 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Perception vs. Distortion Perspective on Score-Based Generative Channel Estimation
Jun 15, 2026Driven by their remarkable success in computer vision and inverse problem solving, score-based models are increasingly applied to wireless communications, where they show promise across a range of physical-layer tasks. However, despite this growing interest, the current literature often lacks a rigorous analysis of when score-matching offers a tangible advantage over traditional discriminative learning. This paper aims to address this gap through the use-case of channel estimation, a fundamental inverse problem in wireless systems. We present a theoretically grounded interpretation of score-based channel estimation through the lens of the perception-distortion tradeoff, identifying the conditions where score matching excels as well as its key limitations. In particular, by modeling downstream wireless tasks (e.g., capacity maximization) as functionals of the channel estimation process, we quantify the excess risk incurred by standard distortion-minimization approaches. Extensive numerical results show that under high predictive uncertainty, the large excess risk gap can be offset by score-based estimation, enabling near Bayesian-optimal precoding via the learned posterior, whereas in the low predictive uncertainty regime, discriminative distortion-minimization approaches are preferable due to lower complexity and more efficient use of model capacity.
Use Cases for Terahertz Communications: An Industrial Perspective
Jan 07, 2025



Thanks to the vast amount of available resources and unique propagation properties, terahertz (THz) frequency bands are viewed as a key enabler for achieving ultrahigh communication performance and precise sensing capabilities in future wireless systems. Recently, the European Telecommunications Standards Institute (ETSI) initiated an Industry Specification Group (ISG) on THz which aims at establishing the technical foundation for subsequent standardization of this technology, which is pivotal for its successful integration into future networks. Starting from the work recently finalized within this group, this paper provides an industrial perspective on potential use cases and frequency bands of interest for THz communication systems. We first identify promising frequency bands in the 100 GHz - 1 THz range, offering over 500 GHz of available spectrum that can be exploited to unlock the full potential of THz communications. Then, we present key use cases and application areas for THz communications, emphasizing the role of this technology and its advantages over other frequency bands. We discuss their target requirements and show that some applications demand for multi-Tbps data rates, latency below 0.5 ms, and sensing accuracy down to 0.5 cm. Additionally, we identify the main deployment scenarios and outline other enabling technologies crucial for overcoming the challenges faced by THz system. Finally, we summarize the past and ongoing standardization efforts focusing on THz communications, while also providing an outlook towards the inclusion of this technology as an integral part of the future sixth generation (6G) and beyond communication networks.
White Paper on Radio Channel Modeling and Prediction to Support Future Environment-aware Wireless Communication Systems
Sep 29, 2023COST INTERACT working group (WG)1 aims at increasing the theoretical and experimental understanding of radio propagation and channels in environments of interest and at deriving models for design, simulation, planning and operation of future wireless systems. Wide frequency ranges from sub-GHz to terahertz (THz), potentially high mobility, diverse and highly cluttered environments, dense networks, massive antenna systems, and the use of intelligent surfaces, are some of the challenges for radio channel measurements and modeling for next generation systems. As indicated in [1], with increased number of use cases (e.g., those identified by one6G [2] and shown in Fig. 1) to be supported and a larger number of frequency bands, a paradigm shift in channel measurements and modeling will be required. To address the particular challenges that come with such a paradigm shift, WG1 started the work on relevant topics, ranging from channel sounder design, metrology and measurement methodologies, measurements, modeling, and systematic dataset collection and analysis. In addition to the core activities of WG1, based on the strong interest of the participants, two sub-working groups (subWGs) have been initiated as part of WG1: i) subWG1.1 on millimeter-wave (mmWave) and THz sounding (subWG THz) and ii) subWG1.2 on propagation aspects related to reconfigurable intelligent surfaces (RIS) (subWG RIS). This white paper has two main goals: i) it summarizes the state-of-theart in radio channel measurement and modeling and the key challenges that the scientific community will have to face over the next years to support the development of 6G networks, as identified by WG1 and its subWGs; and ii) it charts the main directions for the work of WG1 and subWGs for the remainder of COST INTERACT duration (i.e., until October 2025).
