 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCast: Reliability-aware Codebook Assisted Lightweight Time Series Forecasting
Nov 15, 2025Time series forecasting is crucial for applications in various domains. Conventional methods often rely on global decomposition into trend, seasonal, and residual components, which become ineffective for real-world series dominated by local, complex, and highly dynamic patterns. Moreover, the high model complexity of such approaches limits their applicability in real-time or resource-constrained environments. In this work, we propose a novel \textbf{RE}liability-aware \textbf{C}odebook-\textbf{AS}sisted \textbf{T}ime series forecasting framework (\textbf{ReCast}) that enables lightweight and robust prediction by exploiting recurring local shapes. ReCast encodes local patterns into discrete embeddings through patch-wise quantization using a learnable codebook, thereby compactly capturing stable regular structures. To compensate for residual variations not preserved by quantization, ReCast employs a dual-path architecture comprising a quantization path for efficient modeling of regular structures and a residual path for reconstructing irregular fluctuations. A central contribution of ReCast is a reliability-aware codebook update strategy, which incrementally refines the codebook via weighted corrections. These correction weights are derived by fusing multiple reliability factors from complementary perspectives by a distributionally robust optimization (DRO) scheme, ensuring adaptability to non-stationarity and robustness to distribution shifts. Extensive experiments demonstrate that ReCast outperforms state-of-the-art (SOTA) models in accuracy, efficiency, and adaptability to distribution shifts.
CoCo-Bench: A Comprehensive Code Benchmark For Multi-task Large Language Model Evaluation
Apr 29, 2025Large language models (LLMs) play a crucial role in software engineering, excelling in tasks like code generation and maintenance. However, existing benchmarks are often narrow in scope, focusing on a specific task and lack a comprehensive evaluation framework that reflects real-world applications. To address these gaps, we introduce CoCo-Bench (Comprehensive Code Benchmark), designed to evaluate LLMs across four critical dimensions: code understanding, code generation, code modification, and code review. These dimensions capture essential developer needs, ensuring a more systematic and representative evaluation. CoCo-Bench includes multiple programming languages and varying task difficulties, with rigorous manual review to ensure data quality and accuracy. Empirical results show that CoCo-Bench aligns with existing benchmarks while uncovering significant variations in model performance, effectively highlighting strengths and weaknesses. By offering a holistic and objective evaluation, CoCo-Bench provides valuable insights to guide future research and technological advancements in code-oriented LLMs, establishing a reliable benchmark for the field.
Point Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
Minding Fuzzy Regions: A Data-driven Alternating Learning Paradigm for Stable Lesion Segmentation
Mar 14, 2025Deep learning has achieved significant advancements in medical image segmentation, but existing models still face challenges in accurately segmenting lesion regions. The main reason is that some lesion regions in medical images have unclear boundaries, irregular shapes, and small tissue density differences, leading to label ambiguity. However, the existing model treats all data equally without taking quality differences into account in the training process, resulting in noisy labels negatively impacting model training and unstable feature representations. In this paper, a data-driven alternating learning (DALE) paradigm is proposed to optimize the model's training process, achieving stable and high-precision segmentation. The paradigm focuses on two key points: (1) reducing the impact of noisy labels, and (2) calibrating unstable representations. To mitigate the negative impact of noisy labels, a loss consistency-based collaborative optimization method is proposed, and its effectiveness is theoretically demonstrated. Specifically, the label confidence parameters are introduced to dynamically adjust the influence of labels of different confidence levels during model training, thus reducing the influence of noise labels. To calibrate the learning bias of unstable representations, a distribution alignment method is proposed. This method restores the underlying distribution of unstable representations, thereby enhancing the discriminative capability of fuzzy region representations. Extensive experiments on various benchmarks and model backbones demonstrate the superiority of the DALE paradigm, achieving an average performance improvement of up to 7.16%.
Bridging the Modality Gap: Dimension Information Alignment and Sparse Spatial Constraint for Image-Text Matching
Oct 22, 2024



Many contrastive learning based models have achieved advanced performance in image-text matching tasks. The key of these models lies in analyzing the correlation between image-text pairs, which involves cross-modal interaction of embeddings in corresponding dimensions. However, the embeddings of different modalities are from different models or modules, and there is a significant modality gap. Directly interacting such embeddings lacks rationality and may capture inaccurate correlation. Therefore, we propose a novel method called DIAS to bridge the modality gap from two aspects: (1) We align the information representation of embeddings from different modalities in corresponding dimension to ensure the correlation calculation is based on interactions of similar information. (2) The spatial constraints of inter- and intra-modalities unmatched pairs are introduced to ensure the effectiveness of semantic alignment of the model. Besides, a sparse correlation algorithm is proposed to select strong correlated spatial relationships, enabling the model to learn more significant features and avoid being misled by weak correlation. Extensive experiments demonstrate the superiority of DIAS, achieving 4.3\%-10.2\% rSum improvements on Flickr30k and MSCOCO benchmarks.
