 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCELOT 2023: Cell Detection from Cell-Tissue Interaction Challenge
Sep 11, 2025Pathologists routinely alternate between different magnifications when examining Whole-Slide Images, allowing them to evaluate both broad tissue morphology and intricate cellular details to form comprehensive diagnoses. However, existing deep learning-based cell detection models struggle to replicate these behaviors and learn the interdependent semantics between structures at different magnifications. A key barrier in the field is the lack of datasets with multi-scale overlapping cell and tissue annotations. The OCELOT 2023 challenge was initiated to gather insights from the community to validate the hypothesis that understanding cell and tissue (cell-tissue) interactions is crucial for achieving human-level performance, and to accelerate the research in this field. The challenge dataset includes overlapping cell detection and tissue segmentation annotations from six organs, comprising 673 pairs sourced from 306 The Cancer Genome Atlas (TCGA) Whole-Slide Images with hematoxylin and eosin staining, divided into training, validation, and test subsets. Participants presented models that significantly enhanced the understanding of cell-tissue relationships. Top entries achieved up to a 7.99 increase in F1-score on the test set compared to the baseline cell-only model that did not incorporate cell-tissue relationships. This is a substantial improvement in performance over traditional cell-only detection methods, demonstrating the need for incorporating multi-scale semantics into the models. This paper provides a comparative analysis of the methods used by participants, highlighting innovative strategies implemented in the OCELOT 2023 challenge.
* This is the accepted manuscript of an article published in Medical Image Analysis (Elsevier). The final version is available at: https://doi.org/10.1016/j.media.2025.103751
Bridging the Vision-Brain Gap with an Uncertainty-Aware Blur Prior
Mar 06, 2025



Can our brain signals faithfully reflect the original visual stimuli, even including high-frequency details? Although human perceptual and cognitive capacities enable us to process and remember visual information, these abilities are constrained by several factors, such as limited attentional resources and the finite capacity of visual memory. When visual stimuli are processed by human visual system into brain signals, some information is inevitably lost, leading to a discrepancy known as the \textbf{System GAP}. Additionally, perceptual and cognitive dynamics, along with technical noise in signal acquisition, degrade the fidelity of brain signals relative to the visual stimuli, known as the \textbf{Random GAP}. When encoded brain representations are directly aligned with the corresponding pretrained image features, the System GAP and Random GAP between paired data challenge the model, requiring it to bridge these gaps. However, in the context of limited paired data, these gaps are difficult for the model to learn, leading to overfitting and poor generalization to new data. To address these GAPs, we propose a simple yet effective approach called the \textbf{Uncertainty-aware Blur Prior (UBP)}. It estimates the uncertainty within the paired data, reflecting the mismatch between brain signals and visual stimuli. Based on this uncertainty, UBP dynamically blurs the high-frequency details of the original images, reducing the impact of the mismatch and improving alignment. Our method achieves a top-1 accuracy of \textbf{50.9\%} and a top-5 accuracy of \textbf{79.7\%} on the zero-shot brain-to-image retrieval task, surpassing previous state-of-the-art methods by margins of \textbf{13.7\%} and \textbf{9.8\%}, respectively. Code is available at \href{https://github.com/HaitaoWuTJU/Uncertainty-aware-Blur-Prior}{GitHub}.
Off to new Shores: A Dataset & Benchmark for (near-)coastal Flood Inundation Forecasting
Sep 27, 2024



Floods are among the most common and devastating natural hazards, imposing immense costs on our society and economy due to their disastrous consequences. Recent progress in weather prediction and spaceborne flood mapping demonstrated the feasibility of anticipating extreme events and reliably detecting their catastrophic effects afterwards. However, these efforts are rarely linked to one another and there is a critical lack of datasets and benchmarks to enable the direct forecasting of flood extent. To resolve this issue, we curate a novel dataset enabling a timely prediction of flood extent. Furthermore, we provide a representative evaluation of state-of-the-art methods, structured into two benchmark tracks for forecasting flood inundation maps i) in general and ii) focused on coastal regions. Altogether, our dataset and benchmark provide a comprehensive platform for evaluating flood forecasts, enabling future solutions for this critical challenge. Data, code & models are shared at https://github.com/Multihuntr/GFF under a CC0 license.
Group Activity Recognition using Unreliable Tracked Pose
Jan 06, 2024

