 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIG-Search: Step-Level Information Gain Rewards for Search-Augmented Reasoning
Apr 16, 2026Reinforcement learning has emerged as an effective paradigm for training large language models to perform search-augmented reasoning. However, existing approaches rely on trajectory-level rewards that cannot distinguish precise search queries from vague or redundant ones within a rollout group, and collapse to a near-zero gradient signal whenever every sampled trajectory fails. In this paper, we propose IG-Search, a reinforcement learning framework that introduces a step-level reward based on Information Gain (IG). For each search step, IG measures how much the retrieved documents improve the model's confidence in the gold answer relative to a counterfactual baseline of random documents, thereby reflecting the effectiveness of the underlying search query. This signal is fed back to the corresponding search-query tokens via per-token advantage modulation in GRPO, enabling fine-grained, step-level credit assignment within a rollout. Unlike prior step-level methods that require either externally annotated intermediate supervision or shared environment states across trajectories, IG-Search derives its signals from the policy's own generation probabilities, requiring no intermediate annotations beyond standard question-answer pairs. Experiments on seven single-hop and multi-hop QA benchmarks demonstrate that IG-Search achieves an average EM of 0.430 with Qwen2.5-3B, outperforming the strongest trajectory-level baseline (MR-Search) by 1.6 points and the step-level method GiGPO by 0.9 points on average across benchmarks, with particularly pronounced gains on multi-hop reasoning tasks. Despite introducing a dense step-level signal, IG-Search adds only ~6.4% to per-step training wall-clock time over the trajectory-level baseline and leaves inference latency unchanged, while still providing a meaningful gradient signal even when every sampled trajectory answers incorrectly.
OneSearch-V2: The Latent Reasoning Enhanced Self-distillation Generative Search Framework
Mar 25, 2026Generative Retrieval (GR) has emerged as a promising paradigm for modern search systems. Compared to multi-stage cascaded architecture, it offers advantages such as end-to-end joint optimization and high computational efficiency. OneSearch, as a representative industrial-scale deployed generative search framework, has brought significant commercial and operational benefits. However, its inadequate understanding of complex queries, inefficient exploitation of latent user intents, and overfitting to narrow historical preferences have limited its further performance improvement. To address these challenges, we propose \textbf{OneSearch-V2}, a latent reasoning enhanced self-distillation generative search framework. It contains three key innovations: (1) a thought-augmented complex query understanding module, which enables deep query understanding and overcomes the shallow semantic matching limitations of direct inference; (2) a reasoning-internalized self-distillation training pipeline, which uncovers users' potential yet precise e-commerce intentions beyond log-fitting through implicit in-context learning; (3) a behavior preference alignment optimization system, which mitigates reward hacking arising from the single conversion metric, and addresses personal preference via direct user feedback. Extensive offline evaluations demonstrate OneSearch-V2's strong query recognition and user profiling capabilities. Online A/B tests further validate its business effectiveness, yielding +3.98\% item CTR, +3.05\% buyer conversion rate, and +2.11\% order volume. Manual evaluation further confirms gains in search experience quality, with +1.65\% in page good rate and +1.37\% in query-item relevance. More importantly, OneSearch-V2 effectively mitigates common search system issues such as information bubbles and long-tail sparsity, without incurring additional inference costs or serving latency.
