 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Multinomial Logistic Mixture of Experts with Sigmoid Gating Function
Feb 01, 2026The sigmoid gate in mixture-of-experts (MoE) models has been empirically shown to outperform the softmax gate across several tasks, ranging from approximating feed-forward networks to language modeling. Additionally, recent efforts have demonstrated that the sigmoid gate is provably more sample-efficient than its softmax counterpart under regression settings. Nevertheless, there are three notable concerns that have not been addressed in the literature, namely (i) the benefits of the sigmoid gate have not been established under classification settings; (ii) existing sigmoid-gated MoE models may not converge to their ground-truth; and (iii) the effects of a temperature parameter in the sigmoid gate remain theoretically underexplored. To tackle these open problems, we perform a comprehensive analysis of multinomial logistic MoE equipped with a modified sigmoid gate to ensure model convergence. Our results indicate that the sigmoid gate exhibits a lower sample complexity than the softmax gate for both parameter and expert estimation. Furthermore, we find that incorporating a temperature into the sigmoid gate leads to a sample complexity of exponential order due to an intrinsic interaction between the temperature and gating parameters. To overcome this issue, we propose replacing the vanilla inner product score in the gating function with a Euclidean score that effectively removes that interaction, thereby substantially improving the sample complexity to a polynomial order.
A Statistical Theory of Gated Attention through the Lens of Hierarchical Mixture of Experts
Feb 01, 2026Self-attention has greatly contributed to the success of the widely used Transformer architecture by enabling learning from data with long-range dependencies. In an effort to improve performance, a gated attention model that leverages a gating mechanism within the multi-head self-attention has recently been proposed as a promising alternative. Gated attention has been empirically demonstrated to increase the expressiveness of low-rank mapping in standard attention and even to eliminate the attention sink phenomenon. Despite its efficacy, a clear theoretical understanding of gated attention's benefits remains lacking in the literature. To close this gap, we rigorously show that each entry in a gated attention matrix or a multi-head self-attention matrix can be written as a hierarchical mixture of experts. By recasting learning as an expert estimation problem, we demonstrate that gated attention is more sample-efficient than multi-head self-attention. In particular, while the former needs only a polynomial number of data points to estimate an expert, the latter requires exponentially many data points to achieve the same estimation error. Furthermore, our analysis also provides a theoretical justification for why gated attention yields higher performance when a gate is placed at the output of the scaled dot product attention or the value map rather than at other positions in the multi-head self-attention architecture.
Improving Minimax Estimation Rates for Contaminated Mixture of Multinomial Logistic Experts via Expert Heterogeneity
Jan 31, 2026Contaminated mixture of experts (MoE) is motivated by transfer learning methods where a pre-trained model, acting as a frozen expert, is integrated with an adapter model, functioning as a trainable expert, in order to learn a new task. Despite recent efforts to analyze the convergence behavior of parameter estimation in this model, there are still two unresolved problems in the literature. First, the contaminated MoE model has been studied solely in regression settings, while its theoretical foundation in classification settings remains absent. Second, previous works on MoE models for classification capture pointwise convergence rates for parameter estimation without any guaranty of minimax optimality. In this work, we close these gaps by performing, for the first time, the convergence analysis of a contaminated mixture of multinomial logistic experts with homogeneous and heterogeneous structures, respectively. In each regime, we characterize uniform convergence rates for estimating parameters under challenging settings where ground-truth parameters vary with the sample size. Furthermore, we also establish corresponding minimax lower bounds to ensure that these rates are minimax optimal. Notably, our theories offer an important insight into the design of contaminated MoE, that is, expert heterogeneity yields faster parameter estimation rates and, therefore, is more sample-efficient than expert homogeneity.
