 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Power Loss Identification through Physics-Based Thermal Model Backpropagation
Mar 31, 2025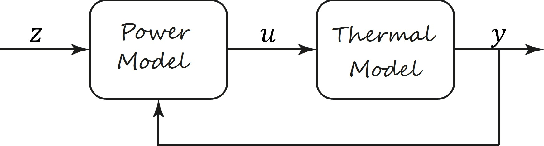
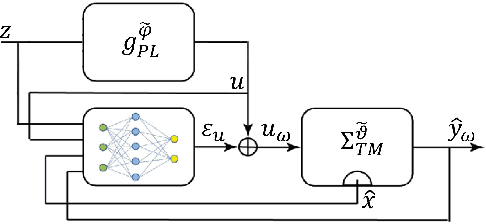
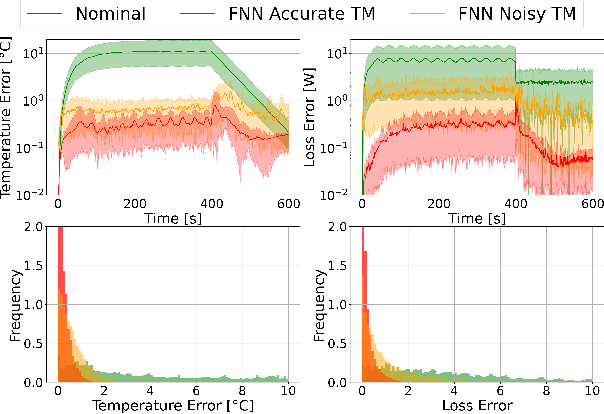
Digital twins for power electronics require accurate power losses whose direct measurements are often impractical or impossible in real-world applications. This paper presents a novel hybrid framework that combines physics-based thermal modeling with data-driven techniques to identify and correct power losses accurately using only temperature measurements. Our approach leverages a cascaded architecture where a neural network learns to correct the outputs of a nominal power loss model by backpropagating through a reduced-order thermal model. We explore two neural architectures, a bootstrapped feedforward network, and a recurrent neural network, demonstrating that the bootstrapped feedforward approach achieves superior performance while maintaining computational efficiency for real-time applications. Between the interconnection, we included normalization strategies and physics-guided training loss functions to preserve stability and ensure physical consistency. Experimental results show that our hybrid model reduces both temperature estimation errors (from 7.2+-6.8{\deg}C to 0.3+-0.3{\deg}C) and power loss prediction errors (from 5.4+-6.6W to 0.2+-0.3W) compared to traditional physics-based approaches, even in the presence of thermal model uncertainties. This methodology allows us to accurately estimate power losses without direct measurements, making it particularly helpful for real-time industrial applications where sensor placement is hindered by cost and physical limitations.
Effective Communication with Dynamic Feature Compression
Jan 29, 2024
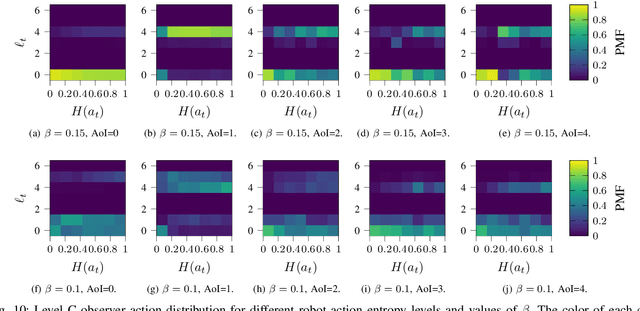
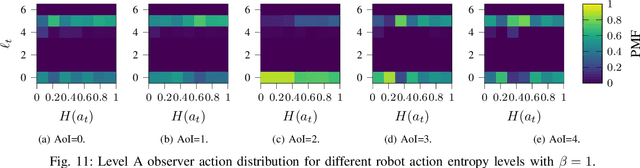

The remote wireless control of industrial systems is one of the major use cases for 5G and beyond systems: in these cases, the massive amounts of sensory information that need to be shared over the wireless medium may overload even high-capacity connections. Consequently, solving the effective communication problem by optimizing the transmission strategy to discard irrelevant information can provide a significant advantage, but is often a very complex task. In this work, we consider a prototypal system in which an observer must communicate its sensory data to a robot controlling a task (e.g., a mobile robot in a factory). We then model it as a remote Partially Observable Markov Decision Process (POMDP), considering the effect of adopting semantic and effective communication-oriented solutions on the overall system performance. We split the communication problem by considering an ensemble Vector Quantized Variational Autoencoder (VQ-VAE) encoding, and train a Deep Reinforcement Learning (DRL) agent to dynamically adapt the quantization level, considering both the current state of the environment and the memory of past messages. We tested the proposed approach on the well-known CartPole reference control problem, obtaining a significant performance increase over traditional approaches.