KuaiSearch: A Large-Scale E-Commerce Search Dataset for Recall, Ranking, and Relevance
Feb 12, 2026E-commerce search serves as a central interface, connecting user demands with massive product inventories and plays a vital role in our daily lives. However, in real-world applications, it faces challenges, including highly ambiguous queries, noisy product texts with weak semantic order, and diverse user preferences, all of which make it difficult to accurately capture user intent and fine-grained product semantics. In recent years, significant advances in large language models (LLMs) for semantic representation and contextual reasoning have created new opportunities to address these challenges. Nevertheless, existing e-commerce search datasets still suffer from notable limitations: queries are often heuristically constructed, cold-start users and long-tail products are filtered out, query and product texts are anonymized, and most datasets cover only a single stage of the search pipeline. Collectively, these issues constrain research on LLM-based e-commerce search. To address these challenges, we construct and release KuaiSearch. To the best of our knowledge, it is the largest e-commerce search dataset currently available. KuaiSearch is built upon real user search interactions from the Kuaishou platform, preserving authentic user queries and natural-language product texts, covering cold-start users and long-tail products, and systematically spanning three key stages of the search pipeline: recall, ranking, and relevance judgment. We conduct a comprehensive analysis of KuaiSearch from multiple perspectives, including products, users, and queries, and establish benchmark experiments across several representative search tasks. Experimental results demonstrate that KuaiSearch provides a valuable foundation for research on real-world e-commerce search.
CSMCIR: CoT-Enhanced Symmetric Alignment with Memory Bank for Composed Image Retrieval
Jan 07, 2026Composed Image Retrieval (CIR) enables users to search for target images using both a reference image and manipulation text, offering substantial advantages over single-modality retrieval systems. However, existing CIR methods suffer from representation space fragmentation: queries and targets comprise heterogeneous modalities and are processed by distinct encoders, forcing models to bridge misaligned representation spaces only through post-hoc alignment, which fundamentally limits retrieval performance. This architectural asymmetry manifests as three distinct, well-separated clusters in the feature space, directly demonstrating how heterogeneous modalities create fundamentally misaligned representation spaces from initialization. In this work, we propose CSMCIR, a unified representation framework that achieves efficient query-target alignment through three synergistic components. First, we introduce a Multi-level Chain-of-Thought (MCoT) prompting strategy that guides Multimodal Large Language Models to generate discriminative, semantically compatible captions for target images, establishing modal symmetry. Building upon this, we design a symmetric dual-tower architecture where both query and target sides utilize the identical shared-parameter Q-Former for cross-modal encoding, ensuring consistent feature representations and further reducing the alignment gap. Finally, this architectural symmetry enables an entropy-based, temporally dynamic Memory Bank strategy that provides high-quality negative samples while maintaining consistency with the evolving model state. Extensive experiments on four benchmark datasets demonstrate that our CSMCIR achieves state-of-the-art performance with superior training efficiency. Comprehensive ablation studies further validate the effectiveness of each proposed component.
Terahertz Signal Coverage Enhancement in Hall Scenarios Based on Single-Hop and Dual-Hop Reconfigurable Intelligent Surfaces
Dec 16, 2025Terahertz (THz) communication offers ultra-high data rates and has emerged as a promising technology for future wireless networks. However, the inherently high free-space path loss of THz waves significantly limits the coverage range of THz communication systems. Therefore, extending the effective coverage area is a key challenge for the practical deployment of THz networks. Reconfigurable intelligent surfaces (RIS), which can dynamically manipulate electromagnetic wave propagation, provide a solution to enhance THz coverage. To investigate multi-RIS deployment scenarios, this work integrates an antenna array-based RIS model into the ray-tracing simulation platform. Using an indoor hall as a representative case study, the enhancement effects of single-hop and dual-hop RIS configurations on indoor signal coverage are evaluated under various deployment schemes. The developed framework offers valuable insights and design references for optimizing RIS-assisted indoor THz communication and coverage estimation.