Scheduling Out-of-Coverage Vehicular Communications Using Reinforcement Learning
Jul 13, 2022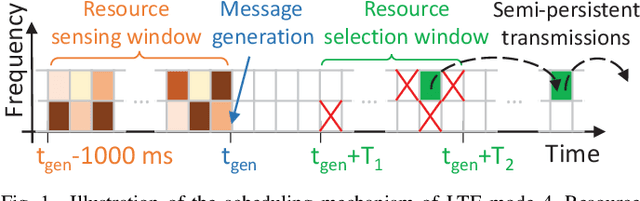
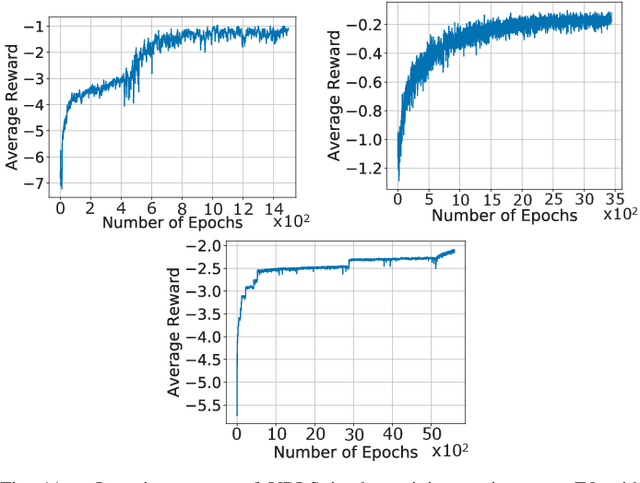
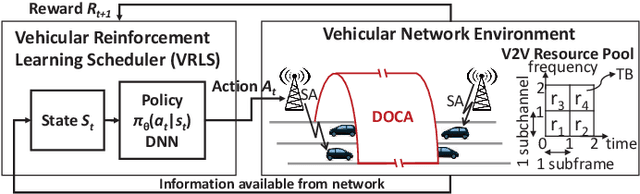
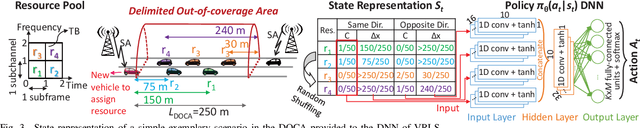
Performance of vehicle-to-vehicle (V2V) communications depends highly on the employed scheduling approach. While centralized network schedulers offer high V2V communication reliability, their operation is conventionally restricted to areas with full cellular network coverage. In contrast, in out-of-cellular-coverage areas, comparatively inefficient distributed radio resource management is used. To exploit the benefits of the centralized approach for enhancing the reliability of V2V communications on roads lacking cellular coverage, we propose VRLS (Vehicular Reinforcement Learning Scheduler), a centralized scheduler that proactively assigns resources for out-of-coverage V2V communications \textit{before} vehicles leave the cellular network coverage. By training in simulated vehicular environments, VRLS can learn a scheduling policy that is robust and adaptable to environmental changes, thus eliminating the need for targeted (re-)training in complex real-life environments. We evaluate the performance of VRLS under varying mobility, network load, wireless channel, and resource configurations. VRLS outperforms the state-of-the-art distributed scheduling algorithm in zones without cellular network coverage by reducing the packet error rate by half in highly loaded conditions and achieving near-maximum reliability in low-load scenarios.