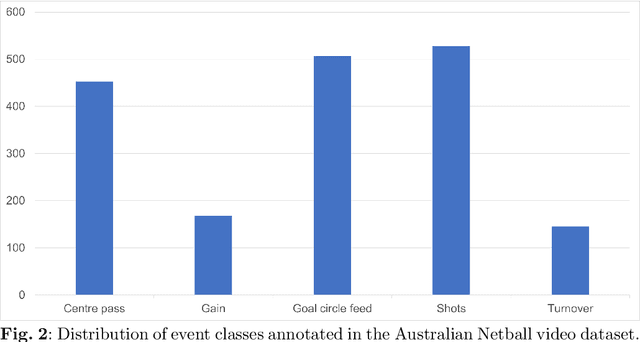

Group activity recognition in video is a complex task due to the need for a model to recognise the actions of all individuals in the video and their complex interactions. Recent studies propose that optimal performance is achieved by individually tracking each person and subsequently inputting the sequence of poses or cropped images/optical flow into a model. This helps the model to recognise what actions each person is performing before they are merged to arrive at the group action class. However, all previous models are highly reliant on high quality tracking and have only been evaluated using ground truth tracking information. In practice it is almost impossible to achieve highly reliable tracking information for all individuals in a group activity video. We introduce an innovative deep learning-based group activity recognition approach called Rendered Pose based Group Activity Recognition System (RePGARS) which is designed to be tolerant of unreliable tracking and pose information. Experimental results confirm that RePGARS outperforms all existing group activity recognition algorithms tested which do not use ground truth detection and tracking information.
Classifying Whole Slide Images: What Matters?
Oct 05, 2023
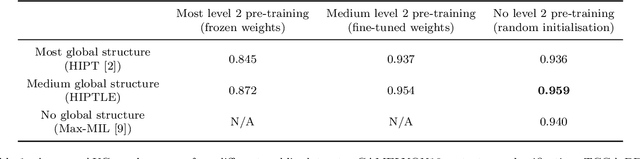
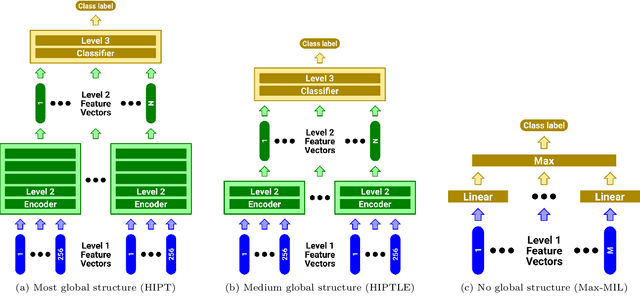
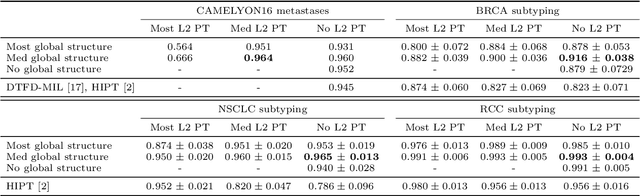
Recently there have been many algorithms proposed for the classification of very high resolution whole slide images (WSIs). These new algorithms are mostly focused on finding novel ways to combine the information from small local patches extracted from the slide, with an emphasis on effectively aggregating more global information for the final predictor. In this paper we thoroughly explore different key design choices for WSI classification algorithms to investigate what matters most for achieving high accuracy. Surprisingly, we found that capturing global context information does not necessarily mean better performance. A model that captures the most global information consistently performs worse than a model that captures less global information. In addition, a very simple multi-instance learning method that captures no global information performs almost as well as models that capture a lot of global information. These results suggest that the most important features for effective WSI classification are captured at the local small patch level, where cell and tissue micro-environment detail is most pronounced. Another surprising finding was that unsupervised pre-training on a larger set of 33 cancers gives significantly worse performance compared to pre-training on a smaller dataset of 7 cancers (including the target cancer). We posit that pre-training on a smaller, more focused dataset allows the feature extractor to make better use of the limited feature space to better discriminate between subtle differences in the input patch.
Local-to-Global Panorama Inpainting for Locale-Aware Indoor Lighting Prediction
Mar 18, 2023