Communication-Efficient Federated Learning through Importance Sampling
Jun 25, 2023
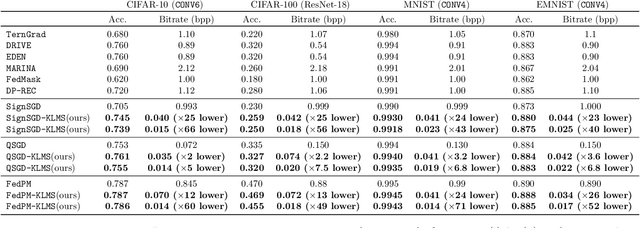
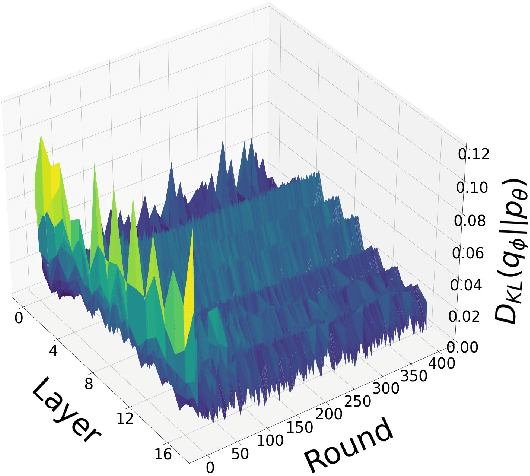
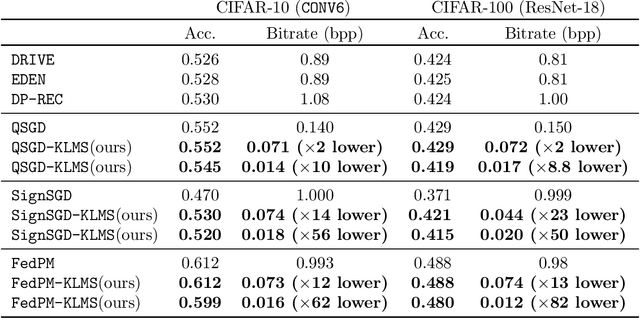
The high communication cost of sending model updates from the clients to the server is a significant bottleneck for scalable federated learning (FL). Among existing approaches, state-of-the-art bitrate-accuracy tradeoffs have been achieved using stochastic compression methods -- in which the client $n$ sends a sample from a client-only probability distribution $q_{\phi^{(n)}}$, and the server estimates the mean of the clients' distributions using these samples. However, such methods do not take full advantage of the FL setup where the server, throughout the training process, has side information in the form of a pre-data distribution $p_{\theta}$ that is close to the client's distribution $q_{\phi^{(n)}}$ in Kullback-Leibler (KL) divergence. In this work, we exploit this closeness between the clients' distributions $q_{\phi^{(n)}}$'s and the side information $p_{\theta}$ at the server, and propose a framework that requires approximately $D_{KL}(q_{\phi^{(n)}}|| p_{\theta})$ bits of communication. We show that our method can be integrated into many existing stochastic compression frameworks such as FedPM, Federated SGLD, and QSGD to attain the same (and often higher) test accuracy with up to $50$ times reduction in the bitrate.
