 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaST: Causal Discovery via Spatio-Temporal Graphs in Disaster Tweets
Feb 01, 2026Understanding causality between real-world events from social media is essential for situational awareness, yet existing causal discovery methods often overlook the interplay between semantic, spatial, and temporal contexts. We propose CaST: Causal Discovery via Spatio-Temporal Graphs, a unified framework for causal discovery in disaster domain that integrates semantic similarity and spatio-temporal proximity using Large Language Models (LLMs) pretrained on disaster datasets. CaST constructs an event graph for each window of tweets. Each event extracted from tweets is represented as a node embedding enriched with its contextual semantics, geographic coordinates, and temporal features. These event nodes are then connected to form a spatio-temporal event graph, which is processed using a multi-head Graph Attention Network (GAT) \cite{gat} to learn directed causal relationships. We construct an in-house dataset of approximately 167K disaster-related tweets collected during Hurricane Harvey and annotated following the MAVEN-ERE schema. Experimental results show that CaST achieves superior performance over both traditional and state-of-the-art methods. Ablation studies further confirm that incorporating spatial and temporal signals substantially improves both recall and stability during training. Overall, CaST demonstrates that integrating spatio-temporal reasoning into event graphs enables more robust and interpretable causal discovery in disaster-related social media text.
SentiFuse: Deep Multi-model Fusion Framework for Robust Sentiment Extraction
Feb 01, 2026Sentiment analysis models exhibit complementary strengths, yet existing approaches lack a unified framework for effective integration. We present SentiFuse, a flexible and model-agnostic framework that integrates heterogeneous sentiment models through a standardization layer and multiple fusion strategies. Our approach supports decision-level fusion, feature-level fusion, and adaptive fusion, enabling systematic combination of diverse models. We conduct experiments on three large-scale social-media datasets: Crowdflower, GoEmotions, and Sentiment140. These experiments show that SentiFuse consistently outperforms individual models and naive ensembles. Feature-level fusion achieves the strongest overall effectiveness, yielding up to 4\% absolute improvement in F1 score over the best individual model and simple averaging, while adaptive fusion enhances robustness on challenging cases such as negation, mixed emotions, and complex sentiment expressions. These results demonstrate that systematically leveraging model complementarity yields more accurate and reliable sentiment analysis across diverse datasets and text types.
VietMed-MCQ: A Consistency-Filtered Data Synthesis Framework for Vietnamese Traditional Medicine Evaluation
Jan 07, 2026Large Language Models (LLMs) have demonstrated remarkable proficiency in general medical domains. However, their performance significantly degrades in specialized, culturally specific domains such as Vietnamese Traditional Medicine (VTM), primarily due to the scarcity of high-quality, structured benchmarks. In this paper, we introduce VietMed-MCQ, a novel multiple-choice question dataset generated via a Retrieval-Augmented Generation (RAG) pipeline with an automated consistency check mechanism. Unlike previous synthetic datasets, our framework incorporates a dual-model validation approach to ensure reasoning consistency through independent answer verification, though the substring-based evidence checking has known limitations. The complete dataset of 3,190 questions spans three difficulty levels and underwent validation by one medical expert and four students, achieving 94.2 percent approval with substantial inter-rater agreement (Fleiss' kappa = 0.82). We benchmark seven open-source models on VietMed-MCQ. Results reveal that general-purpose models with strong Chinese priors outperform Vietnamese-centric models, highlighting cross-lingual conceptual transfer, while all models still struggle with complex diagnostic reasoning. Our code and dataset are publicly available to foster research in low-resource medical domains.
