 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Reinforcement Learning over Wireless Networks with Homomorphic State Representations
Aug 11, 2025In this work, we address the problem of training Reinforcement Learning (RL) agents over communication networks. The RL paradigm requires the agent to instantaneously perceive the state evolution to infer the effects of its actions on the environment. This is impossible if the agent receives state updates over lossy or delayed wireless systems and thus operates with partial and intermittent information. In recent years, numerous frameworks have been proposed to manage RL with imperfect feedback; however, they often offer specific solutions with a substantial computational burden. To address these limits, we propose a novel architecture, named Homomorphic Robust Remote Reinforcement Learning (HR3L), that enables the training of remote RL agents exchanging observations across a non-ideal wireless channel. HR3L considers two units: the transmitter, which encodes meaningful representations of the environment, and the receiver, which decodes these messages and performs actions to maximize a reward signal. Importantly, HR3L does not require the exchange of gradient information across the wireless channel, allowing for quicker training and a lower communication overhead than state-of-the-art solutions. Experimental results demonstrate that HR3L significantly outperforms baseline methods in terms of sample efficiency and adapts to different communication scenarios, including packet losses, delayed transmissions, and capacity limitations.
Using Deep Reinforcement Learning to Enhance Channel Sampling Patterns in Integrated Sensing and Communication
Dec 04, 2024



In Integrated Sensing And Communication (ISAC) systems, estimating the micro-Doppler (mD) spectrogram of a target requires combining channel estimates retrieved from communication with ad-hoc sensing packets, which cope with the sparsity of the communication traffic. Hence, the mD quality depends on the transmission strategy of the sensing packets, which is still a challenging problem with no known solutions. In this letter, we design a deep Reinforcement Learning (RL) framework that fragments such a problem into a sequence of simpler decisions and takes advantage of the mD temporal evolution for maximizing the reconstruction performance. Our method is the first that learns sampling patterns to directly optimize the mD quality, enabling the adaptation of ISAC systems to variable communication traffic. We validate the proposed approach on a dataset of real channel measurements, reaching up to 40% higher mD reconstruction accuracy and several times lower computational complexity than state-of-the-art methods.
To Train or Not to Train: Balancing Efficiency and Training Cost in Deep Reinforcement Learning for Mobile Edge Computing
Nov 11, 2024



Artificial Intelligence (AI) is a key component of 6G networks, as it enables communication and computing services to adapt to end users' requirements and demand patterns. The management of Mobile Edge Computing (MEC) is a meaningful example of AI application: computational resources available at the network edge need to be carefully allocated to users, whose jobs may have different priorities and latency requirements. The research community has developed several AI algorithms to perform this resource allocation, but it has neglected a key aspect: learning is itself a computationally demanding task, and considering free training results in idealized conditions and performance in simulations. In this work, we consider a more realistic case in which the cost of learning is specifically accounted for, presenting a new algorithm to dynamically select when to train a Deep Reinforcement Learning (DRL) agent that allocates resources. Our method is highly general, as it can be directly applied to any scenario involving a training overhead, and it can approach the same performance as an ideal learning agent even under realistic training conditions.
Desynchronization Index: a New Approach for Exploring Complex Epileptogenic Networks in Stereoelectroencephalography
Aug 29, 2024Stereoelectroencephalography (SEEG) is an invasive surgical procedure to record the electrical activities in cortical brain regions, aiming at identifying the Epileptogenic Zone (EZ) in patients with drug-resistant epilepsy. To improve the accuracy of the EZ definition, SEEG analysis can be supported by computational tools, among which the Epileptogenic Index (EI) represents the most common solution. However, the scientific community has still not found an agreement on which quantitative biomarkers can characterize the cortical sites within the EZ. In this work, we design a new algorithm, named Desynchronization Index (DI), to assist neurophysiologists in SEEG interpretation. Our algorithm estimates the effective connectivity between cortical sites and hypothesizes that the EZ is identified by those sites getting abnormally desynchronized from the network during the seizure generation. We test the proposed method over a SEEG dataset of 10 seizures, comparing its accuracy in terms of EZ definition against the EI algorithm and clinical ground truth. Our results indicate that the DI algorithm underscores specific connectivity dynamics that can hardly be identified with a pure visual analysis, increasing sensitivity in detecting epileptogenic cortical sites.