Predicting panoramic indoor lighting from a single perspective image is a fundamental but highly ill-posed problem in computer vision and graphics. To achieve locale-aware and robust prediction, this problem can be decomposed into three sub-tasks: depth-based image warping, panorama inpainting and high-dynamic-range (HDR) reconstruction, among which the success of panorama inpainting plays a key role. Recent methods mostly rely on convolutional neural networks (CNNs) to fill the missing contents in the warped panorama. However, they usually achieve suboptimal performance since the missing contents occupy a very large portion in the panoramic space while CNNs are plagued by limited receptive fields. The spatially-varying distortion in the spherical signals further increases the difficulty for conventional CNNs. To address these issues, we propose a local-to-global strategy for large-scale panorama inpainting. In our method, a depth-guided local inpainting is first applied on the warped panorama to fill small but dense holes. Then, a transformer-based network, dubbed PanoTransformer, is designed to hallucinate reasonable global structures in the large holes. To avoid distortion, we further employ cubemap projection in our design of PanoTransformer. The high-quality panorama recovered at any locale helps us to capture spatially-varying indoor illumination with physically-plausible global structures and fine details.
A systematic review of the use of Deep Learning in Satellite Imagery for Agriculture
Oct 03, 2022

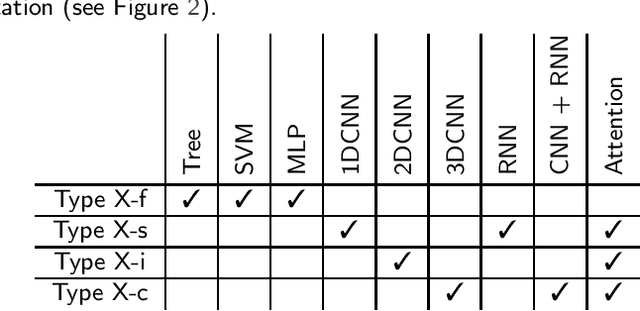
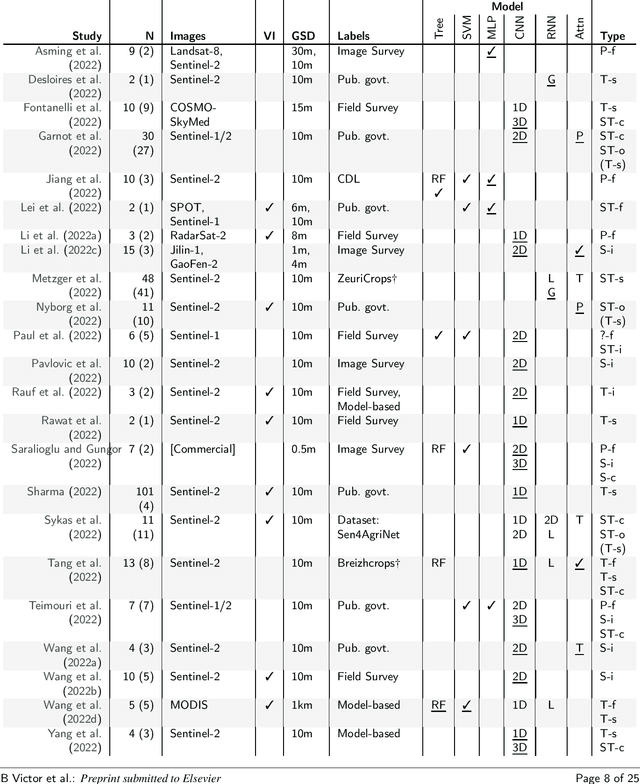
Agricultural research is essential for increasing food production to meet the requirements of an increasing population in the coming decades. Recently, satellite technology has been improving rapidly and deep learning has seen much success in generic computer vision tasks and many application areas which presents an important opportunity to improve analysis of agricultural land. Here we present a systematic review of 150 studies to find the current uses of deep learning on satellite imagery for agricultural research. Although we identify 5 categories of agricultural monitoring tasks, the majority of the research interest