LEAD: Minimizing Learner-Expert Asymmetry in End-to-End Driving
Dec 23, 2025Simulators can generate virtually unlimited driving data, yet imitation learning policies in simulation still struggle to achieve robust closed-loop performance. Motivated by this gap, we empirically study how misalignment between privileged expert demonstrations and sensor-based student observations can limit the effectiveness of imitation learning. More precisely, experts have significantly higher visibility (e.g., ignoring occlusions) and far lower uncertainty (e.g., knowing other vehicles' actions), making them difficult to imitate reliably. Furthermore, navigational intent (i.e., the route to follow) is under-specified in student models at test time via only a single target point. We demonstrate that these asymmetries can measurably limit driving performance in CARLA and offer practical interventions to address them. After careful modifications to narrow the gaps between expert and student, our TransFuser v6 (TFv6) student policy achieves a new state of the art on all major publicly available CARLA closed-loop benchmarks, reaching 95 DS on Bench2Drive and more than doubling prior performances on Longest6~v2 and Town13. Additionally, by integrating perception supervision from our dataset into a shared sim-to-real pipeline, we show consistent gains on the NAVSIM and Waymo Vision-Based End-to-End driving benchmarks. Our code, data, and models are publicly available at https://github.com/autonomousvision/lead.
Advancing Vietnamese Information Retrieval with Learning Objective and Benchmark
Mar 10, 2025With the rapid development of natural language processing, many language models have been invented for multiple tasks. One important task is information retrieval (IR), which requires models to retrieve relevant documents. Despite its importance in many real-life applications, especially in retrieval augmented generation (RAG) systems, this task lacks Vietnamese benchmarks. This situation causes difficulty in assessing and comparing many existing Vietnamese embedding language models on the task and slows down the advancement of Vietnamese natural language processing (NLP) research. In this work, we aim to provide the Vietnamese research community with a new benchmark for information retrieval, which mainly focuses on retrieval and reranking tasks. Furthermore, we also present a new objective function based on the InfoNCE loss function, which is used to train our Vietnamese embedding model. Our function aims to be better than the origin in information retrieval tasks. Finally, we analyze the effect of temperature, a hyper-parameter in both objective functions, on the performance of text embedding models.
URAG: Implementing a Unified Hybrid RAG for Precise Answers in University Admission Chatbots -- A Case Study at HCMUT
Jan 27, 2025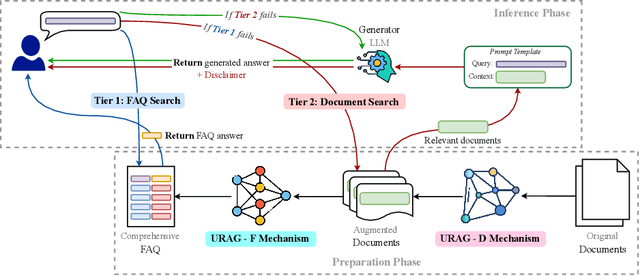

With the rapid advancement of Artificial Intelligence, particularly in Natural Language Processing, Large Language Models (LLMs) have become pivotal in educational question-answering systems, especially university admission chatbots. Concepts such as Retrieval-Augmented Generation (RAG) and other advanced techniques have been developed to enhance these systems by integrating specific university data, enabling LLMs to provide informed responses on admissions and academic counseling. However, these enhanced RAG techniques often involve high operational costs and require the training of complex, specialized modules, which poses challenges for practical deployment. Additionally, in the educational context, it is crucial to provide accurate answers to prevent misinformation, a task that LLM-based systems find challenging without appropriate strategies and methods. In this paper, we introduce the Unified RAG (URAG) Framework, a hybrid approach that significantly improves the accuracy of responses, particularly for critical queries. Experimental results demonstrate that URAG enhances our in-house, lightweight model to perform comparably to state-of-the-art commercial models. Moreover, to validate its practical applicability, we conducted a case study at our educational institution, which received positive feedback and acclaim. This study not only proves the effectiveness of URAG but also highlights its feasibility for real-world implementation in educational settings.
