 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomechanically Accurate Gait Analysis: A 3d Human Reconstruction Framework for Markerless Estimation of Gait Parameters
Mar 03, 2026This paper presents a biomechanically interpretable framework for gait analysis using 3D human reconstruction from video data. Unlike conventional keypoint based approaches, the proposed method extracts biomechanically meaningful markers analogous to motion capture systems and integrates them within OpenSim for joint kinematic estimation. To evaluate performance, both spatiotemporal and kinematic gait parameters were analysed against reference marker-based data. Results indicate strong agreement with marker-based measurements, with considerable improvements when compared with pose-estimation methods alone. The proposed framework offers a scalable, markerless, and interpretable approach for accurate gait assessment, supporting broader clinical and real world deployment of vision based biomechanics
AG-VPReID.VIR: Bridging Aerial and Ground Platforms for Video-based Visible-Infrared Person Re-ID
Jul 24, 2025Person re-identification (Re-ID) across visible and infrared modalities is crucial for 24-hour surveillance systems, but existing datasets primarily focus on ground-level perspectives. While ground-based IR systems offer nighttime capabilities, they suffer from occlusions, limited coverage, and vulnerability to obstructions--problems that aerial perspectives uniquely solve. To address these limitations, we introduce AG-VPReID.VIR, the first aerial-ground cross-modality video-based person Re-ID dataset. This dataset captures 1,837 identities across 4,861 tracklets (124,855 frames) using both UAV-mounted and fixed CCTV cameras in RGB and infrared modalities. AG-VPReID.VIR presents unique challenges including cross-viewpoint variations, modality discrepancies, and temporal dynamics. Additionally, we propose TCC-VPReID, a novel three-stream architecture designed to address the joint challenges of cross-platform and cross-modality person Re-ID. Our approach bridges the domain gaps between aerial-ground perspectives and RGB-IR modalities, through style-robust feature learning, memory-based cross-view adaptation, and intermediary-guided temporal modeling. Experiments show that AG-VPReID.VIR presents distinctive challenges compared to existing datasets, with our TCC-VPReID framework achieving significant performance gains across multiple evaluation protocols. Dataset and code are available at https://github.com/agvpreid25/AG-VPReID.VIR.
AG-VPReID: A Challenging Large-Scale Benchmark for Aerial-Ground Video-based Person Re-Identification
Mar 11, 2025We introduce AG-VPReID, a challenging large-scale benchmark dataset for aerial-ground video-based person re-identification (ReID), comprising 6,632 identities, 32,321 tracklets, and 9.6 million frames captured from drones (15-120m altitude), CCTV, and wearable cameras. This dataset presents a real-world benchmark to investigate the robustness of Person ReID approaches against the unique challenges of cross-platform aerial-ground settings. To address these challenges, we propose AG-VPReID-Net, an end-to-end framework combining three complementary streams: (1) an Adapted Temporal-Spatial Stream addressing motion pattern inconsistencies and temporal feature learning, (2) a Normalized Appearance Stream using physics-informed techniques to tackle resolution and appearance changes, and (3) a Multi-Scale Attention Stream handling scale variations across drone altitudes. Our approach integrates complementary visual-semantic information from all streams to generate robust, viewpoint-invariant person representations. Extensive experiments demonstrate that AG-VPReID-Net outperforms state-of-the-art approaches on both our new dataset and other existing video-based ReID benchmarks, showcasing its effectiveness and generalizability. The relatively lower performance of all state-of-the-art approaches, including our proposed approach, on our new dataset highlights its challenging nature. The AG-VPReID dataset, code and models are available at https://github.com/agvpreid25/AG-VPReID-Net.
Radar Signal Recognition through Self-Supervised Learning and Domain Adaptation
Jan 07, 2025



Automatic radar signal recognition (RSR) plays a pivotal role in electronic warfare (EW), as accurately classifying radar signals is critical for informing decision-making processes. Recent advances in deep learning have shown significant potential in improving RSR performance in domains with ample annotated data. However, these methods fall short in EW scenarios where annotated RF data are scarce or impractical to obtain. To address these challenges, we introduce a self-supervised learning (SSL) method which utilises masked signal modelling and RF domain adaption to enhance RSR performance in environments with limited RF samples and labels. Specifically, we investigate pre-training masked autoencoders (MAE) on baseband in-phase and quadrature (I/Q) signals from various RF domains and subsequently transfer the learned representation to the radar domain, where annotated data are limited. Empirical results show that our lightweight self-supervised ResNet model with domain adaptation achieves up to a 17.5\% improvement in 1-shot classification accuracy when pre-trained on in-domain signals (i.e., radar signals) and up to a 16.31\% improvement when pre-trained on out-of-domain signals (i.e., comm signals), compared to its baseline without SSL. We also provide reference results for several MAE designs and pre-training strategies, establishing a new benchmark for few-shot radar signal classification.