SMILE: SeMantic Ids Enhanced CoLd Item Representation for Click-through Rate Prediction in E-commerce SEarch
Oct 14, 2025



With the rise of modern search and recommendation platforms, insufficient collaborative information of cold-start items exacerbates the Matthew effect of existing platform items, challenging platform diversity and becoming a longstanding issue. Existing methods align items' side content with collaborative information to transfer collaborative signals from high-popularity items to cold-start items. However, these methods fail to account for the asymmetry between collaboration and content, nor the fine-grained differences among items. To address these issues, we propose SMILE, an item representation enhancement approach based on fused alignment of semantic IDs. Specifically, we use RQ-OPQ encoding to quantize item content and collaborative information, followed by a two-step alignment: RQ encoding transfers shared collaborative signals across items, while OPQ encoding learns differentiated information of items. Comprehensive offline experiments on large-scale industrial datasets demonstrate superiority of SMILE, and rigorous online A/B tests confirm statistically significant improvements: item CTR +1.66%, buyers +1.57%, and order volume +2.17%.
InfoGain-RAG: Boosting Retrieval-Augmented Generation via Document Information Gain-based Reranking and Filtering
Sep 16, 2025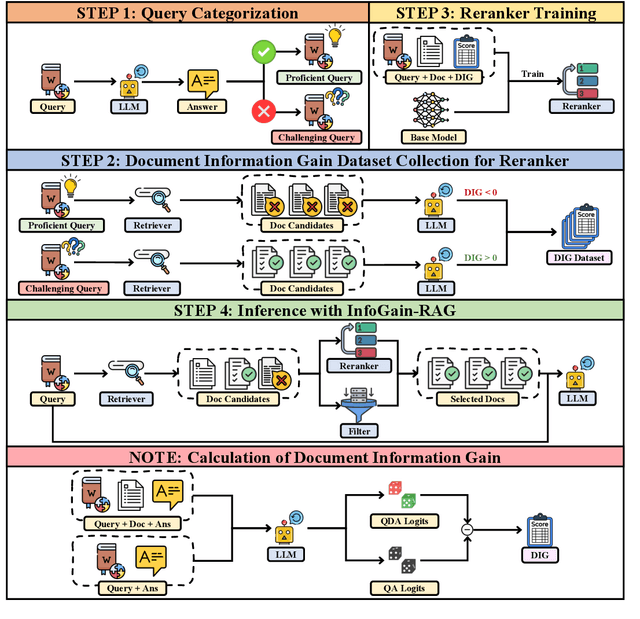
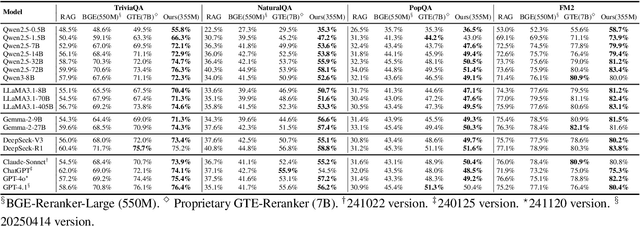
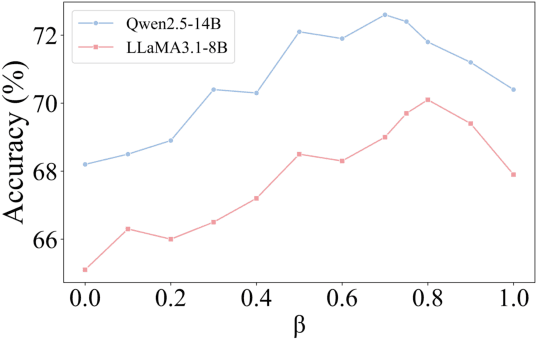
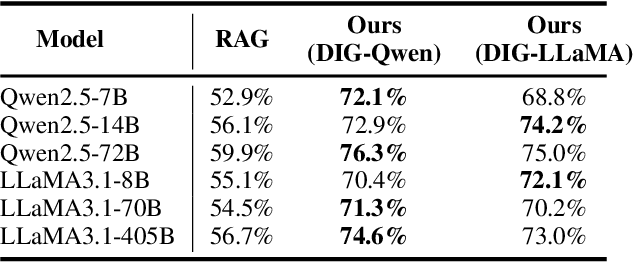
Retrieval-Augmented Generation (RAG) has emerged as a promising approach to address key limitations of Large Language Models (LLMs), such as hallucination, outdated knowledge, and lacking reference. However, current RAG frameworks often struggle with identifying whether retrieved documents meaningfully contribute to answer generation. This shortcoming makes it difficult to filter out irrelevant or even misleading content, which notably impacts the final performance. In this paper, we propose Document Information Gain (DIG), a novel metric designed to quantify the contribution of retrieved documents to correct answer generation. DIG measures a document's value by computing the difference of LLM's