is in crop segmentation and yield prediction. We found that, when used, modern deep learning methods consistently outperformed traditional machine learning across most tasks; the only exception was that Long Short-Term Memory (LSTM) Recurrent Neural Networks did not consistently outperform Random Forests (RF) for yield prediction. The reviewed studies have largely adopted methodologies from generic computer vision, except for one major omission: benchmark datasets are not utilised to evaluate models across studies, making it difficult to compare results. Additionally, some studies have specifically utilised the extra spectral resolution available in satellite imagery, but other divergent properties of satellite images - such as the hugely different scales of spatial patterns - are not being taken advantage of in the reviewed studies.
Spatial Transformer Network with Transfer Learning for Small-scale Fine-grained Skeleton-based Tai Chi Action Recognition
Jun 30, 2022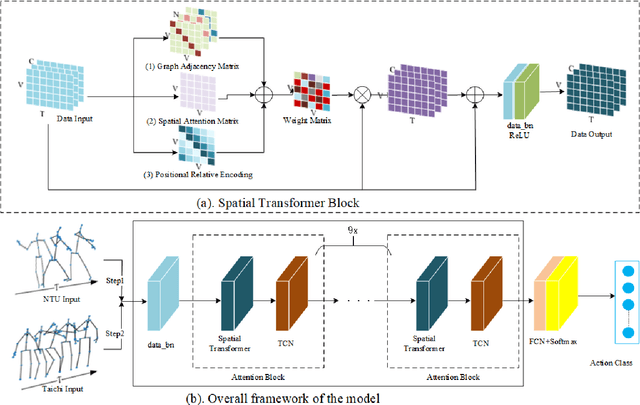

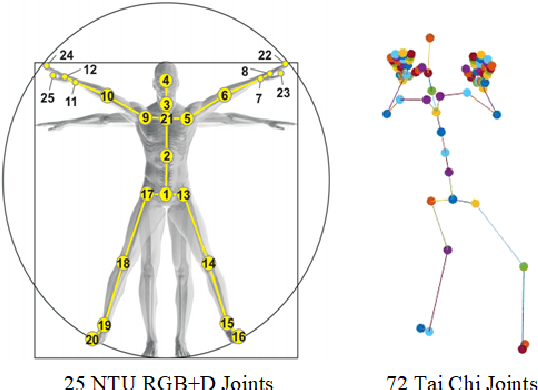
Human action recognition is a quite hugely investigated area where most remarkable action recognition networks usually use large-scale coarse-grained action datasets of daily human actions as inputs to state the superiority of their networks. We intend to recognize our small-scale fine-grained Tai Chi action dataset using neural networks and propose a transfer-learning method using NTU RGB+D dataset to pre-train our network. More specifically, the proposed method first uses a large-scale NTU RGB+D dataset to pre-train the Transformer-based network for action recognition to extract common features among human motion. Then we freeze the network weights except for the fully connected (FC) layer and take our Tai Chi actions as inputs only to train the initialized FC weights. Experimental results show that our general model pipeline can reach a high accuracy of small-scale fine-grained Tai Chi action recognition with even few inputs and demonstrate that our method achieves the state-of-the-art performance compared with previous Tai Chi action recognition methods.
Automatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022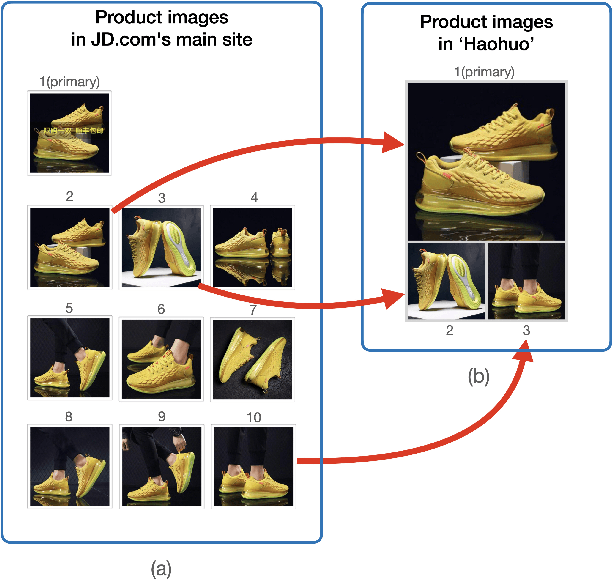