Artificial Intelligence in Vehicular Wireless Networks: A Case Study Using ns-3
Mar 10, 2022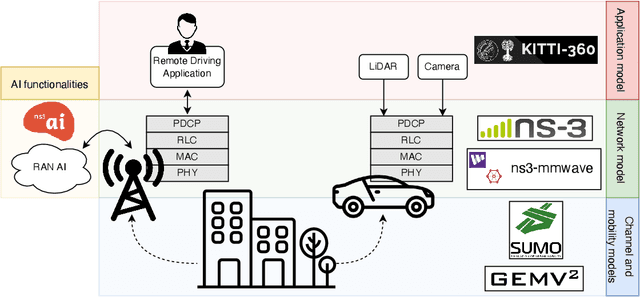
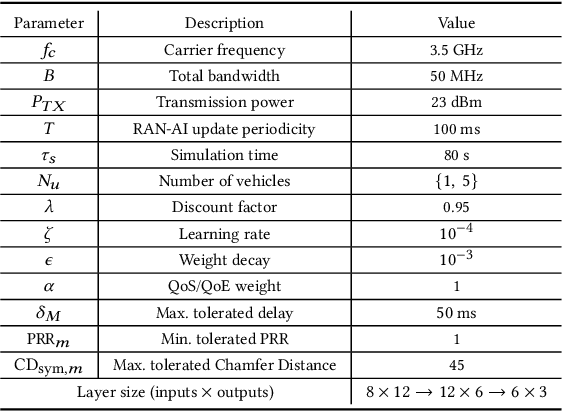
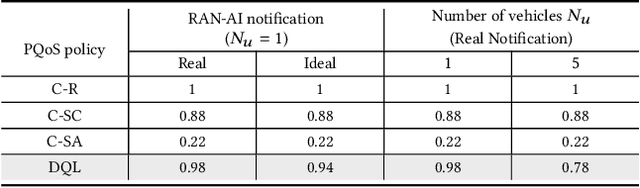
Artificial intelligence (AI) techniques have emerged as a powerful approach to make wireless networks more efficient and adaptable. In this paper we present an ns-3 simulation framework, able to implement AI algorithms for the optimization of wireless networks. Our pipeline consists of: (i) a new geometry-based mobility-dependent channel model for V2X; (ii) all the layers of a 5G-NR-compliant protocol stack, based on the ns3-mmwave module; (iii) a new application to simulate V2X data transmission, and (iv) a new intelligent entity for the control of the network via AI. Thanks to its flexible and modular design, researchers can use this tool to implement, train, and evaluate their own algorithms in a realistic and controlled environment. We test the behavior of our framework in a Predictive Quality of Service (PQoS) scenario, where AI functionalities are implemented using Reinforcement Learning (RL), and demonstrate that it promotes better network optimization compared to baseline solutions that do not implement AI.
A Reinforcement Learning Framework for PQoS in a Teleoperated Driving Scenario
Feb 04, 2022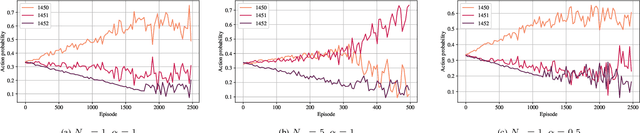
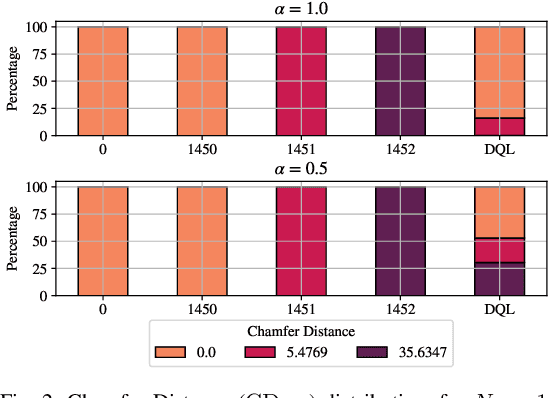
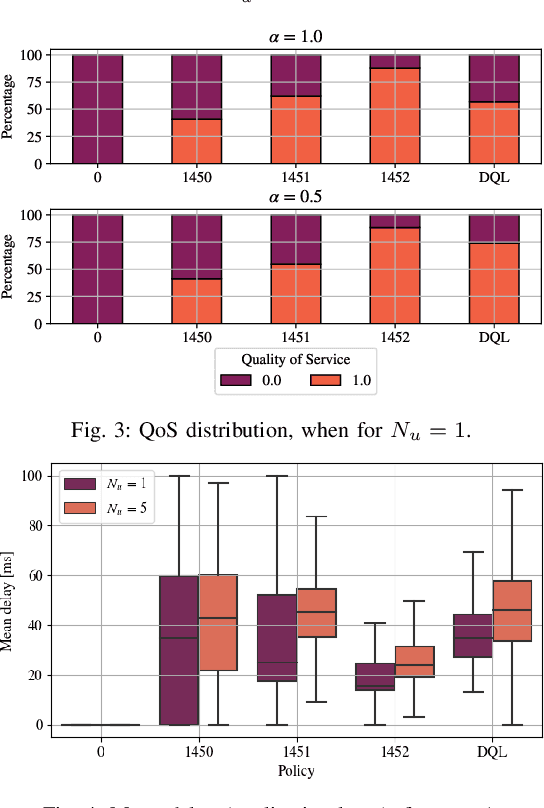
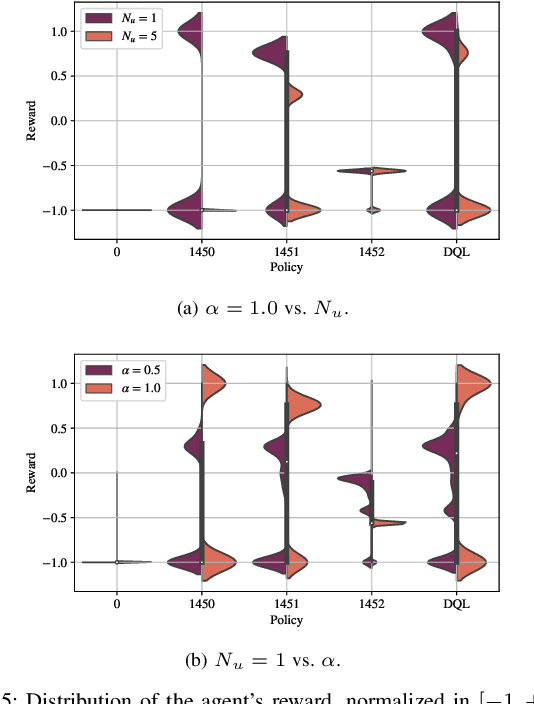