generation confidence with and without the document augmented. Further, we introduce InfoGain-RAG, a framework that leverages DIG scores to train a specialized reranker, which prioritizes each retrieved document from exact distinguishing and accurate sorting perspectives. This approach can effectively filter out irrelevant documents and select the most valuable ones for better answer generation. Extensive experiments across various models and benchmarks demonstrate that InfoGain-RAG can significantly outperform existing approaches, on both single and multiple retrievers paradigm. Specifically on NaturalQA, it achieves the improvements of 17.9%, 4.5%, 12.5% in exact match accuracy against naive RAG, self-reflective RAG and modern ranking-based RAG respectively, and even an average of 15.3% increment on advanced proprietary model GPT-4o across all datasets. These results demonstrate the feasibility of InfoGain-RAG as it can offer a reliable solution for RAG in multiple applications.
OneSug: The Unified End-to-End Generative Framework for E-commerce Query Suggestion
Jun 07, 2025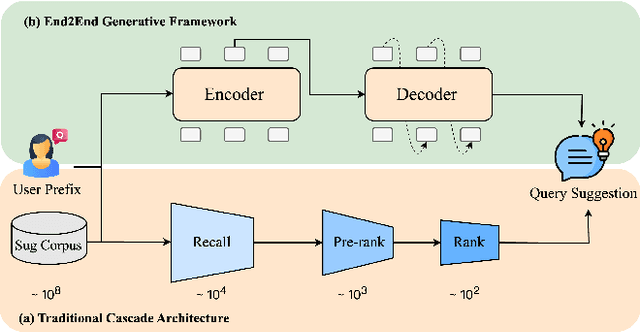

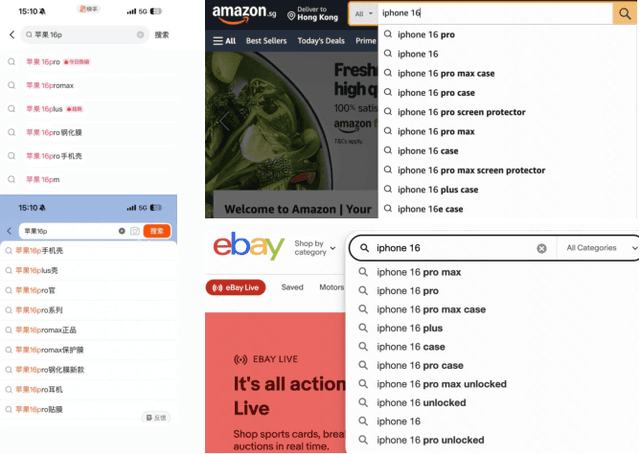
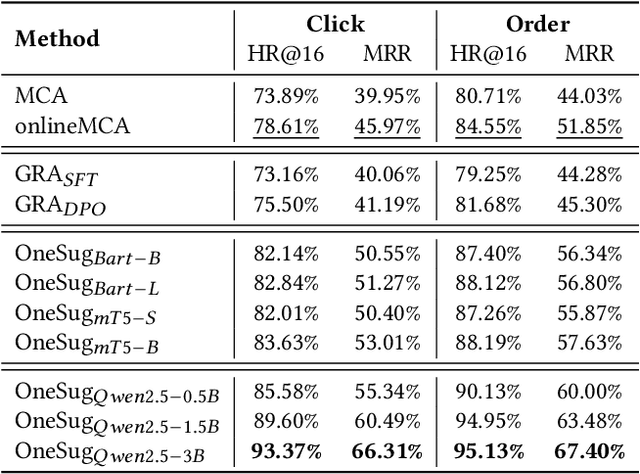
Query suggestion plays a crucial role in enhancing user experience in e-commerce search systems by providing relevant query recommendations that align with users' initial input. This module helps users navigate towards personalized preference needs and reduces typing effort, thereby improving search experience. Traditional query suggestion modules usually adopt multi-stage cascading architectures, for making a well trade-off between system response time and business conversion. But they often suffer from inefficiencies and suboptimal performance due to inconsistent optimization objectives across stages. To address these, we propose OneSug, the first end-to-end generative framework for e-commerce query suggestion. OneSug incorporates a prefix2query representation enhancement module to enrich prefixes using semantically and interactively related queries to bridge content and business characteristics, an encoder-decoder generative model that unifies the query suggestion process, and a reward-weighted ranking strategy with behavior-level weights to capture