Efficient Position Determination of Highly Directional RF Emitters via Iterated Beampattern Analysis
Nov 07, 2024Received signal strength (RSS) information has seldom been incorporated in the direct position determination (DPD) method of passive radio emitter localization to date. Further, the common use of directional emitters modulates the RSS such that omnidirectional assumptions would dramatically decrease accuracy. This paper introduces a new DPD approach utilizing an RSS- enhanced adaptive beamforming method demonstrating on par or better than state-of-the-art performance at very low SNR for omnidirectional emitters. The technique is then applied to directional emitters taking the imposed RSS modulation into account using a beampattern library, significantly improving localization region confidence as compared to omnidirectional assumption approaches. This is the first approach to date in the open literature for localizing directional emitters.
Automatic Radar Signal Detection and FFT Estimation using Deep Learning
Feb 29, 2024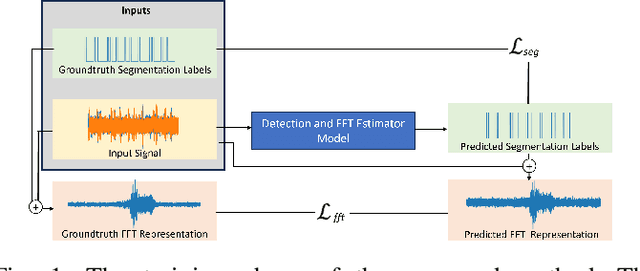

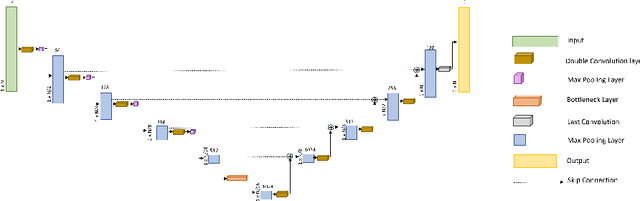
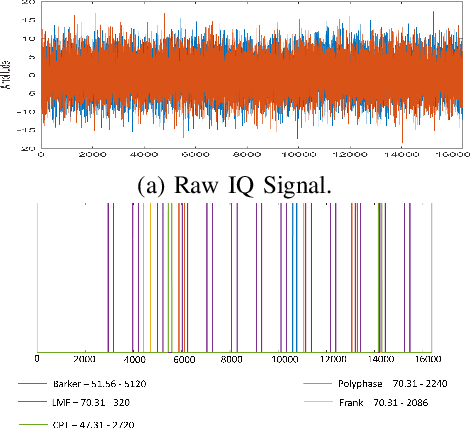
This paper addresses a critical preliminary step in radar signal processing: detecting the presence of a radar signal and robustly estimating its bandwidth. Existing methods which are largely statistical feature-based approaches face challenges in electronic warfare (EW) settings where prior information about signals is lacking. While alternate deep learning based methods focus on more challenging environments, they primarily formulate this as a binary classification problem. In this research, we propose a novel methodology that not only detects the presence of a signal, but also localises it in the time domain and estimates its operating frequency band at that point in time. To achieve robust estimation, we introduce a compound loss function that leverages complementary information from both time-domain and frequency-domain representations. By integrating these approaches, we aim to improve the efficiency and accuracy of radar signal detection and parameter estimation, reducing both unnecessary resource consumption and human effort in downstream tasks.