Push- and Pull-based Effective Communication in Cyber-Physical Systems
Jan 15, 2024In Cyber Physical Systems (CPSs), two groups of actors interact toward the maximization of system performance: the sensors, observing and disseminating the system state, and the actuators, performing physical decisions based on the received information. While it is generally assumed that sensors periodically transmit updates, returning the feedback signal only when necessary, and consequently adapting the physical decisions to the communication policy, can significantly improve the efficiency of the system. In particular, the choice between push-based communication, in which updates are initiated autonomously by the sensors, and pull-based communication, in which they are requested by the actuators, is a key design step. In this work, we propose an analytical model for optimizing push- and pull-based communication in CPSs, observing that the policy optimality coincides with Value of Information (VoI) maximization. Our results also highlight that, despite providing a better optimal solution, implementable push-based communication strategies may underperform even in relatively simple scenarios.
Fast Context Adaptation in Cost-Aware Continual Learning
Jun 06, 2023In the past few years, DRL has become a valuable solution to automatically learn efficient resource management strategies in complex networks with time-varying statistics. However, the increased complexity of 5G and Beyond networks requires correspondingly more complex learning agents and the learning process itself might end up competing with users for communication and computational resources. This creates friction: on the one hand, the learning process needs resources to quickly convergence to an effective strategy; on the other hand, the learning process needs to be efficient, i.e., take as few resources as possible from the user's data plane, so as not to throttle users' QoS. In this paper, we investigate this trade-off and propose a dynamic strategy to balance the resources assigned to the data plane and those reserved for learning. With the proposed approach, a learning agent can quickly converge to an efficient resource allocation strategy and adapt to changes in the environment as for the CL paradigm, while minimizing the impact on the users' QoS. Simulation results show that the proposed method outperforms static allocation methods with minimal learning overhead, almost reaching the performance of an ideal out-of-band CL solution.
Multi-Agent Reinforcement Learning for Pragmatic Communication and Control
Feb 28, 2023The automation of factories and manufacturing processes has been accelerating over the past few years, boosted by the Industry 4.0 paradigm, including diverse scenarios with mobile, flexible agents. Efficient coordination between mobile robots requires reliable wireless transmission in highly dynamic environments, often with strict timing requirements. Goal-oriented communication is a possible solution for this problem: communication decisions should be optimized for the target control task, providing the information that is most relevant to decide which action to take. From the control perspective, networked control design takes the communication impairments into account in its optmization of physical actions. In this work, we propose a joint design that combines goal-oriented communication and networked control into a single optimization model, an extension of a multiagent POMDP which we call Cyber-Physical POMDP (CP-POMDP). The model is flexible enough to represent several swarm and cooperative scenarios, and we illustrate its potential with two simple reference scenarios with a single agent and a set of supporting sensors. Joint training of the communication and control systems can significantly improve the overall performance, particularly if communication is severely constrained, and can even lead to implicit coordination of communication actions.
Towards Decentralized Predictive Quality of Service in Next-Generation Vehicular Networks
Feb 22, 2023To ensure safety in teleoperated driving scenarios, communication between vehicles and remote drivers must satisfy strict latency and reliability requirements. In this context, Predictive Quality of Service (PQoS) was investigated as a tool to predict unanticipated degradation of the Quality of Service (QoS), and allow the network to react accordingly. In this work, we design a reinforcement learning (RL) agent to implement PQoS in vehicular networks. To do so, based on data gathered at the Radio Access Network (RAN) and/or the end vehicles, as well as QoS predictions, our framework is able to identify the optimal level of compression to send automotive data under low latency and reliability constraints. We consider different learning schemes, including centralized, fully-distributed, and federated learning. We demonstrate via ns-3 simulations that, while centralized learning generally outperforms any other solution, decentralized learning, and especially federated learning, offers a good trade-off between convergence time and reliability, with positive implications in terms of privacy and complexity.