Cite-While-You-Generate: Training-Free Evidence Attribution for Multimodal Clinical Summarization
Jan 23, 2026Trustworthy clinical summarization requires not only fluent generation but also transparency about where each statement comes from. We propose a training-free framework for generation-time source attribution that leverages decoder attentions to directly cite supporting text spans or images, overcoming the limitations of post-hoc or retraining-based methods. We introduce two strategies for multimodal attribution: a raw image mode, which directly uses image patch attentions, and a caption-as-span mode, which substitutes images with generated captions to enable purely text-based alignment. Evaluations on two representative domains: clinician-patient dialogues (CliConSummation) and radiology reports (MIMIC-CXR), show that our approach consistently outperforms embedding-based and self-attribution baselines, improving both text-level and multimodal attribution accuracy (e.g., +15% F1 over embedding baselines). Caption-based attribution achieves competitive performance with raw-image attention while being more lightweight and practical. These findings highlight attention-guided attribution as a promising step toward interpretable and deployable clinical summarization systems.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
DoRAN: Stabilizing Weight-Decomposed Low-Rank Adaptation via Noise Injection and Auxiliary Networks
Oct 05, 2025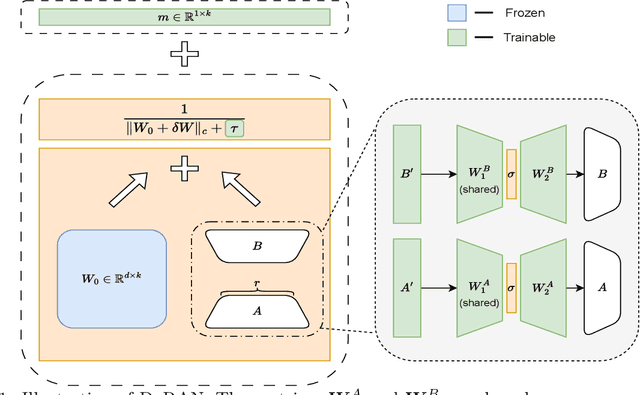

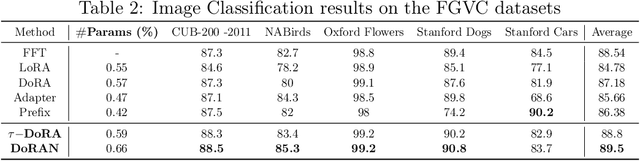
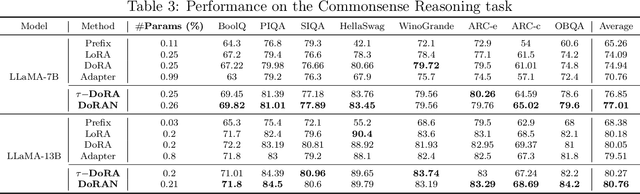
Parameter-efficient fine-tuning (PEFT) methods have become the standard paradigm for adapting large-scale models. Among these techniques, Weight-Decomposed Low-Rank Adaptation (DoRA) has been shown to improve both the learning capacity and training stability of the vanilla Low-Rank Adaptation (LoRA) method by explicitly decomposing pre-trained weights into magnitude and directional components. In this work, we propose DoRAN, a new variant of DoRA designed to further stabilize training and boost the sample efficiency of DoRA. Our approach includes two key stages: (i) injecting noise into the denominator of DoRA's weight decomposition, which serves as an adaptive regularizer to mitigate instabilities; and (ii) replacing static low-rank matrices with auxiliary networks that generate them dynamically, enabling parameter coupling across layers and yielding better sample efficiency in both theory and practice. Comprehensive experiments on vision and language benchmarks show that DoRAN consistently outperforms LoRA, DoRA, and other PEFT baselines. These results underscore the effectiveness of combining stabilization through noise-based regularization with network-based parameter generation, offering a promising direction for robust and efficient fine-tuning of foundation models.
HoRA: Cross-Head Low-Rank Adaptation with Joint Hypernetworks
Oct 05, 2025Low-Rank Adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) technique that adapts large pre-trained models by adding low-rank matrices to their weight updates. However, in the context of fine-tuning multi-head self-attention (MHA), LoRA has been employed to adapt each attention head separately, thereby overlooking potential synergies across different heads. To mitigate this issue, we propose a novel Hyper-shared Low-Rank Adaptation (HoRA) method, which utilizes joint hypernetworks to generate low-rank matrices across attention heads. By coupling their adaptation through a shared generator, HoRA encourages cross-head information sharing, and thus directly addresses the aforementioned limitation of LoRA. By comparing LoRA and HoRA through the lens of hierarchical mixture of experts, our theoretical findings reveal that the latter achieves superior sample efficiency to the former. Furthermore, through extensive experiments across diverse language and vision benchmarks, we demonstrate that HoRA outperforms LoRA and other PEFT methods while requiring only a marginal increase in the number of trainable parameters.