Robust Interaction-based Relevance Modeling for Online E-Commerce and LLM-based Retrieval
Jun 04, 2024Semantic relevance calculation is crucial for e-commerce search engines, as it ensures that the items selected closely align with customer intent. Inadequate attention to this aspect can detrimentally affect user experience and engagement. Traditional text-matching techniques are prevalent but often fail to capture the nuances of search intent accurately, so neural networks now have become a preferred solution to processing such complex text matching. Existing methods predominantly employ representation-based architectures, which strike a balance between high traffic capacity and low latency. However, they exhibit significant shortcomings in generalization and robustness when compared to interaction-based architectures. In this work, we introduce a robust interaction-based modeling paradigm to address these shortcomings. It encompasses 1) a dynamic length representation scheme for expedited inference, 2) a professional terms recognition method to identify subjects and core attributes from complex sentence structures, and 3) a contrastive adversarial training protocol to bolster the model's robustness and matching capabilities. Extensive offline evaluations demonstrate the superior robustness and effectiveness of our approach, and online A/B testing confirms its ability to improve relevance in the same exposure position, resulting in more clicks and conversions. To the best of our knowledge, this method is the first interaction-based approach for large e-commerce search relevance calculation. Notably, we have deployed it for the entire search traffic on alibaba.com, the largest B2B e-commerce platform in the world.
Exploring Communication Technologies, Standards, and Challenges in Electrified Vehicle Charging
Mar 25, 2024

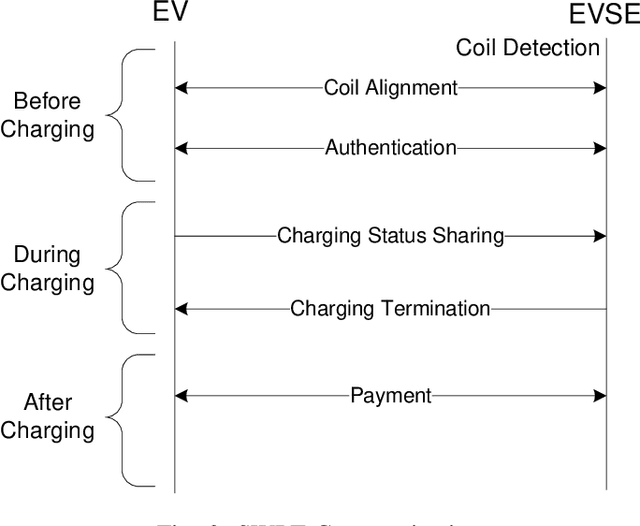
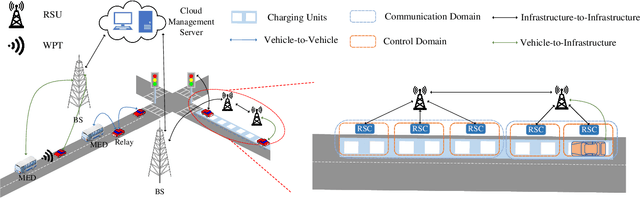
As public awareness of environmental protection continues to grow, the trend of integrating more electric vehicles (EVs) into the transportation sector is rising. Unlike conventional internal combustion engine (ICE) vehicles, EVs can minimize carbon emissions and potentially achieve autonomous driving. However, several obstacles hinder the widespread adoption of EVs, such as their constrained driving range and the extended time required for charging. One alternative solution to address these challenges is implementing dynamic wireless power transfer (DWPT), charging EVs in motion on the road. Moreover, charging stations with static wireless power transfer (SWPT) infrastructure can replace existing gas stations, enabling users to charge EVs in parking lots or at home. This paper surveys the communication infrastructure for static and dynamic wireless charging in electric vehicles. It encompasses all communication aspects involved in the wireless charging process. The architecture and communication requirements for static and dynamic wireless charging are presented separately. Additionally, a comprehensive comparison of existing communication standards is provided. The communication with the grid is also explored in detail. The survey gives attention to security and privacy issues arising during communications. In summary, the paper addresses the challenges and outlines upcoming trends in communication for EV wireless charging.
U-Mixer: An Unet-Mixer Architecture with Stationarity Correction for Time Series Forecasting
Jan 04, 2024



Time series forecasting is a crucial task in various domains. Caused by factors such as trends, seasonality, or irregular fluctuations, time series often exhibits non-stationary. It obstructs stable feature propagation through deep layers, disrupts feature distributions, and complicates learning data distribution changes. As a result, many existing models struggle to capture the underlying patterns, leading to degraded forecasting performance. In this study, we tackle the challenge of non-stationarity in time series forecasting with our proposed framework called U-Mixer. By combining Unet and Mixer, U-Mixer effectively captures local temporal dependencies between different patches and channels separately to avoid the influence of distribution variations among channels, and merge low- and high-levels features to obtain comprehensive data representations. The key contribution is a novel stationarity correction method, explicitly restoring data distribution by constraining the difference in stationarity between the data before and after model processing to restore the non-stationarity information, while ensuring the temporal dependencies are preserved. Through extensive experiments on various real-world time series datasets, U-Mixer demonstrates its effectiveness and robustness, and achieves 14.5\% and 7.7\% improvements over state-of-the-art (SOTA) methods.