In recent years, autonomous networks have been designed with Predictive Quality of Service (PQoS) in mind, as a means for applications operating in the industrial and/or automotive sectors to predict unanticipated Quality of Service (QoS) changes and react accordingly. In this context, Reinforcement Learning (RL) has come out as a promising approach to perform accurate predictions, and optimize the efficiency and adaptability of wireless networks. Along these lines, in this paper we propose the design of a new entity, implemented at the RAN-level that, with the support of an RL framework, implements PQoS functionalities. Specifically, we focus on the design of the reward function of the learning agent, able to convert QoS estimates into appropriate countermeasures if QoS requirements are not satisfied. We demonstrate via ns-3 simulations that our approach achieves the best trade-off in terms of QoS and Quality of Experience (QoE) performance of end users in a teleoperated-driving-like scenario, compared to other baseline solutions.
Predictive Quality of Service (PQoS): The Next Frontier for Fully Autonomous Systems
Sep 20, 2021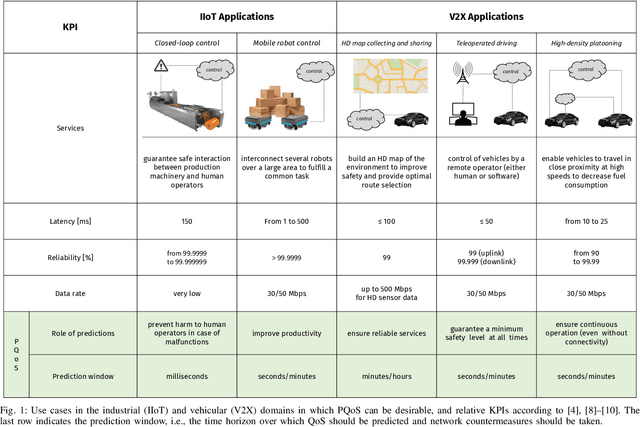
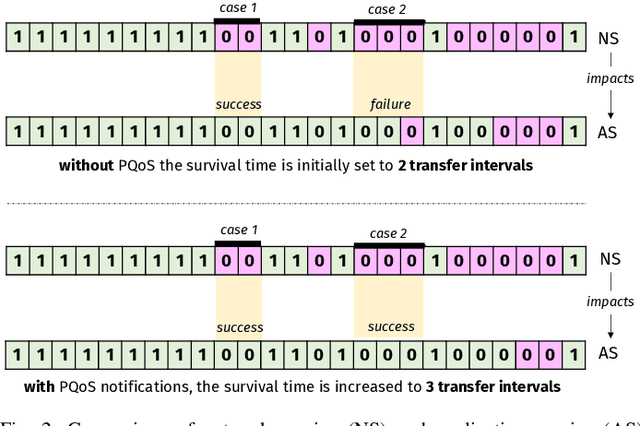
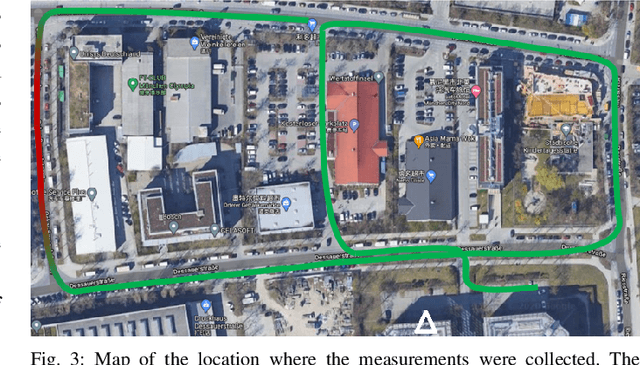
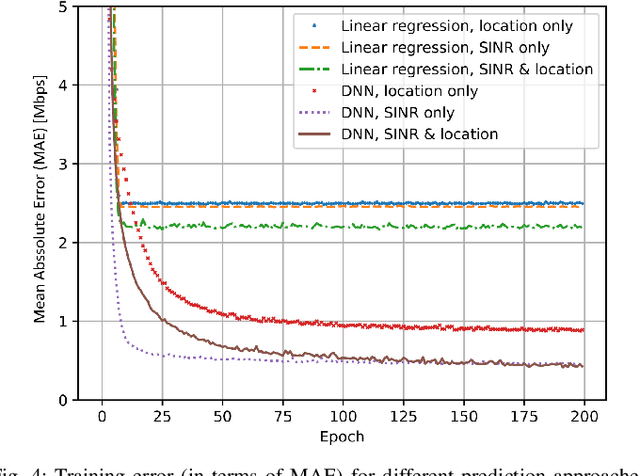
Recent advances in software, hardware, computing and control have fueled significant progress in the field of autonomous systems. Notably, autonomous machines should continuously estimate how the scenario in which they move and operate will evolve within a predefined time frame, and foresee whether or not the network will be able to fulfill the agreed Quality of Service (QoS). If not, appropriate countermeasures should be taken to satisfy the application requirements. Along these lines, in this paper we present possible methods to enable predictive QoS (PQoS) in