Semantic Communication of Learnable Concepts
May 14, 2023
We consider the problem of communicating a sequence of concepts, i.e., unknown and potentially stochastic maps, which can be observed only through examples, i.e., the mapping rules are unknown. The transmitter applies a learning algorithm to the available examples, and extracts knowledge from the data by optimizing a probability distribution over a set of models, i.e., known functions, which can better describe the observed data, and so potentially the underlying concepts. The transmitter then needs to communicate the learned models to a remote receiver through a rate-limited channel, to allow the receiver to decode the models that can describe the underlying sampled concepts as accurately as possible in their semantic space. After motivating our analysis, we propose the formal problem of communicating concepts, and provide its rate-distortion characterization, pointing out its connection with the concepts of empirical and strong coordination in a network. We also provide a bound for the distortion-rate function.
Semantic and Effective Communication for Remote Control Tasks with Dynamic Feature Compression
Jan 14, 2023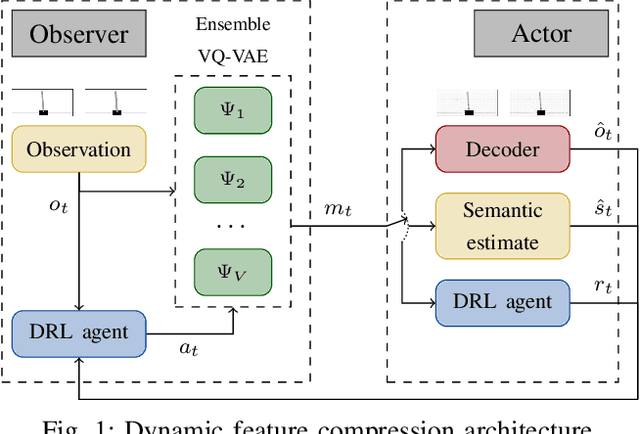
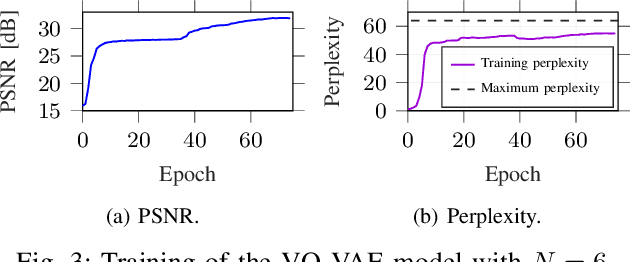
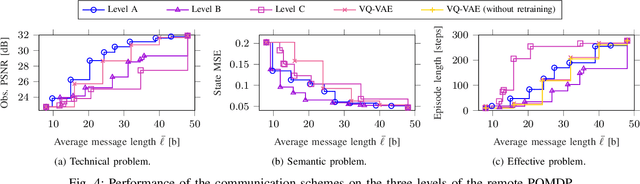
The coordination of robotic swarms and the remote wireless control of industrial systems are among the major use cases for 5G and beyond systems: in these cases, the massive amounts of sensory information that needs to be shared over the wireless medium can overload even high-capacity connections. Consequently, solving the effective communication problem by optimizing the transmission strategy to discard irrelevant information can provide a significant advantage, but is often a very complex task. In this work, we consider a prototypal system in which an observer must communicate its sensory data to an actor controlling a task (e.g., a