RAPID: Retrieval-Augmented Parallel Inference Drafting for Text-Based Video Event Retrieval
Jan 27, 2025



Retrieving events from videos using text queries has become increasingly challenging due to the rapid growth of multimedia content. Existing methods for text-based video event retrieval often focus heavily on object-level descriptions, overlooking the crucial role of contextual information. This limitation is especially apparent when queries lack sufficient context, such as missing location details or ambiguous background elements. To address these challenges, we propose a novel system called RAPID (Retrieval-Augmented Parallel Inference Drafting), which leverages advancements in Large Language Models (LLMs) and prompt-based learning to semantically correct and enrich user queries with relevant contextual information. These enriched queries are then processed through parallel retrieval, followed by an evaluation step to select the most relevant results based on their alignment with the original query. Through extensive experiments on our custom-developed dataset, we demonstrate that RAPID significantly outperforms traditional retrieval methods, particularly for contextually incomplete queries. Our system was validated for both speed and accuracy through participation in the Ho Chi Minh City AI Challenge 2024, where it successfully retrieved events from over 300 hours of video. Further evaluation comparing RAPID with the baseline proposed by the competition organizers demonstrated its superior effectiveness, highlighting the strength and robustness of our approach.
Automated Body Composition Analysis Using DAFS Express on 2D MRI Slices at L3 Vertebral Level
Sep 11, 2024
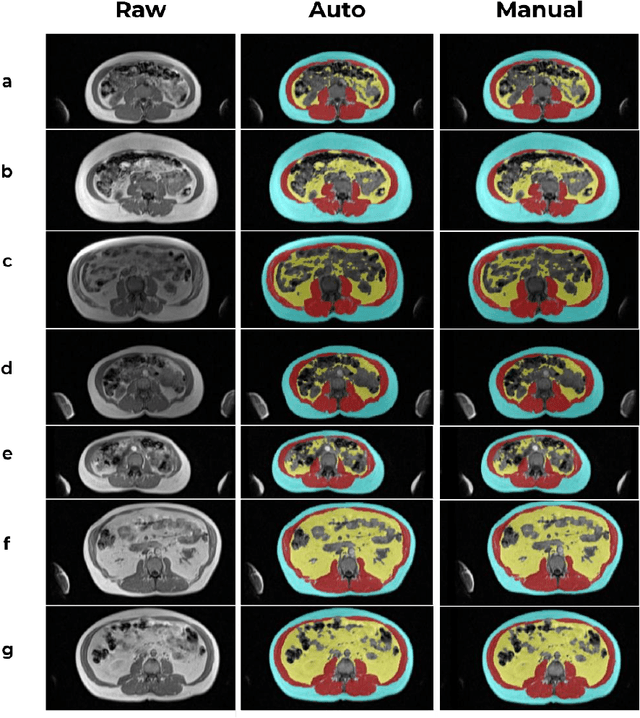
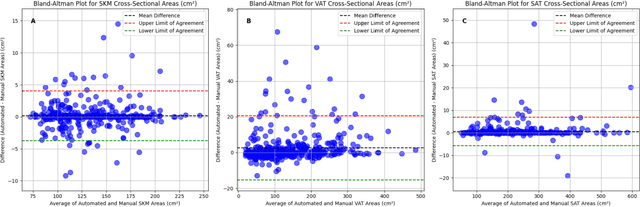
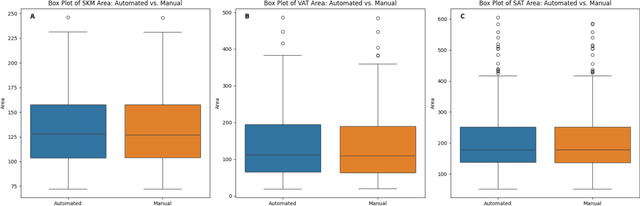
Body composition analysis is vital in assessing health conditions such as obesity, sarcopenia, and metabolic syndromes. MRI provides detailed images of skeletal muscle (SKM), visceral adipose tissue (VAT), and subcutaneous adipose tissue (SAT), but their manual segmentation is labor-intensive and limits clinical applicability. This study validates an automated tool for MRI-based 2D body composition analysis- (Data Analysis Facilitation Suite (DAFS) Express), comparing its automated measurements with expert manual segmentations using UK Biobank data. A cohort of 399 participants from the UK Biobank dataset was selected, yielding 423 single L3 slices for analysis. DAFS Express performed automated segmentations of SKM, VAT, and SAT, which were then manually corrected by expert raters for validation. Evaluation metrics included Jaccard coefficients, Dice scores, Intraclass Correlation Coefficients (ICCs), and Bland-Altman Plots to assess segmentation agreement and reliability. High agreements were observed between automated and manual segmentations with mean Jaccard scores: SKM 99.03%, VAT 95.25%, and SAT 99.57%; and mean Dice scores: SKM 99.51%, VAT 97.41%, and SAT 99.78%. Cross-sectional area comparisons showed consistent measurements with automated methods closely matching manual measurements for SKM and SAT, and slightly higher values for VAT (SKM: Auto 132.51 cm^2, Manual 132.36 cm^2; VAT: Auto 137.07 cm^2, Manual 134.46 cm^2; SAT: Auto 203.39 cm^2, Manual 202.85 cm^2). ICCs confirmed strong reliability (SKM: 0.998, VAT: 0.994, SAT: 0.994). Bland-Altman plots revealed minimal biases, and boxplots illustrated distribution similarities across SKM, VAT, and SAT areas. On average DAFS Express took 18 seconds per DICOM. This underscores its potential to streamline image analysis processes in research and clinical settings, enhancing diagnostic accuracy and efficiency.