autonomous systems, and discuss which use cases will particularly benefit from network prediction. Then, we shed light on the challenges in the field that are still open for future research. As a case study, we demonstrate whether machine learning can facilitate PQoS in a teleoperated-driving-like use case, as a function of different measurement signals.
A Tutorial on 5G NR V2X Communications
Feb 08, 2021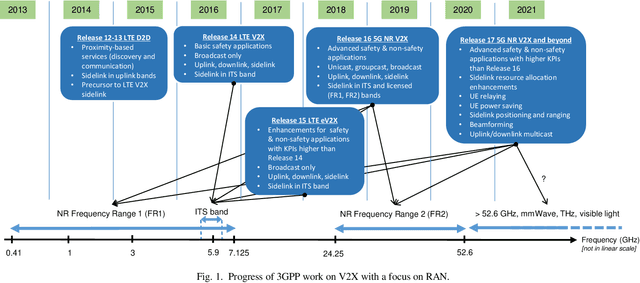
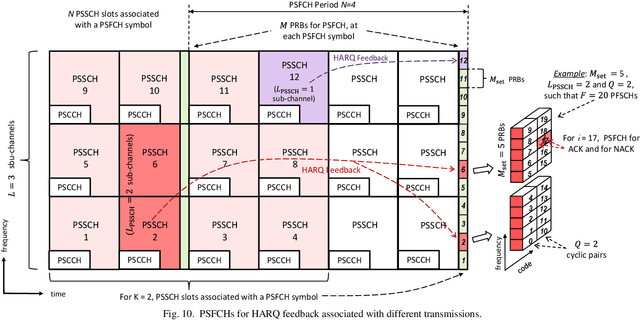
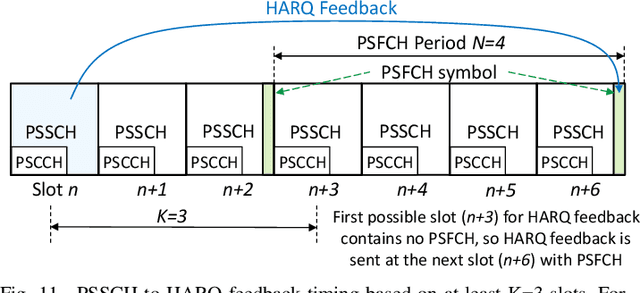
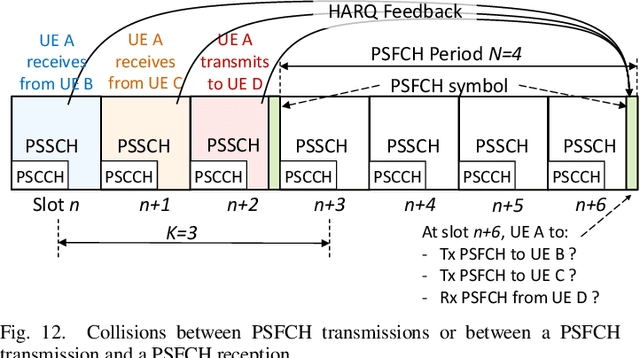
The Third Generation Partnership Project (3GPP) has recently published its Release 16 that includes the first Vehicle to-Everything (V2X) standard based on the 5G New Radio (NR) air interface. 5G NR V2X introduces advanced functionalities on top of the 5G NR air interface to support connected and automated driving use cases with stringent requirements. This paper presents an in-depth tutorial of the 3GPP Release 16 5G NR V2X standard for V2X communications, with a particular focus on the sidelink, since it is the most significant part of 5G NR V2X. The main part of the paper is an in-depth treatment of the key aspects of 5G NR V2X: the physical layer, the resource allocation, the quality of service management, the enhancements introduced to the Uu interface and the mobility management for V2N (Vehicle to Network) communications, as well as the co-existence mechanisms between 5G NR V2X and LTE V2X. We also review the use cases, the system architecture, and describe the evaluation methodology and simulation assumptions for 5G NR V2X. Finally, we provide an outlook on possible 5G NR V2X enhancements, including those identified within Release 17.