mobile robot in a factory). We then model it as a remote Partially Observable Markov Decision Process (POMDP), considering the effect of adopting semantic and effective communication-oriented solutions on the overall system performance. We split the communication problem by considering an ensemble Vector Quantized Variational Autoencoder (VQ-VAE) encoding, and train a Deep Reinforcement Learning (DRL) agent to dynamically adapt the quantization level, considering both the current state of the environment and the memory of past messages. We tested the proposed approach on the well-known CartPole reference control problem, obtaining a significant performance increase over traditional approaches
Distributed Resource Allocation for URLLC in IIoT Scenarios: A Multi-Armed Bandit Approach
Nov 22, 2022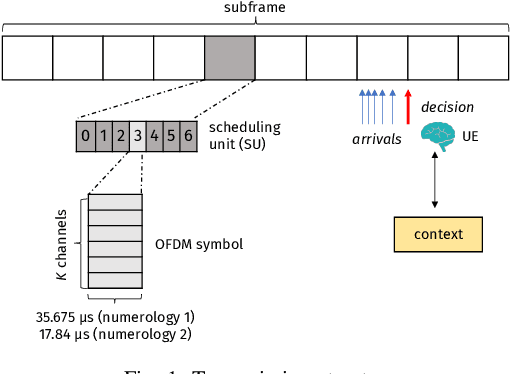
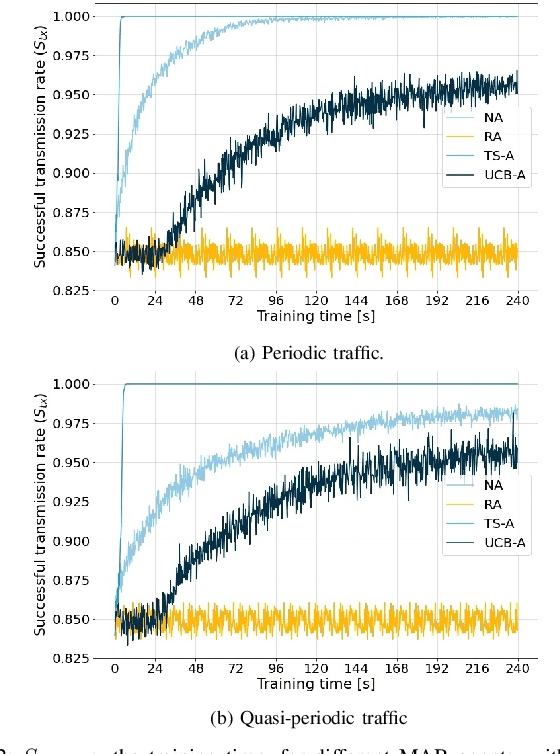
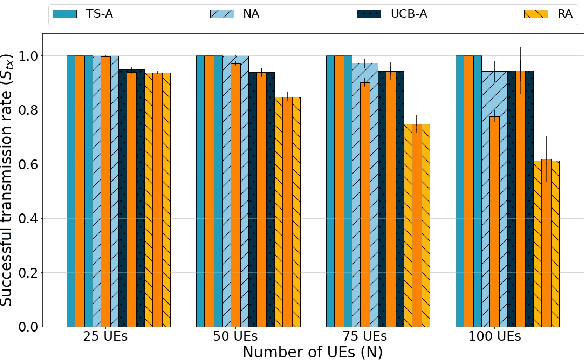
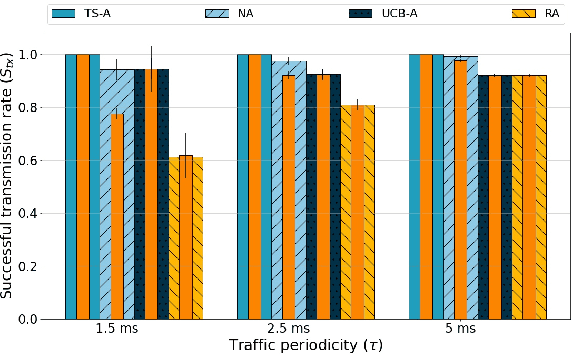
This paper addresses the problem of enabling inter-machine Ultra-Reliable Low-Latency Communication (URLLC) in future 6G Industrial Internet of Things (IIoT) networks. As far as the Radio Access Network (RAN) is concerned, centralized pre-configured resource allocation requires scheduling grants to be disseminated to the User Equipments (UEs) before uplink transmissions, which is not efficient for URLLC, especially in case of flexible/unpredictable traffic. To alleviate this burden, we study a distributed, user-centric scheme based on machine learning in which UEs autonomously select their uplink radio resources without the need to wait for scheduling grants or preconfiguration of connections. Using simulation, we demonstrate that a Multi-Armed Bandit (MAB) approach represents a desirable solution to allocate resources with URLLC in mind in an IIoT environment, in case of both periodic and aperiodic traffic, even considering highly populated networks and aggressive traffic.