Artificial Intelligence in Vehicular Wireless Networks: A Case Study Using ns-3
Mar 10, 2022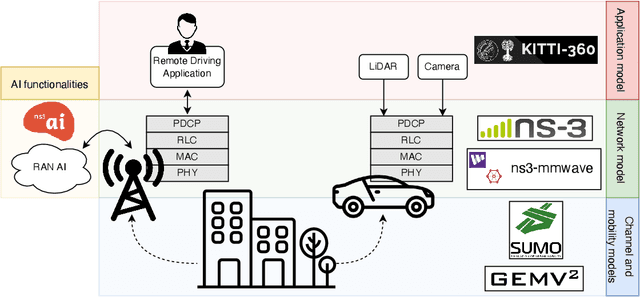
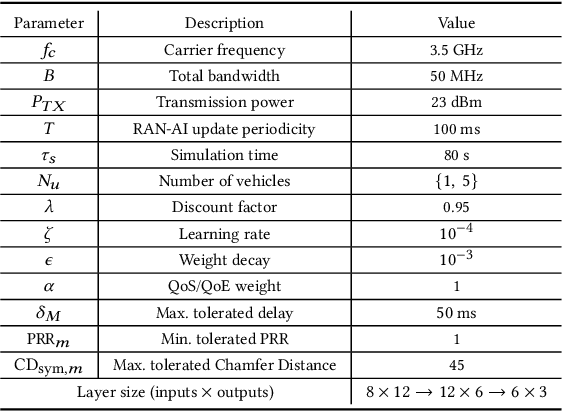
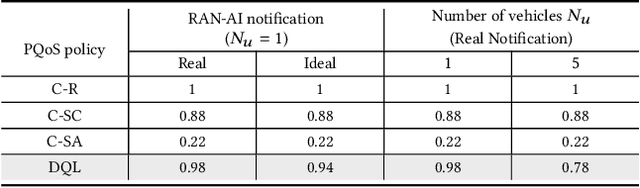
Artificial intelligence (AI) techniques have emerged as a powerful approach to make wireless networks more efficient and adaptable. In this paper we present an ns-3 simulation framework, able to implement AI algorithms for the optimization of wireless networks. Our pipeline consists of: (i) a new geometry-based mobility-dependent channel model for V2X; (ii) all the layers of a 5G-NR-compliant protocol stack, based on the ns3-mmwave module; (iii) a new application to simulate V2X data transmission, and (iv) a new intelligent entity for the control of the network via AI. Thanks to its flexible and modular design, researchers can use this tool to implement, train, and evaluate their own algorithms in a realistic and controlled environment. We test the behavior of our framework in a Predictive Quality of Service (PQoS) scenario, where AI functionalities are implemented using Reinforcement Learning (RL), and demonstrate that it promotes better network optimization compared to baseline solutions that do not implement AI.