VRLS: A Unified Reinforcement Learning Scheduler for Vehicle-to-Vehicle Communications
Jul 22, 2019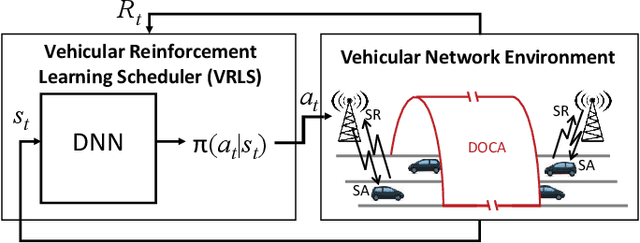
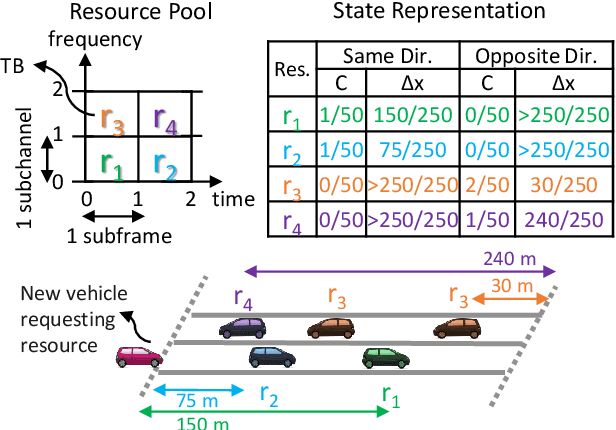
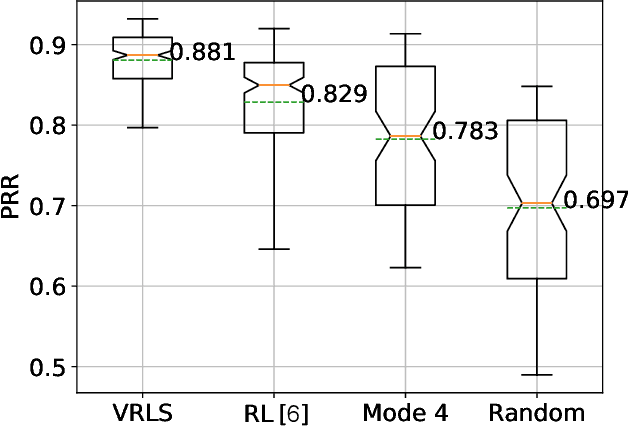
Vehicle-to-vehicle (V2V) communications have distinct challenges that need to be taken into account when scheduling the radio resources. Although centralized schedulers (e.g., located on base stations) could be utilized to deliver high scheduling performance, they cannot be employed in case of coverage gaps. To address the issue of reliable scheduling of V2V transmissions out of coverage, we propose Vehicular Reinforcement Learning Scheduler (VRLS), a centralized scheduler that predictively assigns the resources for V2V communication while the vehicle is still in cellular network coverage. VRLS is a unified reinforcement learning (RL) solution, wherein the learning agent, the state representation, and the reward provided to the agent are applicable to different vehicular environments of interest (in terms of vehicular density, resource configuration, and wireless channel conditions). Such a unified solution eliminates the necessity of redesigning the RL components for a different environment, and facilitates transfer learning from one to another similar environment. We evaluate the performance of VRLS and show its ability to avoid collisions and half-duplex errors, and to reuse the resources better than the state of the art scheduling algorithms. We also show that pre-trained VRLS agent can adapt to different V2V environments with limited retraining, thus enabling real-world deployment in different scenarios.
