patches and train the model to reconstruct the masked inputs using the visible patches. Concurrently, in frequency masking, we remove portions of the frequency components of the input spectra and predict the missing frequencies. By learning to reconstruct these masked components, the transformer-based encoder captures higher-order spectral-spatial correlations. We evaluate our approach on three publicly available HSI classification benchmarks and demonstrate that it achieves state-of-the-art performance. Notably, our model shows rapid convergence during fine-tuning, highlighting the efficiency of our pretraining strategy.
AG-VPReID: A Challenging Large-Scale Benchmark for Aerial-Ground Video-based Person Re-Identification
Mar 11, 2025We introduce AG-VPReID, a challenging large-scale benchmark dataset for aerial-ground video-based person re-identification (ReID), comprising 6,632 identities, 32,321 tracklets, and 9.6 million frames captured from drones (15-120m altitude), CCTV, and wearable cameras. This dataset presents a real-world benchmark to investigate the robustness of Person ReID approaches against the unique challenges of cross-platform aerial-ground settings. To address these challenges, we propose AG-VPReID-Net, an end-to-end framework combining three complementary streams: (1) an Adapted Temporal-Spatial Stream addressing motion pattern inconsistencies and temporal feature learning, (2) a Normalized Appearance Stream using physics-informed techniques to tackle resolution and appearance changes, and (3) a Multi-Scale Attention Stream handling scale variations across drone altitudes. Our approach integrates complementary visual-semantic information from all streams to generate robust, viewpoint-invariant person representations. Extensive experiments demonstrate that AG-VPReID-Net outperforms state-of-the-art approaches on both our new dataset and other existing video-based ReID benchmarks, showcasing its effectiveness and generalizability. The relatively lower performance of all state-of-the-art approaches, including our proposed approach, on our new dataset highlights its challenging nature. The AG-VPReID dataset, code and models are available at https://github.com/agvpreid25/AG-VPReID-Net.
Spectral-Enhanced Transformers: Leveraging Large-Scale Pretrained Models for Hyperspectral Object Tracking
Feb 26, 2025



Hyperspectral object tracking using snapshot mosaic cameras is emerging as it provides enhanced spectral information alongside spatial data, contributing to a more comprehensive understanding of material properties. Using transformers, which have consistently outperformed convolutional neural networks (CNNs) in learning better feature representations, would be expected to be effective for Hyperspectral object tracking. However, training large transformers necessitates extensive datasets and prolonged training periods. This is particularly critical for complex tasks like object tracking, and the scarcity of large datasets in the hyperspectral domain acts as a bottleneck in achieving the full potential of powerful transformer models. This paper proposes an effective methodology that adapts large pretrained transformer-based foundation models for hyperspectral object tracking. We propose an adaptive, learnable spatial-spectral token fusion module that can be extended to any transformer-based backbone for learning inherent spatial-spectral features in hyperspectral data. Furthermore, our model incorporates a cross-modality training pipeline that facilitates effective learning across hyperspectral datasets collected with different sensor modalities. This enables the extraction of complementary knowledge from additional modalities, whether or not they are present during testing. Our proposed model also achieves superior performance with minimal training iterations.
Damage Assessment after Natural Disasters with UAVs: Semantic Feature Extraction using Deep Learning
Dec 14, 2024



Unmanned aerial vehicle-assisted disaster recovery missions have been promoted recently due to their reliability and flexibility. Machine learning algorithms running onboard significantly enhance the utility of UAVs by enabling real-time data processing and efficient decision-making, despite being in a resource-constrained environment. However, the limited bandwidth and intermittent connectivity make transmitting the outputs to ground stations challenging. This paper proposes a novel semantic extractor that can be adopted into any machine learning downstream task for identifying the critical data required for decision-making. The semantic extractor can be executed onboard which results in a reduction of data that needs to be transmitted to ground stations. We test the proposed architecture together with the semantic extractor on two publicly available datasets, FloodNet and RescueNet, for two downstream tasks: visual question answering and disaster damage level classification. Our experimental results demonstrate the proposed method maintains high accuracy across different downstream tasks while significantly reducing the volume of transmitted data, highlighting the effectiveness of our semantic extractor in capturing task-specific salient information.
Physics Augmented Tuple Transformer for Autism Severity Level Detection
Sep 27, 2024



Early diagnosis of Autism Spectrum Disorder (ASD) is an effective and favorable step towards enhancing the health and well-being of children with ASD. Manual ASD diagnosis testing is labor-intensive, complex, and prone to human error due to several factors contaminating the results. This paper proposes a novel framework that exploits the laws of physics for ASD severity recognition. The proposed physics-informed neural network architecture encodes the behaviour of the subject extracted by observing a part of the skeleton-based motion trajectory in a higher dimensional latent space. Two decoders, namely physics-based and non-physics-based decoder, use this latent embedding and predict the future motion patterns. The physics branch leverages the laws of physics that apply to a skeleton sequence in the prediction process while the non-physics-based branch is optimised to minimise the difference between the predicted and actual motion of the subject. A classifier also leverages the same latent space embeddings to recognise the ASD severity. This dual generative objective explicitly forces the network to compare the actual behaviour of the subject with the general normal behaviour of children that are governed by the laws of physics, aiding the ASD recognition task. The proposed method attains state-of-the-art performance on multiple ASD diagnosis benchmarks. To illustrate the utility of the proposed framework beyond the task ASD diagnosis, we conduct a third experiment using a publicly available benchmark for the task of fall prediction and demonstrate the superiority of our model.