Sparse Random Networks for Communication-Efficient Federated Learning
Sep 30, 2022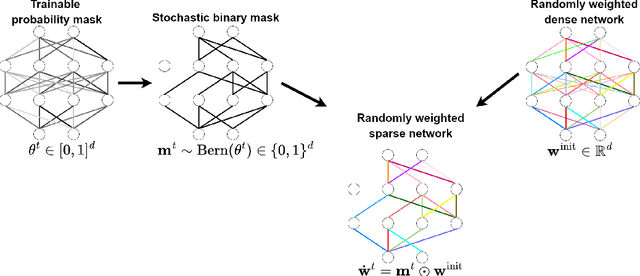
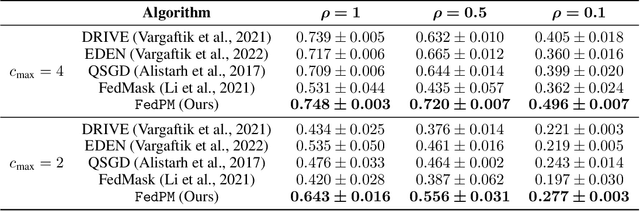
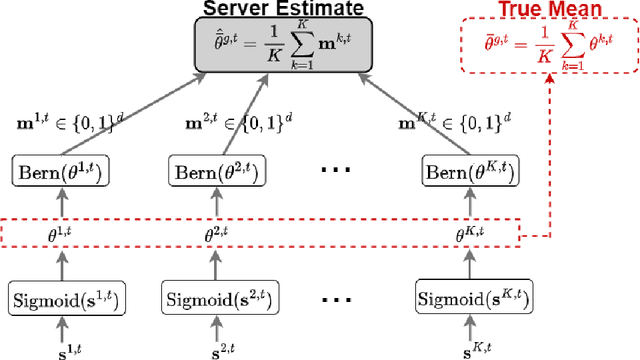
One main challenge in federated learning is the large communication cost of exchanging weight updates from clients to the server at each round. While prior work has made great progress in compressing the weight updates through gradient compression methods, we propose a radically different approach that does not update the weights at all. Instead, our method freezes the weights at their initial \emph{random} values and learns how to sparsify the random network for the best performance. To this end, the clients collaborate in training a \emph{stochastic} binary mask to find the optimal sparse random network within the original one. At the end of the training, the final model is a sparse network with random weights -- or a subnetwork inside the dense random network. We show improvements in accuracy, communication (less than $1$ bit per parameter (bpp)), convergence speed, and final model size (less than $1$ bpp) over relevant baselines on MNIST, EMNIST, CIFAR-10, and CIFAR-100 datasets, in the low bitrate regime under various system configurations.