Reinforcement Learning Scheduler for Vehicle-to-Vehicle Communications Outside Coverage
Apr 29, 2019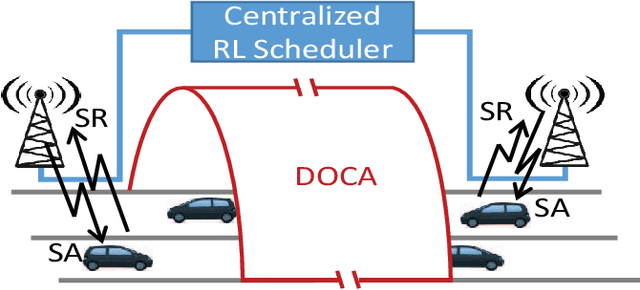
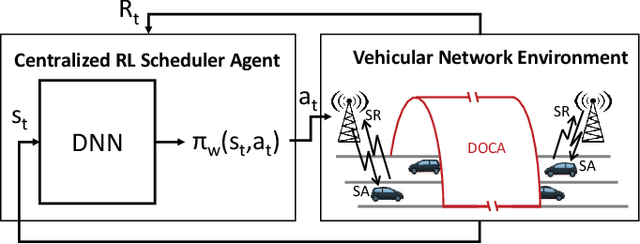
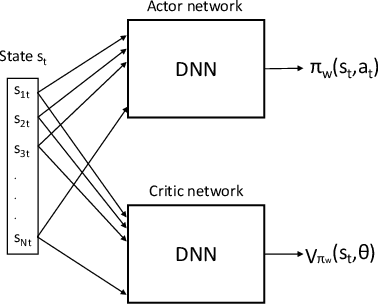
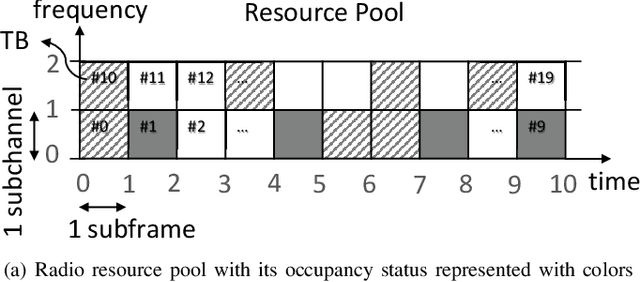
Radio resources in vehicle-to-vehicle (V2V) communication can be scheduled either by a centralized scheduler residing in the network (e.g., a base station in case of cellular systems) or a distributed scheduler, where the resources are autonomously selected by the vehicles. The former approach yields a considerably higher resource utilization in case the network coverage is uninterrupted. However, in case of intermittent or out-of-coverage, due to not having input from centralized scheduler, vehicles need to revert to distributed scheduling. Motivated by recent advances in reinforcement learning (RL), we investigate whether a centralized learning scheduler can be taught to efficiently pre-assign the resources to vehicles for out-of-coverage V2V communication. Specifically, we use the actor-critic RL algorithm to train the centralized scheduler to provide non-interfering resources to vehicles before they enter the out-of-coverage area. Our initial results show that a RL-based scheduler can achieve performance as good as or better than the state-of-art distributed scheduler, often outperforming it. Furthermore, the learning process completes within a reasonable time (ranging from a few hundred to a few thousand epochs), thus making the RL-based scheduler a promising solution for V2V communications with intermittent network coverage.