fine-grained user preferences. Extensive evaluations on large-scale industry datasets demonstrate OneSug's ability for effective and efficient query suggestion. Furthermore, OneSug has been successfully deployed for the entire traffic on the e-commerce search engine in Kuaishou platform for over 1 month, with statistically significant improvements in user top click position (-9.33%), CTR (+2.01%), Order (+2.04%), and Revenue (+1.69%) over the online multi-stage strategy, showing great potential in e-commercial conversion.
Use Cases for Terahertz Communications: An Industrial Perspective
Jan 07, 2025



Thanks to the vast amount of available resources and unique propagation properties, terahertz (THz) frequency bands are viewed as a key enabler for achieving ultrahigh communication performance and precise sensing capabilities in future wireless systems. Recently, the European Telecommunications Standards Institute (ETSI) initiated an Industry Specification Group (ISG) on THz which aims at establishing the technical foundation for subsequent standardization of this technology, which is pivotal for its successful integration into future networks. Starting from the work recently finalized within this group, this paper provides an industrial perspective on potential use cases and frequency bands of interest for THz communication systems. We first identify promising frequency bands in the 100 GHz - 1 THz range, offering over 500 GHz of available spectrum that can be exploited to unlock the full potential of THz communications. Then, we present key use cases and application areas for THz communications, emphasizing the role of this technology and its advantages over other frequency bands. We discuss their target requirements and show that some applications demand for multi-Tbps data rates, latency below 0.5 ms, and sensing accuracy down to 0.5 cm. Additionally, we identify the main deployment scenarios and outline other enabling technologies crucial for overcoming the challenges faced by THz system. Finally, we summarize the past and ongoing standardization efforts focusing on THz communications, while also providing an outlook towards the inclusion of this technology as an integral part of the future sixth generation (6G) and beyond communication networks.