Precise Coil Alignment for Dynamic Wireless Charging of Electric Vehicles with RFID Sensing
Dec 19, 2023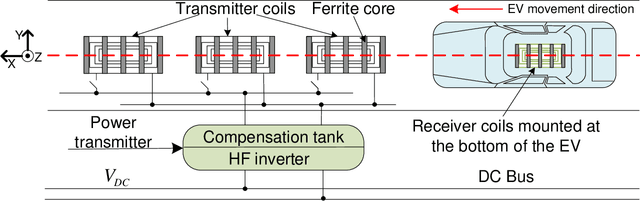
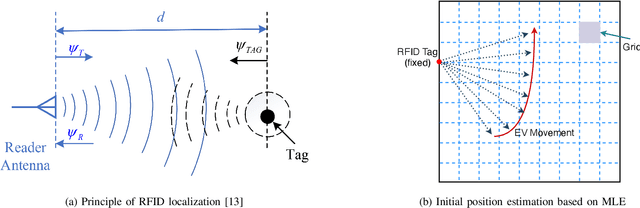
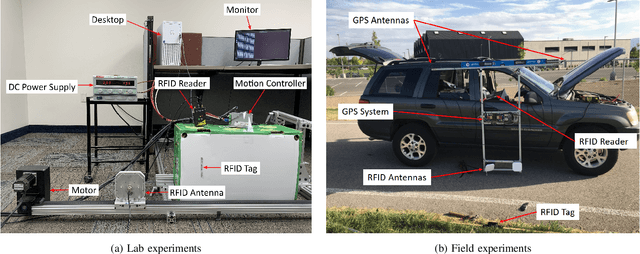
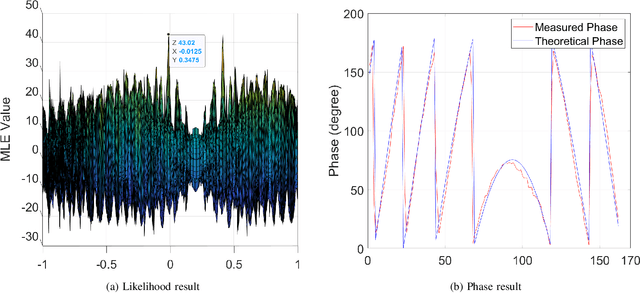
Electric vehicle (EV) has emerged as a transformative force for the sustainable and environmentally friendly future. To alleviate range anxiety caused by battery and charging facility, dynamic wireless power transfer (DWPT) is increasingly recognized as a key enabler for widespread EV adoption, yet it faces significant technical challenges, primarily in precise coil alignment. This article begins by reviewing current alignment methodologies and evaluates their advantages and limitations. We observe that achieving the necessary alignment precision is challenging with these existing methods. To address this, we present an innovative RFID-based DWPT coil alignment system, utilizing coherent phase detection and a maximum likelihood estimation algorithm, capable of achieving sub-10 cm accuracy. This system's efficacy in providing both lateral and vertical misalignment estimates has been verified through laboratory and experimental tests. We also discuss potential challenges in broader system implementation and propose corresponding solutions. This research offers a viable and promising solution for enhancing DWPT efficiency.
MPR-Net:Multi-Scale Pattern Reproduction Guided Universality Time Series Interpretable Forecasting
Jul 13, 2023



Time series forecasting has received wide interest from existing research due to its broad applications and inherent challenging. The research challenge lies in identifying effective patterns in historical series and applying them to future forecasting. Advanced models based on point-wise connected MLP and Transformer architectures have strong fitting power, but their secondary computational complexity limits practicality. Additionally, those structures inherently disrupt the temporal order, reducing the information utilization and making the forecasting process uninterpretable. To solve these problems, this paper proposes a forecasting model, MPR-Net. It first adaptively decomposes multi-scale historical series patterns using convolution operation, then constructs a pattern extension forecasting method based on the prior knowledge of pattern reproduction, and finally reconstructs future patterns into future series using deconvolution operation. By leveraging the temporal dependencies present in the time series, MPR-Net not only achieves linear time complexity, but also makes the forecasting process interpretable. By carrying out sufficient experiments on more than ten real data sets of both short and long term forecasting tasks, MPR-Net achieves the state of the art forecasting performance, as well as good generalization and robustness performance.