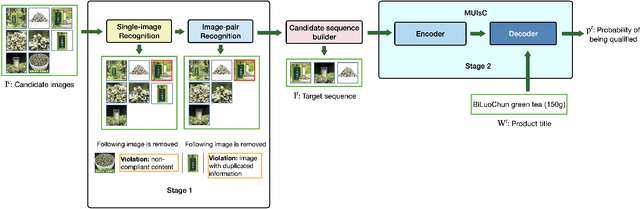
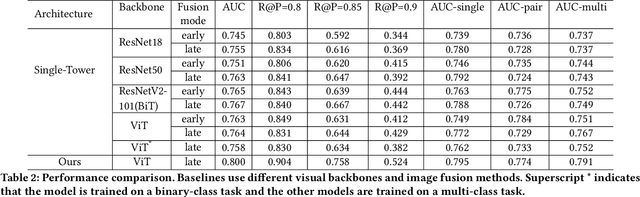
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
Scenario-based Multi-product Advertising Copywriting Generation for E-Commerce
May 21, 2022

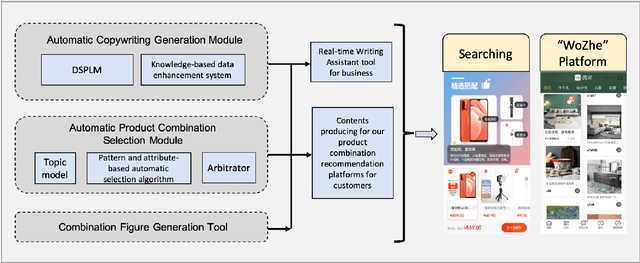
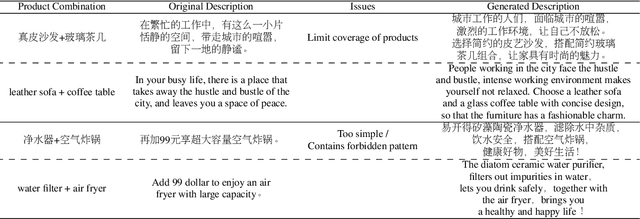
In this paper, we proposed an automatic Scenario-based Multi-product Advertising Copywriting Generation system (SMPACG) for E-Commerce, which has been deployed on a leading Chinese e-commerce platform. The proposed SMPACG consists of two main components: 1) an automatic multi-product combination selection module, which itself is consisted of a topic prediction model, a pattern and attribute-based selection model and an arbitrator model; and 2) an automatic multi-product advertising copywriting generation module, which combines our proposed domain-specific pretrained language model and knowledge-based data enhancement model. The SMPACG is the first system that realizes automatic scenario-based multi-product advertising contents generation, which achieves significant improvements over other state-of-the-art methods. The SMPACG has been not only developed for directly serving for our e-commerce recommendation system, but also used as a real-time writing assistant tool for merchants.