MoDULA: Mixture of Domain-Specific and Universal LoRA for Multi-Task Learning
Dec 10, 2024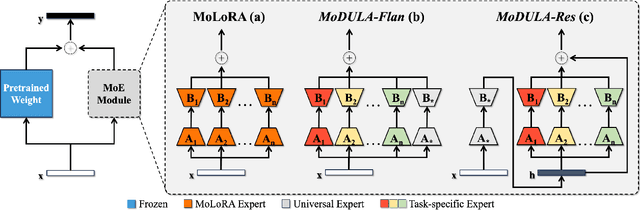
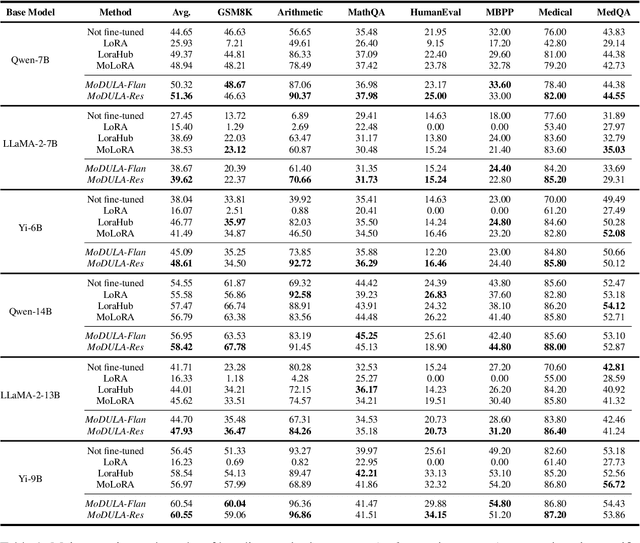
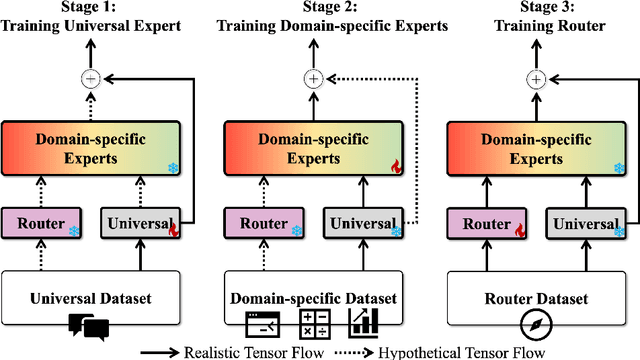
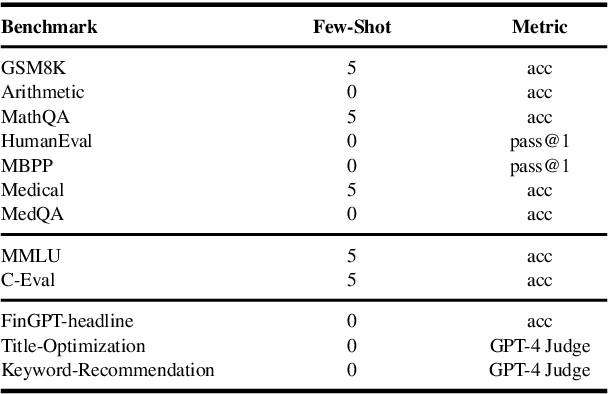
The growing demand for larger-scale models in the development of \textbf{L}arge \textbf{L}anguage \textbf{M}odels (LLMs) poses challenges for efficient training within limited computational resources. Traditional fine-tuning methods often exhibit instability in multi-task learning and rely heavily on extensive training resources. Here, we propose MoDULA (\textbf{M}ixture \textbf{o}f \textbf{D}omain-Specific and \textbf{U}niversal \textbf{L}oR\textbf{A}), a novel \textbf{P}arameter \textbf{E}fficient \textbf{F}ine-\textbf{T}uning (PEFT) \textbf{M}ixture-\textbf{o}f-\textbf{E}xpert (MoE) paradigm for improved fine-tuning and parameter efficiency in multi-task learning. The paradigm effectively improves the multi-task capability of the model by training universal experts, domain-specific experts, and routers separately. MoDULA-Res is a new method within the MoDULA paradigm, which maintains the model's general capability by connecting universal and task-specific experts through residual connections. The experimental results demonstrate that the overall performance of the MoDULA-Flan and MoDULA-Res methods surpasses that of existing fine-tuning methods on various LLMs. Notably, MoDULA-Res achieves more significant performance improvements in multiple tasks while reducing training costs by over 80\% without losing general capability. Moreover, MoDULA displays flexible pluggability, allowing for the efficient addition of new tasks without retraining existing experts from scratch. This progressive training paradigm circumvents data balancing issues, enhancing training efficiency and model stability. Overall, MoDULA provides a scalable, cost-effective solution for fine-tuning LLMs with enhanced parameter efficiency and generalization capability.