AG-VPReID.VIR: Bridging Aerial and Ground Platforms for Video-based Visible-Infrared Person Re-ID
Jul 24, 2025Person re-identification (Re-ID) across visible and infrared modalities is crucial for 24-hour surveillance systems, but existing datasets primarily focus on ground-level perspectives. While ground-based IR systems offer nighttime capabilities, they suffer from occlusions, limited coverage, and vulnerability to obstructions--problems that aerial perspectives uniquely solve. To address these limitations, we introduce AG-VPReID.VIR, the first aerial-ground cross-modality video-based person Re-ID dataset. This dataset captures 1,837 identities across 4,861 tracklets (124,855 frames) using both UAV-mounted and fixed CCTV cameras in RGB and infrared modalities. AG-VPReID.VIR presents unique challenges including cross-viewpoint variations, modality discrepancies, and temporal dynamics. Additionally, we propose TCC-VPReID, a novel three-stream architecture designed to address the joint challenges of cross-platform and cross-modality person Re-ID. Our approach bridges the domain gaps between aerial-ground perspectives and RGB-IR modalities, through style-robust feature learning, memory-based cross-view adaptation, and intermediary-guided temporal modeling. Experiments show that AG-VPReID.VIR presents distinctive challenges compared to existing datasets, with our TCC-VPReID framework achieving significant performance gains across multiple evaluation protocols. Dataset and code are available at https://github.com/agvpreid25/AG-VPReID.VIR.
On Minimax Estimation of Parameters in Softmax-Contaminated Mixture of Experts
May 24, 2025
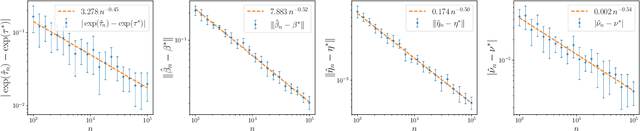
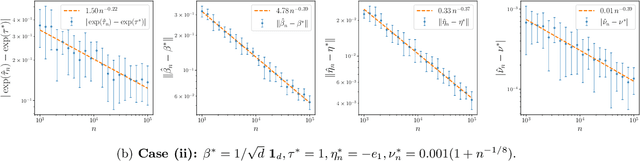
The softmax-contaminated mixture of experts (MoE) model is deployed when a large-scale pre-trained model, which plays the role of a fixed expert, is fine-tuned for learning downstream tasks by including a new contamination part, or prompt, functioning as a new, trainable expert. Despite its popularity and relevance, the theoretical properties of the softmax-contaminated MoE have remained unexplored in the literature. In the paper, we study the convergence rates of the maximum likelihood estimator of gating and prompt parameters in order to gain insights into the statistical properties and potential challenges of fine-tuning with a new prompt. We find that the estimability of these parameters is compromised when the prompt acquires overlapping knowledge with the pre-trained model, in the sense that we make precise by formulating a novel analytic notion of distinguishability. Under distinguishability of the pre-trained and prompt models, we derive minimax optimal estimation rates for all the gating and prompt parameters. By contrast, when the distinguishability condition is violated, these estimation rates become significantly slower due to their dependence on the prompt convergence rate to the pre-trained model. Finally, we empirically corroborate our theoretical findings through several numerical experiments.
CompeteSMoE -- Statistically Guaranteed Mixture of Experts Training via Competition
May 19, 2025
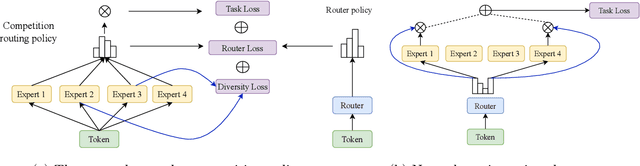


Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, we argue that effective SMoE training remains challenging because of the suboptimal routing process where experts that perform computation do not directly contribute to the routing process. In this work, we propose competition, a novel mechanism to route tokens to experts with the highest neural response. Theoretically, we show that the competition mechanism enjoys a better sample efficiency than the traditional softmax routing. Furthermore, we develop CompeteSMoE, a simple yet effective algorithm to train large language models by deploying a router to learn the competition policy, thus enjoying strong performances at a low training overhead. Our extensive empirical evaluations on both the visual instruction tuning and language pre-training tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies. We have made the implementation available at: https://github.com/Fsoft-AIC/CompeteSMoE. This work is an improved version of the previous study at arXiv:2402.02526