Public Health in Disaster: Emotional Health and Life Incidents Extraction during Hurricane Harvey
Aug 20, 2024Countless disasters have resulted from climate change, causing severe damage to infrastructure and the economy. These disasters have significant societal impacts, necessitating mental health services for the millions affected. To prepare for and respond effectively to such events, it is important to understand people's emotions and the life incidents they experience before and after a disaster strikes. In this case study, we collected a dataset of approximately 400,000 public tweets related to the storm. Using a BERT-based model, we predicted the emotions associated with each tweet. To efficiently identify these topics, we utilized the Latent Dirichlet Allocation (LDA) technique for topic modeling, which allowed us to bypass manual content analysis and extract meaningful patterns from the data. However, rather than stopping at topic identification like previous methods \cite{math11244910}, we further refined our analysis by integrating Graph Neural Networks (GNN) and Large Language Models (LLM). The GNN was employed to generate embeddings and construct a similarity graph of the tweets, which was then used to optimize clustering. Subsequently, we used an LLM to automatically generate descriptive names for each event cluster, offering critical insights for disaster preparedness and response strategies.
Cross-Data Knowledge Graph Construction for LLM-enabled Educational Question-Answering System: A~Case~Study~at~HCMUT
Apr 14, 2024



In today's rapidly evolving landscape of Artificial Intelligence, large language models (LLMs) have emerged as a vibrant research topic. LLMs find applications in various fields and contribute significantly. Despite their powerful language capabilities, similar to pre-trained language models (PLMs), LLMs still face challenges in remembering events, incorporating new information, and addressing domain-specific issues or hallucinations. To overcome these limitations, researchers have proposed Retrieval-Augmented Generation (RAG) techniques, some others have proposed the integration of LLMs with Knowledge Graphs (KGs) to provide factual context, thereby improving performance and delivering more accurate feedback to user queries. Education plays a crucial role in human development and progress. With the technology transformation, traditional education is being replaced by digital or blended education. Therefore, educational data in the digital environment is increasing day by day. Data in higher education institutions are diverse, comprising various sources such as unstructured/structured text, relational databases, web/app-based API access, etc. Constructing a Knowledge Graph from these cross-data sources is not a simple task. This article proposes a method for automatically constructing a Knowledge Graph from multiple data sources and discusses some initial applications (experimental trials) of KG in conjunction with LLMs for question-answering tasks.