A Reinforcement Learning Framework for PQoS in a Teleoperated Driving Scenario
Feb 04, 2022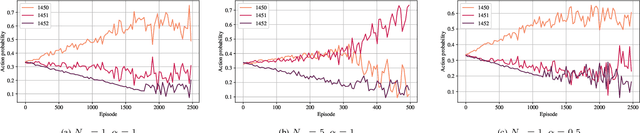
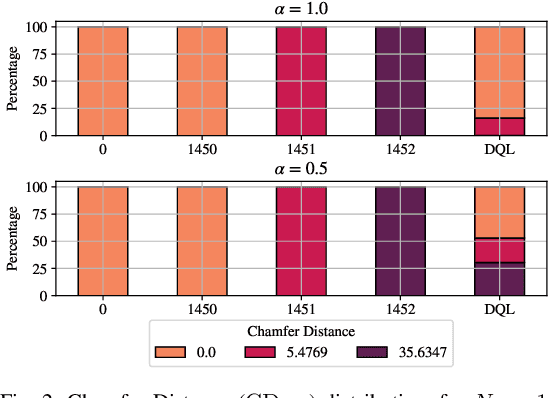
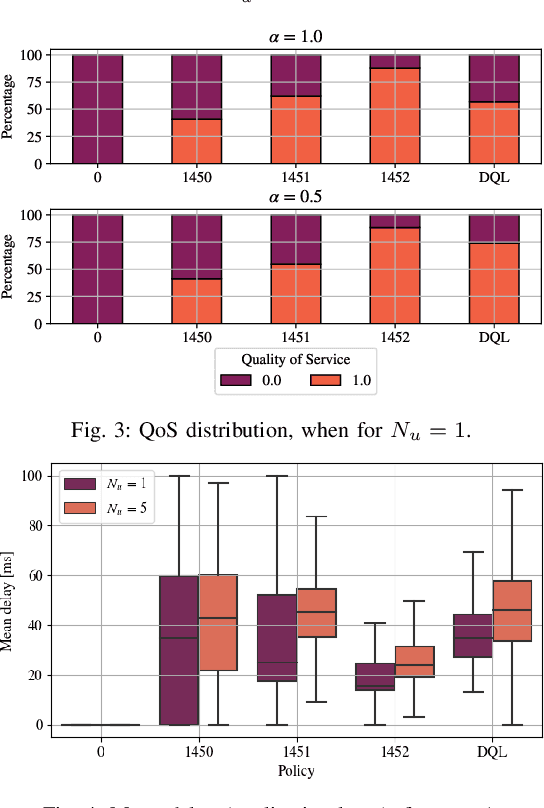
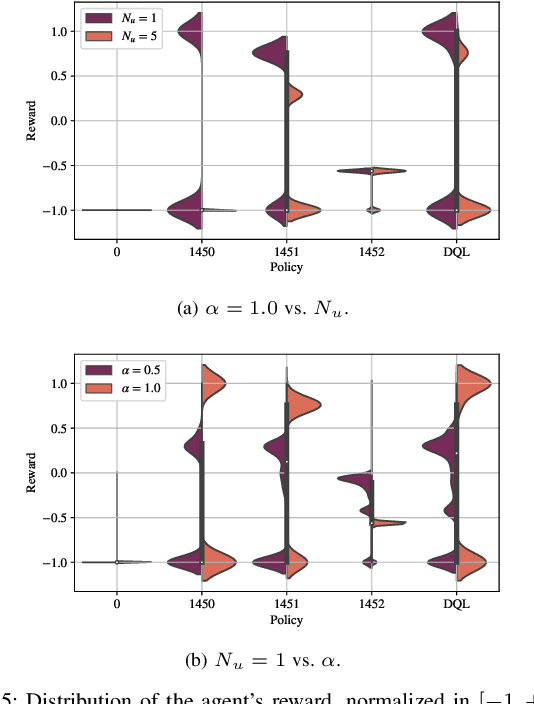
In recent years, autonomous networks have been designed with Predictive Quality of Service (PQoS) in mind, as a means for applications operating in the industrial and/or automotive sectors to predict unanticipated Quality of Service (QoS) changes and react accordingly. In this context, Reinforcement Learning (RL) has come out as a promising approach to perform accurate predictions, and optimize the efficiency and adaptability of wireless networks. Along these lines, in this paper we propose the design of a new entity, implemented at the RAN-level that, with the support of an RL framework, implements PQoS functionalities. Specifically, we focus on the design of the reward function of the learning agent, able to convert QoS estimates into appropriate countermeasures if QoS requirements are not satisfied. We demonstrate via ns-3 simulations that our approach achieves the best trade-off in terms of QoS and Quality of Experience (QoE) performance of end users in a teleoperated-driving-like scenario, compared to other baseline solutions.