Rate-Constrained Remote Contextual Bandits
Apr 26, 2022
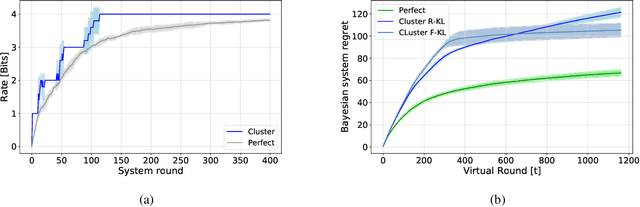
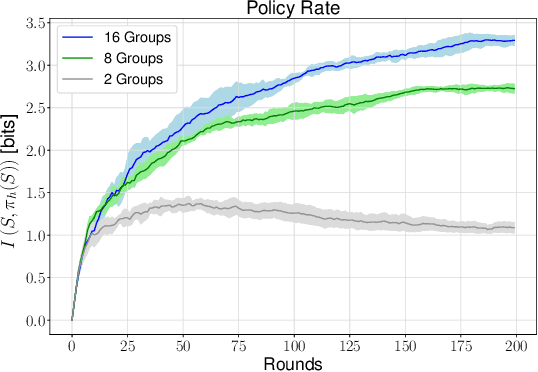
We consider a rate-constrained contextual multi-armed bandit (RC-CMAB) problem, in which a group of agents are solving the same contextual multi-armed bandit (CMAB) problem. However, the contexts are observed by a remotely connected entity, i.e., the decision-maker, that updates the policy to maximize the returned rewards, and communicates the arms to be sampled by the agents to a controller over a rate-limited communications channel. This framework can be applied to personalized ad placement, whenever the content owner observes the website visitors, and hence has the context, but needs to transmit the ads to be shown to a controller that is in charge of placing the marketing content. Consequently, the rate-constrained CMAB (RC-CMAB) problem requires the study of lossy compression schemes for the policy to be employed whenever the constraint on the channel rate does not allow the uncompressed transmission of the decision-maker's intentions. We characterize the fundamental information theoretic limits of this problem by letting the number of agents go to infinity, and study the regret that can be achieved, identifying the two distinct rate regions leading to linear and sub-linear regrets respectively. We then analyze the optimal compression scheme achievable in the limit with infinite agents, when using the forward and reverse KL divergence as distortion metric. Based on this, we also propose a practical coding scheme, and provide numerical results.
Remote Contextual Bandits
Feb 10, 2022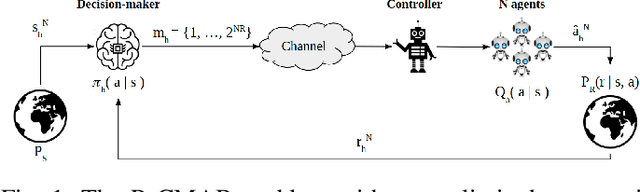
We consider a remote contextual multi-armed bandit (CMAB) problem, in which the decision-maker observes the context and the reward, but must communicate the actions to be taken by the agents over a rate-limited communication channel. This can model, for example, a personalized ad placement application, where the content owner observes the individual visitors to its website, and hence has the context information, but must convey the ads that must be shown to each visitor to a separate entity that manages the marketing content. In this remote CMAB (R-CMAB) problem, the constraint on the communication rate between the decision-maker and the agents imposes a trade-off between the number of bits sent per agent and the acquired average reward. We are particularly interested in characterizing the rate required to achieve sub-linear regret. Consequently, this can be considered as a policy compression problem, where the distortion metric is induced by the learning objectives. We first study the fundamental information theoretic limits of this problem by letting the number of agents go to infinity, and study the regret achieved when Thompson sampling strategy is adopted. In particular, we identify two distinct rate regions resulting in linear and sub-linear regret behavior, respectively. Then, we provide upper bounds on the achievable regret when the decision-maker can reliably transmit the policy without distortion.
