 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Random Networks for Communication-Efficient Federated Learning
Paper and Code
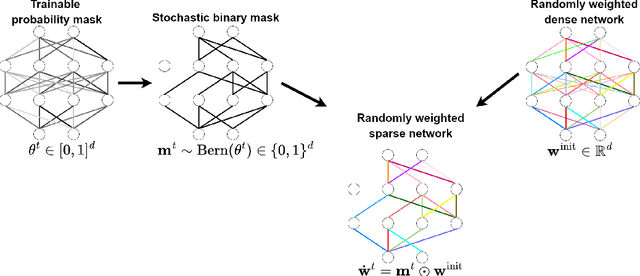
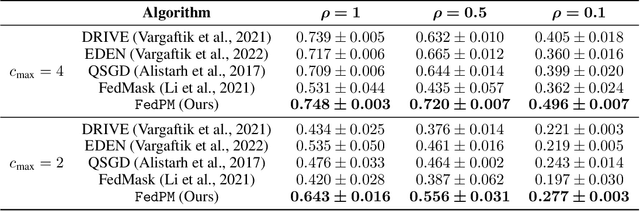
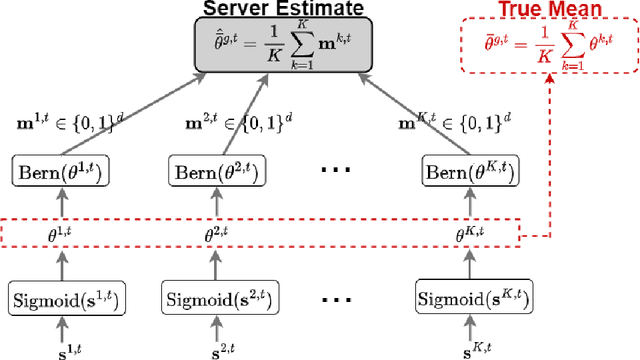
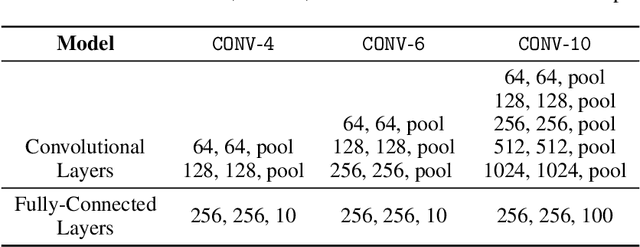
One main challenge in federated learning is the large communication cost of exchanging weight updates from clients to the server at each round. While prior work has made great progress in compressing the weight updates through gradient compression methods, we propose a radically different approach that does not update the weights at all. Instead, our method freezes the weights at their initial \emph{random} values and learns how to sparsify the random network for the best performance. To this end, the clients collaborate in training a \emph{stochastic} binary mask to find the optimal sparse random network within the original one. At the end of the training, the final model is a sparse network with random weights -- or a subnetwork inside the dense random network. We show improvements in accuracy, communication (less than $1$ bit per parameter (bpp)), convergence speed, and final model size (less than $1$ bpp) over relevant baselines on MNIST, EMNIST, CIFAR-10, and CIFAR-100 datasets, in the low bitrate regime under various system configurations.