Multi-stage Learning for Radar Pulse Activity Segmentation
Dec 15, 2023



Radio signal recognition is a crucial function in electronic warfare. Precise identification and localisation of radar pulse activities are required by electronic warfare systems to produce effective countermeasures. Despite the importance of these tasks, deep learning-based radar pulse activity recognition methods have remained largely underexplored. While deep learning for radar modulation recognition has been explored previously, classification tasks are generally limited to short and non-interleaved IQ signals, limiting their applicability to military applications. To address this gap, we introduce an end-to-end multi-stage learning approach to detect and localise pulse activities of interleaved radar signals across an extended time horizon. We propose a simple, yet highly effective multi-stage architecture for incrementally predicting fine-grained segmentation masks that localise radar pulse activities across multiple channels. We demonstrate the performance of our approach against several reference models on a novel radar dataset, while also providing a first-of-its-kind benchmark for radar pulse activity segmentation.
Multi-task Learning for Radar Signal Characterisation
Jun 19, 2023



Radio signal recognition is a crucial task in both civilian and military applications, as accurate and timely identification of unknown signals is an essential part of spectrum management and electronic warfare. The majority of research in this field has focused on applying deep learning for modulation classification, leaving the task of signal characterisation as an understudied area. This paper addresses this gap by presenting an approach for tackling radar signal classification and characterisation as a multi-task learning (MTL) problem. We propose the IQ Signal Transformer (IQST) among several reference architectures that allow for simultaneous optimisation of multiple regression and classification tasks. We demonstrate the performance of our proposed MTL model on a synthetic radar dataset, while also providing a first-of-its-kind benchmark for radar signal characterisation.
Privacy-Preserving In-Bed Pose Monitoring: A Fusion and Reconstruction Study
Feb 22, 2022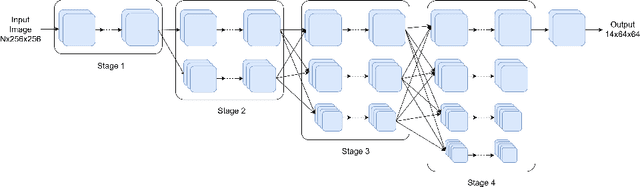

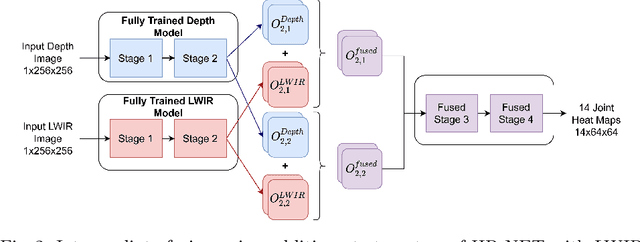
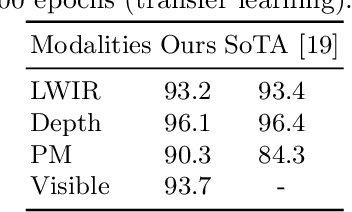
Recently, in-bed human pose estimation has attracted the interest of researchers due to its relevance to a wide range of healthcare applications. Compared to the general problem of human pose estimation, in-bed pose estimation has several inherent challenges, the most prominent being frequent and severe occlusions caused by bedding. In this paper we explore the effective use of images from multiple non-visual and privacy-preserving modalities such as depth, long-wave infrared (LWIR) and pressure maps for the task of in-bed pose estimation in two settings. First, we explore the effective fusion of information from different imaging modalities for better pose estimation. Secondly, we propose a framework that can estimate in-bed pose estimation when visible images are unavailable, and demonstrate the applicability of fusion methods to scenarios where only LWIR images are available. We analyze and demonstrate the effect of fusing features from multiple modalities. For this purpose, we consider four different techniques: 1) Addition, 2) Concatenation, 3) Fusion via learned modal weights, and 4) End-to-end fully trainable approach; with a state-of-the-art pose estimation model. We also evaluate the effect of reconstructing a data-rich modality (i.e., visible modality) from a privacy-preserving modality with data scarcity (i.e., long-wavelength infrared) for in-bed human pose estimation. For reconstruction, we use a conditional generative adversarial network. We conduct ablative studies across different design decisions of our framework. This includes selecting features with different levels of granularity, using different fusion techniques, and varying model parameters. Through extensive evaluations, we demonstrate that our method produces on par or better results compared to the state-of-the-art.