On the Convergence Time of Federated Learning Over Wireless Networks Under Imperfect CSI
Apr 01, 2021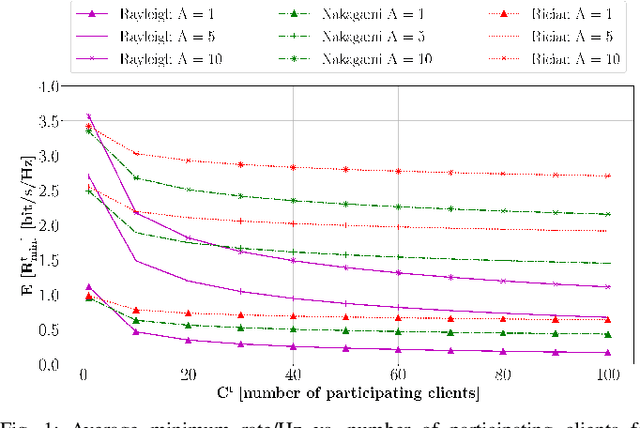
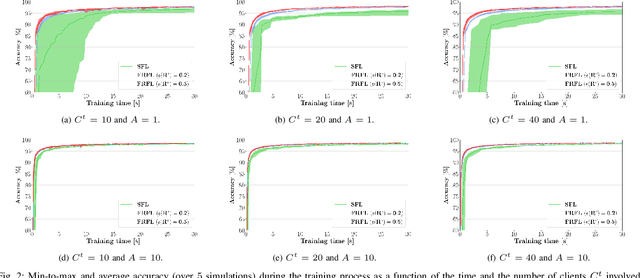
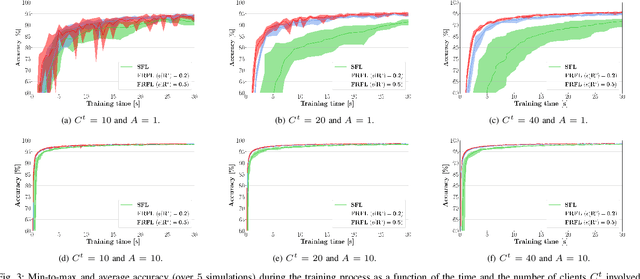
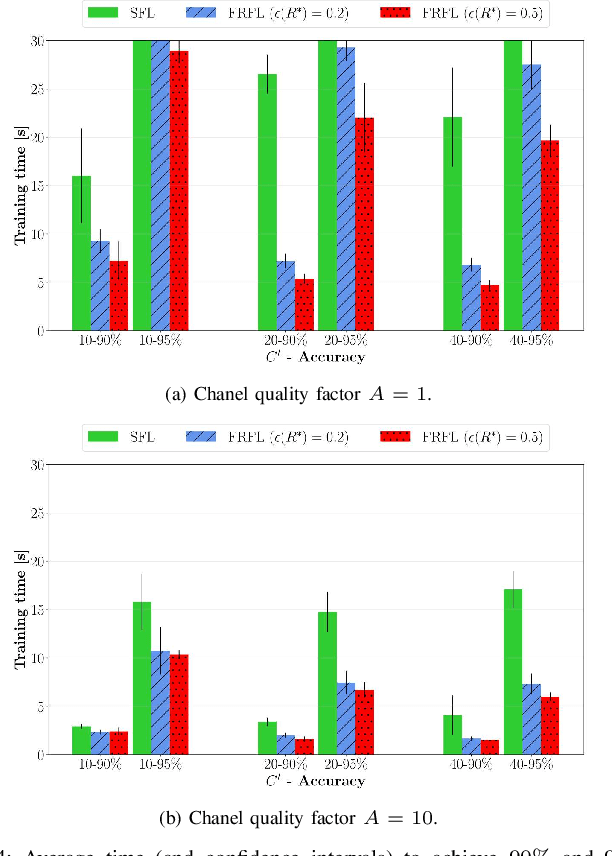
Federated learning (FL) has recently emerged as an attractive decentralized solution for wireless networks to collaboratively train a shared model while keeping data localized. As a general approach, existing FL methods tend to assume perfect knowledge of the Channel State Information (CSI) during the training phase, which may not be easy to acquire in case of fast fading channels. Moreover, literature analyses either consider a fixed number of clients participating in the training of the federated model, or simply assume that all clients operate at the maximum achievable rate to transmit model data. In this paper, we fill these gaps by proposing a training process that takes channel statistics as a bias to minimize the convergence time under imperfect CSI. Numerical experiments demonstrate that it is possible to reduce the training time by neglecting model updates from clients that cannot sustain a minimum predefined transmission rate. We also examine the trade-off between number of clients involved in the training process and model accuracy as a function of different fading regimes.