Im2Mesh GAN: Accurate 3D Hand Mesh Recovery from a Single RGB Image
Jan 27, 2021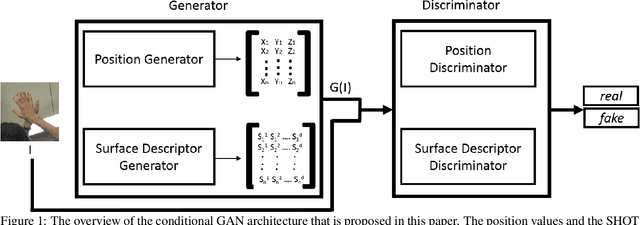
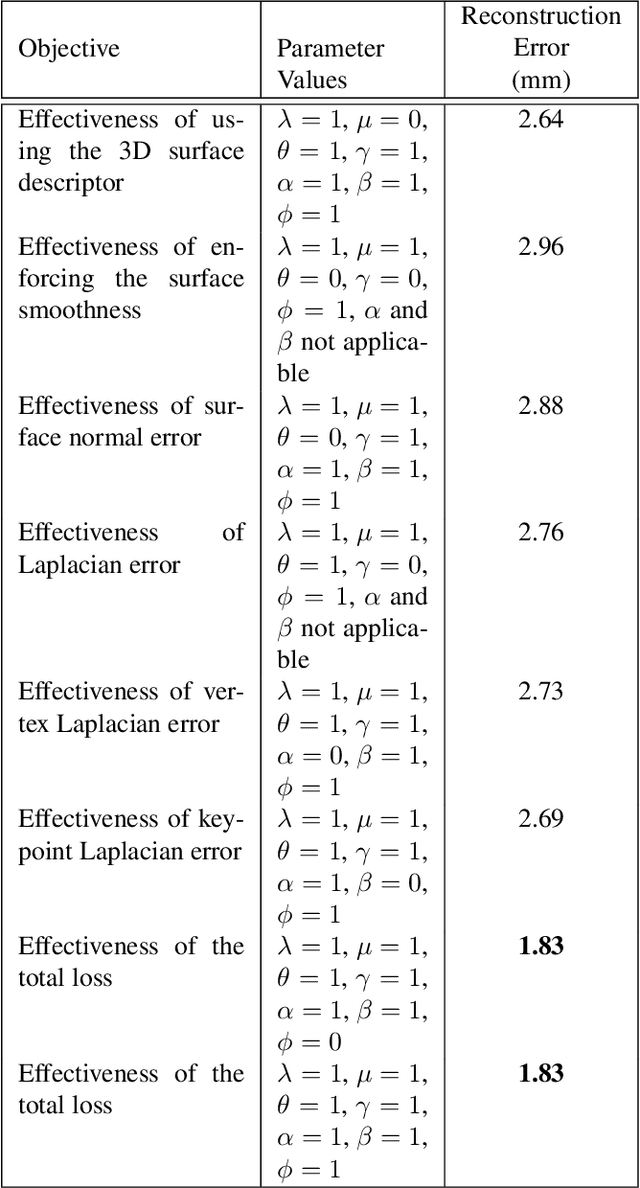
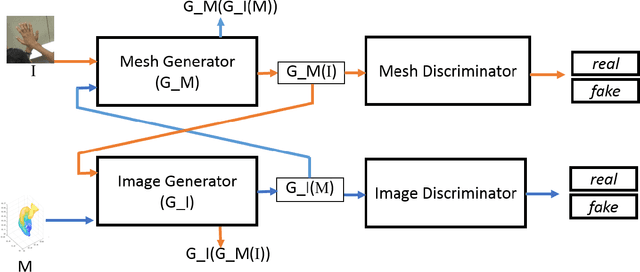

This work addresses hand mesh recovery from a single RGB image. In contrast to most of the existing approaches where the parametric hand models are employed as the prior, we show that the hand mesh can be learned directly from the input image. We propose a new type of GAN called Im2Mesh GAN to learn the mesh through end-to-end adversarial training. By interpreting the mesh as a graph, our model is able to capture the topological relationship among the mesh vertices. We also introduce a 3D surface descriptor into the GAN architecture to further capture the 3D features associated. We experiment two approaches where one can reap the benefits of coupled groundtruth data availability of images and the corresponding meshes, while the other combats the more challenging problem of mesh estimations without the corresponding groundtruth. Through extensive evaluations we demonstrate that the proposed method outperforms the state-of-the-art.